
With the adoption of overlay networks as the standard deployment for multi-tenant network, Layer2 over Layer3 protocols have been the favorite among network engineers. One of the Layer2 over Layer3 (or Layer2 over UDP) protocols adopted by the industry is VXLAN. Now, as with any other overlay network protocol, its scalability is tied into how well it can handle the Broadcast, Unknown unicast and Multicast (BUM). That is where the evolution of VXLAN control plane comes into play.
The standard does not define a “standard” control plane for VXLAN. There are several drafts describing the use of different control planes. The most commonly use VXLAN control plane is multicast. It is implemented and supported by multiple vendors and it is even natively supported in server OS like the Linux Kernel.
This post tries to summarize the three (3) control planes currently supported by some of the Cisco NX-OS/IOS-XR. My focus is more towards the Nexus 7k, Nexus 9k, Nexus 1k and CSR1000v.
Each control plane may have a series of caveats in their own, but those are not covered by this blog entry. Let’s start with some VXLAN definitions:
(1) VXLAN Tunnel Endpoint (VTEP): Map tenants’ end devices to VXLAN segments. Used to perform VXLAN encapsulation/de-encapsulation.
(2) Virtual Network Identifier (VNI): identify a VXLAN segment. It hast up to 224 IDs theoretically giving us 16,777,216 segments. (Valid VNI values are from 4096 to 16777215). Each segment can transport 802.1q-encapsulated packets, theoretically giving us 212 or 4096 VLANs over a single VNI.
(3) Network Virtualization Endpoint or Network Virtualization Edge (NVE): overlay interface configured in Cisco devices to define a VTEP
VXLAN with Multicast Control Plane
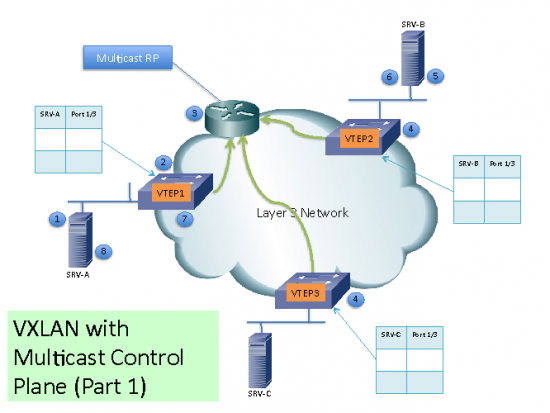
- When configuring VXLAN with multicast control plane:
- Every node configured with a VTEP for a VXLAN with certain VNI will join the same multicast group.
- Multicast configuration must support Any-Source Multicast (ASM)
Initially, the switch will only learn the Mac Addresses of devices directly connected to them.
Remote Mac Addresses are learn by a conversational Mac Address learning technique as follows (as per diagram):
(1) Lets say SRV-A want to talk to SRV-B. SRV-A will generate an ARP request trying to discover SRV-B Mac Address.
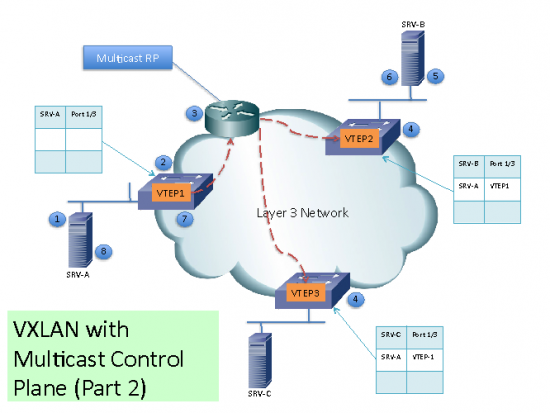
(2) When the ARP request arrives to SW1 it will lookup its local table and if an entry is not found, it will encapsulate the ARP request over VXLAN and send it over the Multicast group configured for the specific VNI.
(3) The multicast RP receive the packet and it will forward a copy to every VTEP that has joined the multicast group.
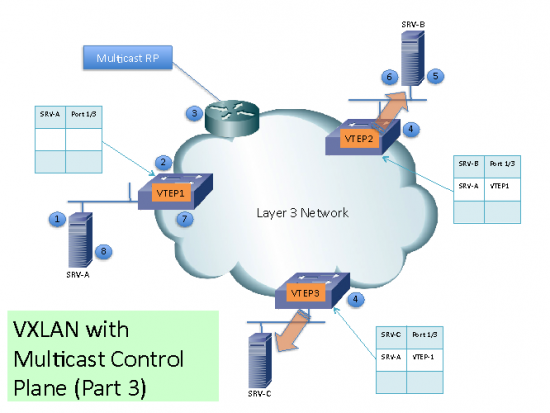
(4) Each VTEP will receive and de-encapsulate the packet VXLAN packet and learn SRV-A Mac Address pointing to the remote VTEP address.
