
This post was authored by Karel Bartos, Vojtech Franc, & Michal Sofka.
Malware is constantly evolving and changing. One way to identify malware is by analyzing the communication that the malware performs on the network. Using machine learning, these traffic patterns can be utilized to identify malicious software. Machine learning faces two obstacles: obtaining a sufficient training set of malicious and normal traffic and retraining the system as malware evolves. This post will analyze an approach that overcomes these obstacles by developing a detector that utilizes domains (easily obtained from domain black lists, security reports, and sandboxing analysis) to train the system which can then be used to analyze more detailed proxy logs using statistical and machine learning techniques.
The network traffic analysis relies on extracting communication patterns from HTTP proxy logs (flows) that are distinctive for malware. Behavioral techniques compute features from the proxy log fields and build a detector that generalizes to the particular malware family exhibiting the targeted behavior.
The statistical features calculated from flows of malware samples are used to train a classifier of malicious traffic. This way, the classifier generalizes the information present in the flows and features and learns to recognize a malware behavior. We use features describing URL structures (such as URL length, decomposition, or character distribution), number of bytes transferred from server to client and vice versa, user agent, HTTP status, MIME type, port, etc. In our experimental evaluation, we used 305 features in total for each flow.
The first conceptual problem in using the standard supervised machine learning methods is the lack of sufficiently representative training set containing examples of malicious and legitimate communication. Providing security intelligence on individual proxy logs is expensive and does not scale with constantly evolving malware. The second problem is that the trained classifier is heavily dependent on the samples used in the training. Once a malware changes the behavior, the system needs to be retrained. With continuously rising number of malware variants, this becomes a major bottleneck in modern malware detection systems.
Both problems are addressed by considering groups of flows (also called bags). The bags are constructed for each user (or source IP) and contain all network communication with a particular hostname for a specific period of time.
Multiple Instance Learning
The robustness of the learned malicious flow detector directly depends on using a representative training set. Labeling individual flows in large quantities is difficult but the labels of domains can be easily obtained by leveraging internet domain black lists, security reports, and sandboxing analysis. Assigning labels based on the domains instead of the richer proxy logs with full target website URLs results in weak supervision in training: it is not known which flows in a positive bag are malicious and which are legitimate. The key advantage of this approach is that the requirements on the labeled samples (and their accuracy) are lower. This way, the system can train a detector that operates on individual proxy-logs while the training uses only domains to indicate malicious or legitimate traffic. Since the labeling is at the level of domains while the system trains a proxy log classifier, it can happen that some proxy logs in the positive bags (labeled positive based on the domain) can be negative (legitimate). The training algorithm correctly handles such cases.
The problem is formulated as weakly supervised learning since the bag labels are used to train a classifier of individual flows. We propose an algorithm based on the Multiple Instance Learning (MIL) that seeks for the Neyman-Pearson detector with a very low false positive rate that is necessary in the deployment of the system. The approach is illustrated in Figure 1.
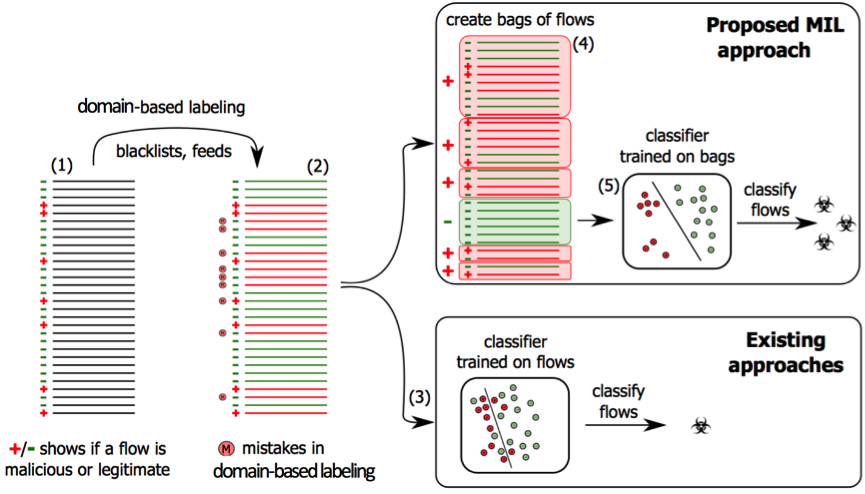
Learning of the Neyman-Pearson detector is formulated as an optimization problem with two terms: false negatives are minimized while choosing a detector with prescribed and guaranteed (very low) false positive rate. False negatives and false positives are approximated by empirical estimates computed from the weakly annotated data. The hypothesis space of the detector is composed of a linear decision rules parameterized by a weight vector and an offset. The described Neyman-Pearson learning is a modification of the Multi-Instance Support Vector Machines (mi-SVM) algorithm. The mi-SVM treats the flow labels as unobserved hidden variables subject to constraints defined by their bag labels. The goal is to maximize the instance margin jointly over the unknown instance labels and a linear discriminant function.
