
It is no secret that cybersecurity defenders struggle to keep up with the volume and craftiness of current-day cyber-attacks. A significant reason for the struggle is that security infrastructure has yet to evolve to effectively and efficiently stymie modern attacks. The security infrastructure is either too unwieldy and slow or too destructive. When the security infrastructure is slow and unwieldy, the attackers have likely succeeded by the time the defenders react. When security actions are too drastic, they impair the protected IT systems to such an extent that the actions could be mistaken for the attack itself.
So, what does a defender do? The answer to the defender’s problem is a new security infrastructure — a fabric — that can autonomously create defenses and produce measured responses to detected attacks. Cisco has created such a fabric — Cisco Hypershield — that we discuss in the paragraphs below.
Foundational principles
We start with the foundational principles that guided the creation of Cisco Hypershield. These principles provide the primitives that enable defenders to escape the “damned-if-you-do and damned-if-you-don’t” situation we alluded to above.
Hyper-distributed enforcement
IT infrastructure in a modern enterprise spans privately run data centers (private cloud), public cloud, bring-your-own devices (BYOD) and the Internet of Things (IoT). In such a heterogeneous environment, centralized enforcement is inefficient as traffic must be shuttled to and from the enforcement point. The shuttling creates networking and security design challenges. The answer to this conundrum is the distribution of the enforcement point close to the workload.
Cisco Hypershield comes in multiple enforcement form factors to suit the heterogeneity in any IT environment:
- Tesseract Security Agent: Here, security software runs on the endpoint server and interacts with the processes and the operating system kernel using the extended Berkeley Packet Filter (eBPF). eBPF is a software framework on modern operating systems that enables programs in user space (in this case, the Tesseract Security Agent) to safely carry out enforcement and monitoring actions via the kernel.
- Virtual/Container Network Enforcement Point: Here, a software network enforcement point runs inside a virtual machine or container. Such enforcement points are instantiated close to the workload and protect fewer assets than the typical centralized firewall.
- Server DPUs: Cisco Hypershield’s architecture supports server Data Process Units (DPUs). Thus, in the future, enforcement can be placed on networking hardware close to the workloads by running a hardware-accelerated version of our network enforcement point in these DPUs. The DPUs offload networking and security processing from the server’s main CPU complex in a secure enclave.
- Smart Switches: Cisco Hypershield’s architecture also supports smart switches. In the future, enforcement will be placed in other Cisco Networking elements, such as top-of-rack smart switches. While not as close to the workload as agents or DPUs, such switches are much closer than a centralized firewall appliance.
Centralized security policy
The usual retort to distributed security enforcement is the nightmare of managing independent security policies per enforcement point. The cure for this problem is the centralization of security policy, which ensures that policy consistency is systematically enforced (see Figure 1).
Cisco Hypershield follows the path of policy centralization. No matter the form factor or location of the enforcement point, the policy being enforced is organized at a central location by Hypershield’s management console. When a new policy is created or an old one is updated, it is “compiled” and intelligently placed on the appropriate enforcement points. Security administrators always have an overview of the deployed policies, no matter the degree of distribution in the enforcement points. Policies are able to follow workloads as they move, for instance, from on-premises to the native public cloud.

Hitless enforcement point upgrade
The nature of security controls is such that they tend to get outdated quickly. Sometimes, this happens because a new software update has been released. Other times, new applications and business processes force a change in security policy. Traditionally, neither scenario has been accommodated well by enforcement points — both acts can be disruptive to the IT infrastructure and present a business risk that few security administrators want to undertake. A mechanism that makes software and policy updates normal and non-disruptive is called for!