(5) Each VTEP forwards the ARP request to its local destinations.
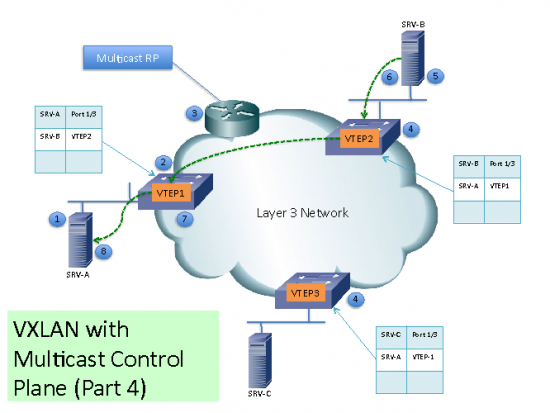
(6) SRV-B generates the ARP reply. When SW2 VTEP2 receives it, it will lookup its local table and will find and entry with the information that traffic destined to SRV-A must be sent to VTEP1 address. VTEP2 encapsulates the ARP reply with a VXLAN header and will unicast it to VTEP1.
(7) VTEP1 will receive and de-encapsulate the packet and deliver it to SRV-A
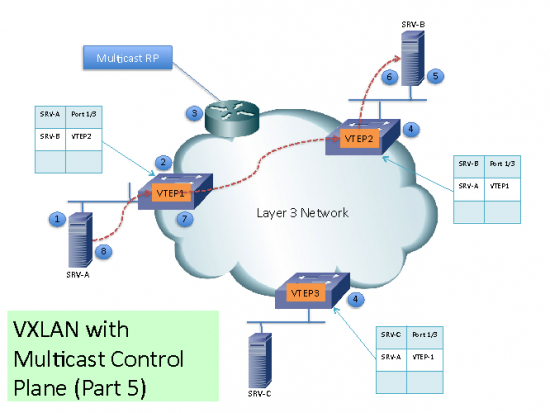
(8) Once the Mac Address information is learned, additional packets are Fed to the corresponding VTEP address.
VXLAN with Unicast Control Plane (Nexus 1000v)
The Nexus 1000v support three VXLAN unicast operation modes:
(1) Enhanced VXLAN (unicast mode): VEM replicates BUM traffic every VTEP in a particular VXLAN
(2) Enhanced VXLAN with MAC Distribution: MAC distribution done by VSM, unknown unicast dropped, ARP request replicated to every VTEP in a particular VXLAN
(3) Enhanced VXLAN with ARP Termination: MAC distribution done by VSM, unknown unicast dropped, ARP requests are handle locally at VEM
In this section, we will describe the third mode: Enhanced VXLAN with ARP Termination.
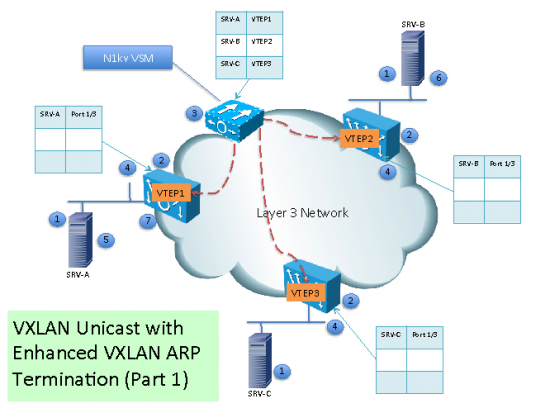
(1) When a new VM is instantiated in a VXLAN the hypervisor notifies the Virtual Ethernet Module (VEM).
(2) The VEM adds the VM MAC Address information to the VXLAN VTEP local table.