Our evaluation of the detectors uses datasets that represent 14 days of real network traffic of a large international company (80,000 seats). The MIL detector is compared to the SVM detector learned by considering all instances in the malicious bags to be positive and instances in the legitimate bags to be negative. The Figure 2 presents results obtained on the first 150 test flows with the highest decision score computed by both detectors. The flows were automatically selected from a dataset of 10M test flows.
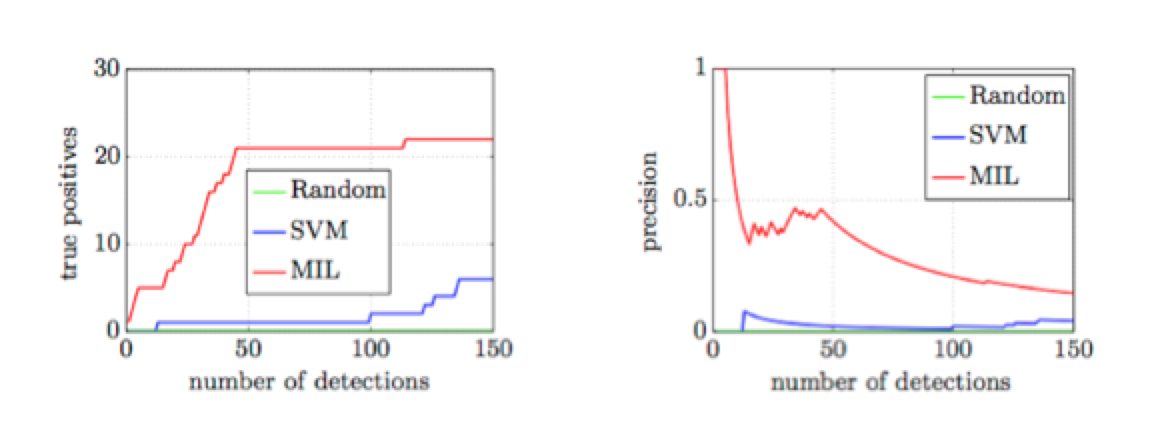
The MIL detector takes advantage of large databases of weak annotations (such as security feeds). Since the databases are updated frequently, the detectors are also retrained to maintain the highest accuracy. The training procedure relies on generic features and therefore generalizes the malware behavior from the training samples. As such the detectors find malicious traffic not present in the intelligence databases (marked by the feeds). The algorithm results in a general system that can recognize malicious traffic by learning from weak annotations.
Adapting to Malware Behavior Changes
Next, we focus on the problem of detecting variants of malicious behaviors. The detector uses a new representation of bags computed from sample feature values. The representation is designed to be invariant under shifting and scaling of the feature values and under permutation and size changes of the bags. In the context of malware, it means that any change in the number of flows of an attack (size invariance) or in the ordering of flows (permutation invariance) will not help evade the detection. Shift and scale invariance ensures that any internal variations of malware behavior as described by a predefined set of features will not change the representation. This means that new and unseen malware variants are represented with similar feature vectors as existing known malware, which greatly facilitates the detection of new or modified malicious behaviors. The ability to detect malware variants directly improves the system efficacy. The steps for creating the representation are described in Figure 3.