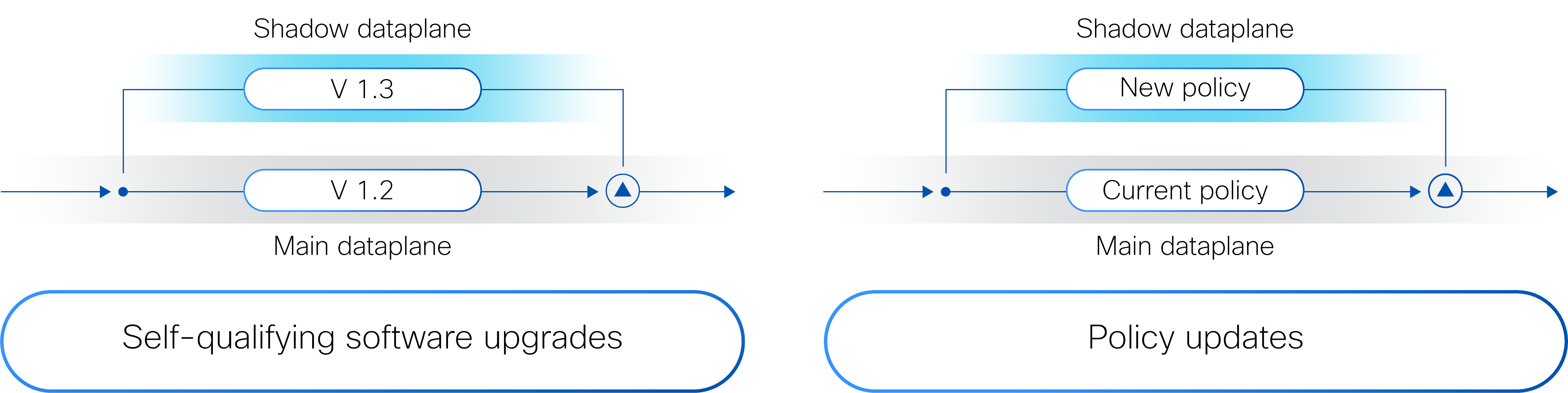
Cisco Hypershield has precisely such a mechanism, called the dual dataplane. This dataplane supports two data paths: a primary (main) and a secondary (shadow). Traffic is replicated between the primary and the secondary. Software updates are first applied to the secondary dataplane, and when fully vetted, the roles of the primary and secondary dataplanes are switched. Similarly, new security policies can be applied first to the secondary dataplane, and when everything looks good, the secondary becomes the primary.
The dual dataplane concept enables security administrators to upgrade enforcement points without fear of business disruption (see Figure 2).
Complete visibility into workload actions
Complete visibility into a workload’s actions enables the security infrastructure to establish a “fingerprint” for it. Such a fingerprint should include the types of network and file input-output (I/O) that the workload typically performs. When the workload takes an action that falls outside the fingerprint, the security infrastructure should flag it as an anomaly that requires further investigation.
Cisco Hypershield’s Tesseract Security Agent form factor provides complete visibility into a workload’s actions via eBPF, including network packets, file and other system calls and kernel functions. Of course, the agent alerts on anomalous activity when it sees it.
Graduated response to risky workload behavior
Security tools amplify the disruptive capacity of cyber-attacks when they take drastic action on a security alert. Examples of such action include quarantining a workload or the entire application from the network and shutting down the workload or application. For workloads of marginal business importance, drastic action may be fine. However, taking such action for mission-critical applications (for example, a supply chain application for a retailer) often defeats the business rationale for security tools. The disruptive action hurts even more when the security alert turns out to be a false alarm.
Cisco Hypershield in general, and its Tesseract Security Agent in particular, can generate a graduated response. For example, Cisco Hypershield can respond to anomalous traffic with an alert rather than a block when instructed. Similarly, the Tesseract Security Agent can react to a workload, attempting to write to a new file location with a denial rather than shutting down the workload.
Continuous learning from network traffic and workload behavior
Modern-day workloads use services provided by other workloads. These workloads also access many operating system resources such as network and file I/O. Further, applications are composed of multiple workloads. A human security administrator can’t collate all the applications’ activity and establish a baseline. Reestablishing the baseline is even more challenging when new workloads, applications and servers are added to the mix. With this backdrop, manually determining anomalous behavior is impossible. The security infrastructure needs to do this collation and sifting on its own.
Cisco Hypershield has components embedded into each enforcement point that continuously learn the network traffic and workload behavior. The enforcement points periodically aggregate their learning into a centralized repository. Separately, Cisco Hypershield sifts through the centralized repository to establish a baseline for network traffic and workloads’ behavior. Cisco Hypershield also continuously analyzes new data from the enforcement points as the data comes in to determine if recent network traffic and workload behavior is anomalous relative to the baseline.
Autonomous segmentation
Network segmentation has long been a mandated necessity in enterprise networks. Yet, even after decades of investment, many networks remain flat or under-segmented. Cisco Hypershield provides an elegant solution to these problems by combining the primitives mentioned above. The result is a network autonomously segmented under the security administrator’s supervision.
The autonomous segmentation journey proceeds as follows:
- The security administrator begins with top-level business requirements (such as isolating the production environment from the development environment) to deploy basic guardrail policies.