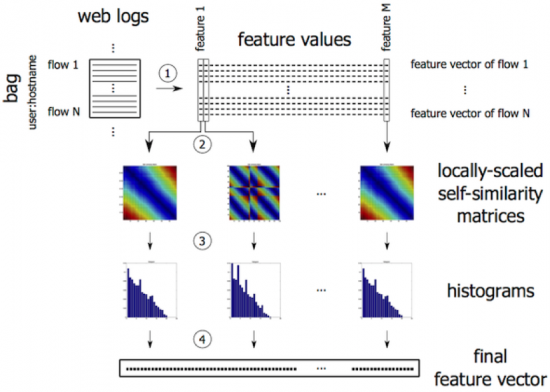
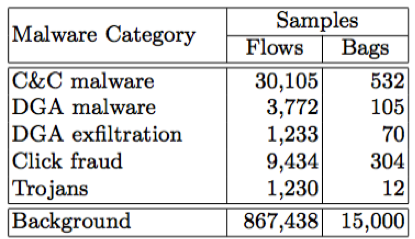
We have done experiments with datasets containing 5 malware categories: malware with command & control channels (marked as C&C), malware with domain generation algorithm (marked as DGA), DGA exfiltration, click fraud, and trojans. The rest of the background traffic is considered as legitimate. The number of flows and bags in each category is given in Table 1.
The effectiveness of self-similarity matrix capturing malware variations is shown by comparing the results to the case where the histograms are obtained directly from the flow-based feature values (i.e. without computing the self-similarity matrices). Two-class SVM classifier was trained using both representations. The training set consisted of click fraud positive bags and 5977 legitimate negative bags. The testing set consisted of bags from C&C and DGA malware, DGA exfiltration, trojans, and 8000 negative background bags. The results are summarized in Table 2 and compared flow level signature-based blocks in Figure 4.

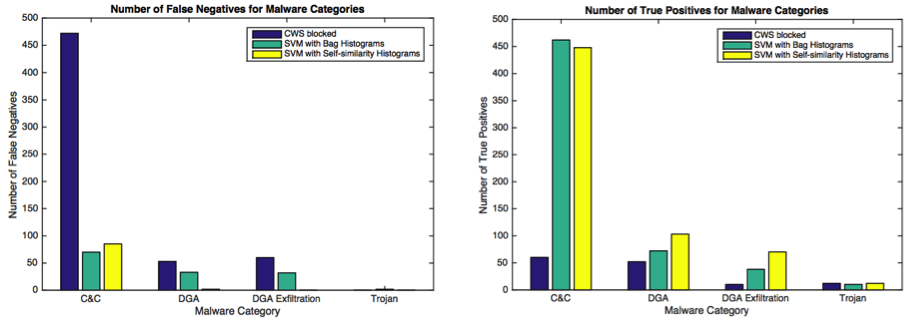
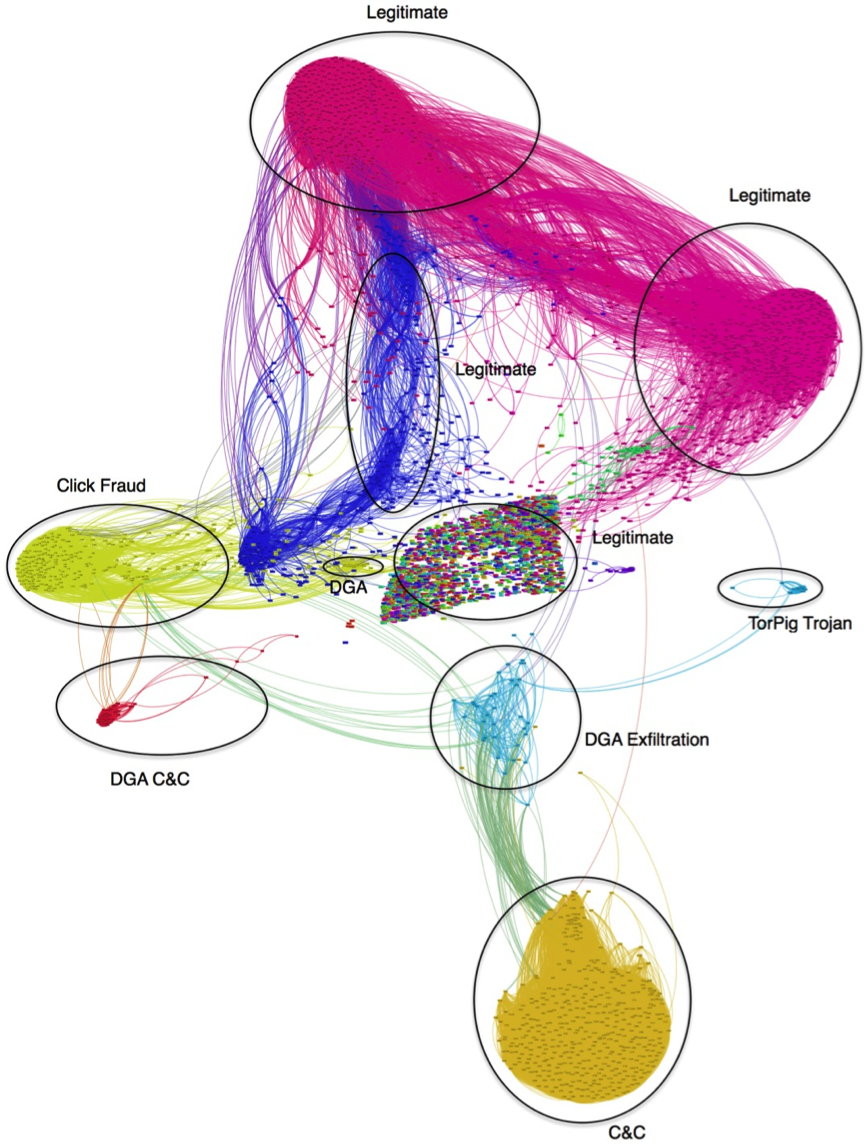
In the next experiment, the representation is used in a clustering to group malware belonging to the same category. This analysis shows how changing malware parameters influences similarity of samples, i.e. whether a modified malware sample is still considered to be similar to other malware samples of the same category. Two malware categories were included in the training set (click fraud and C&C) together with 5000 negative bags. The result is in Figure 5.
Conclusion
We have shown how to use bags of flows to represent communication of malware samples. The bags can be used to train a classifier of malicious flows by computing statistical feature vectors of the flows in a bag and labeling the bags by feeds and other security intelligence. This has the advantage that the labels of individual flows do not need to be provided which makes the labeling process tractable. The MIL algorithm used in the detector training minimizes a weighted sum of errors made by the detector on the negative and the positive bags. The trained flow-based classifier has better performance than a classifier trained from individual flows without forming the bags. The entire bags can also be classified by computing a new representation that leverages all flows in a bag to capture malware dynamics and behavior in time. The representation is robust to malware variations attempting to evade detection (e.g. by changing the URL pattern, number of transferred bytes, user agent, etc.). The invariant representation is based on the idea that malicious flows in a bag will have different statistical properties than legitimate flows in another bag. This richer information makes it possible to improve the efficacy of learning-based detectors.
The technology is integrated into Cisco CWS Premium product (Cognitive Threat Analytics). The work will be presented in more detail at the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), in Sep. 7-11, 2015. More reading can be found in the articles published in the conference proceedings:
Learning detector of malicious network traffic from weak labels, Vojtech Franc, Michal Sofka, and Karel Bartos, ECML 2015.
Robust representation of network traffic for detecting malware variations, Karel Bartos, and Michal Sofka, ECML 2015.






Amazing improvement from SVM.
Great post!
Another great result of the Cognitive Threat Analytics research team. Good job guys!
good info Great post!
Compelling approach. Can it be executed using existing Sourcefire / SNORT technical mechanisms or will other mechanisms be required?
Hi Bruce,
this approach comes from Cognitive Threat Analytics (CTA, see link), not from Talos/Snort group. The difference is that the breach detection systems work by performing statistical analysis on large volumes of data. This allows them to discover novel threats and threat categories that are difficult to spot using in-line IDS/IPS.
Compelling approach. Can it be implemented using existing Sourcefire / SNORT capabilities or will other mechanisms be required?
Exciting work. Is there any possibility to validate similar approaches on your dataset?