- After initial deployment, Cisco Hypershield collects, aggregates, and visualizes network traffic information while running in an “Allow by Default” mode of operation.
- Once there is sufficient confidence in the functions of the application, we move to “Allow but Alert by Default” and insert the known trusted behaviors of the application as Allow rules above this. The administrator continues to monitor the network traffic information collected by Cisco Hypershield. The monitoring leads to increased familiarity with traffic patterns and the creation of additional common-sense security policies at the administrator’s initiative.
- Even as the guardrail and common-sense policies are deployed, Cisco Hypershield continues learning the traffic patterns between workloads. As the learning matures, Hypershield makes better (and better) policy recommendations to the administrator.
This phased approach allows the administrator to build confidence in the recommendations over time. At the outset, the policies are deployed only to the shadow dataplane. Cisco Hypershield provides performance data on the new policies on the secondary and existing policies on the primary dataplane. If the behavior of the new policies is satisfactory, the administrator moves them in alert-only mode to the primary dataplane. The policies aren’t blocking anything yet, but the administrator can get familiar with the types of flows that would be blocked if they were in blocking mode. Finally, with conviction in the new policies, the administrator turns on blocking mode, progressing towards the enterprise’s segmentation goal.
The administrator’s faith in the security fabric — Cisco Hypershield — deepens after a few successful runs through the segmentation process. Now, the administrator can let the fabric do most of the work, from learning to monitoring to recommendations to deployment. Should there be an adverse business impact, the administrator knows that rollback to a previous set of policies can be accomplished easily via the dual dataplane.
Distributed exploit protection
Patching known vulnerabilities remains an intractable problem given the complex web of events — patch availability, patch compatibility, maintenance windows, testing cycles, and the like — that must transpire to remove the vulnerability. At the same time, new vulnerabilities continue to be discovered at a frenzied pace, and attackers continue to shrink the time between the public release of new vulnerability information and the first exploit. The result is that the attacker’s options towards a successful exploit increase with time.
Cisco Hypershield provides a neat solution to the problem of vulnerability patching. In addition to its built-in vulnerability management capabilities, Hypershield will integrate with Cisco’s and third-party commercial vulnerability management tools. When information on a new vulnerability becomes available, the vulnerability management capability and Hypershield coordinate to check for the vulnerability’s presence in the enterprise’s network.
If an application with a vulnerable workload is found, Cisco Hypershield can protect it from exploits. Cisco Hypershield already has visibility into the affected workload’s interaction with the operating system and the network. At the security administrator’s prompt, Hypershield suggests compensating controls. The controls are a combination of network security policies and operating system restrictions and derive from the learned steady-state behavior of the workload preceding the vulnerability disclosure.
The administrator installs both types of controls in alert-only mode. After a period of testing to build confidence in the controls, the operating system controls are moved to blocking mode. The network controls follow the same trajectory as those in autonomous segmentation. They are first installed on the shadow dataplane, then on the primary dataplane in alert-only mode, and finally converted to blocking mode. At that point, the vulnerable workload is protected from exploits.
During the process described above, the application and the workload continue functioning, and there is no downtime. Of course, the vulnerable workload should eventually be patched if possible. The security fabric enabled by Cisco Hypershield just happens to provide administrators with a robust yet precise tool to fend off exploits, giving the security team time to research and fix the root cause.
Conclusion
In both the examples discussed above, we see Cisco Hypershield function as an effective and efficient security fabric. The innovation powering this fabric is underscored by it launching with several patents pending.
In the case of autonomous segmentation, Hypershield turns flat and under-segmented networks into properly segmented ones. As Hypershield learns more about traffic patterns and security administrators become comfortable with its operations, the segments become tighter, posing more significant hurdles for would-be attackers.
In the case of distributed exploit protection, Hypershield automatically finds and recommends compensating controls. It also provides a smooth and low-risk path to deploying these controls. With the compensating controls in place, the attacker’s window of opportunity between the vulnerability’s disclosure and the software patching effort disappears.
Want to learn more about Cisco Hypershield? Watch the on-demand recording of our unveiling to hear from Jeetu Patel, Tom Gillis and Craig Connors. Or, check out Tom Gillis’ blog on Cisco Hypershield: A New Era of Distributed, AI-Native Security.

We’d love to hear what you think. Ask a Question, Comment Below, and Stay Connected with Cisco Secure on social!
Cisco Security Social Channels







Best and most concise write up of Hypershield I have yet to see! Thanks Craig. 🙂