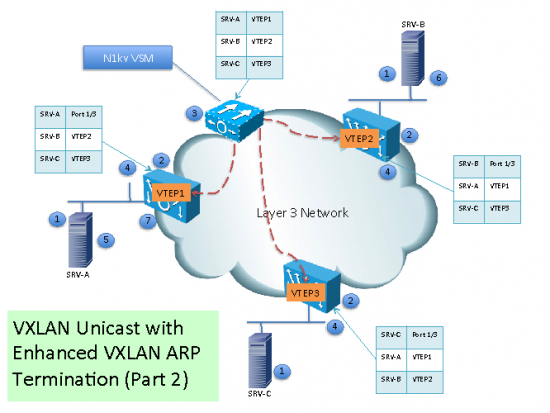
(3) The Virtual Supervisor Module (VSM) continuously aggregates the VXLAN VTEP local table information
(4) The VSM sends the mapping table to all VEMs with VTEPs in a particular VXLAN
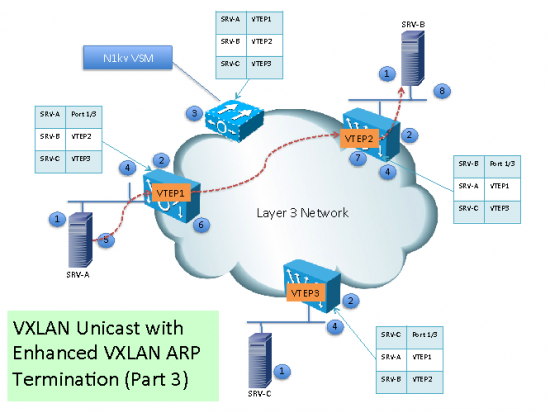
(5)When SRV-A sends ARP request looking for SRV-B, since the MAC Address information is in the local VEM table, the VEM will generate the ARP reply. The Nexus 1000v has the concept of a forwarding capable VTEPs and forwarding incapable VTEPs. If the destination MAC is not in the table, the ARP request will only be forwarded to the forwarding-incapable VTEPs.
Sending the packet to the forwarding-incapable VTEPs is important for integration of bare-metal workloads via the layer-2 VXLAN gateway sitting on a ToR for example. This is also necessary for routing cases when traffic is going from a VM in one subnet to a host in another subnet which has to traverse the Layer-2 VXLAN gateway which may be virtual or physical.
(6) Traffic from SRV-A destined to SRV-B will be encapsulated by VTEP1 and unicasted to VTEP2.
(7) VTEP2 de-encapsulate the packet the locally deliver it.
(8) SRV-B receives the original Ethernet packet.
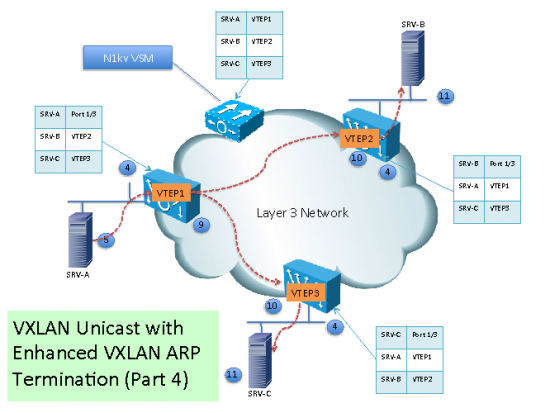
(9) If SRV-A sends multicast or broadcast, then, the VEM replicate its and send a copy to each VEM with a VTEP on that particular VXLAN.
(10) The remote VEM receive the multicast or broadcast packets and send a copy to each local destination part of the particular VXLAN.
VXLAN with MP-BGP EVPN
The MP-BGP EVPN address family defined the control-plane for Ethernet VPNs. For data plane it supports:
(1) Multiprotocol Label Switching (MPLS) for E-LAN services with VPWS, RSVP-TE or LDP
(2) Provider Backbone Bridges (PBB) for PBB-VPLS
(3) Network Virtualization Overlays (NVO3) for Layer 2 and Layer 3 DCI with VXLAN, NVGRE or MPLSoGRE
In this section we will focus in MP-BGP EVPN with VXLAN data plane.
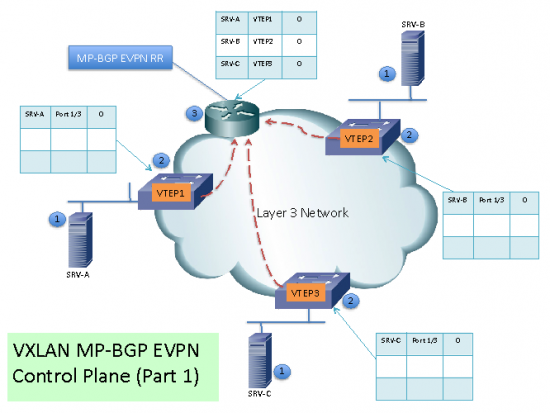
(1) Each VXLAN edge (from now on PE) will become a MP-BGP RR Client. Each PE will learn local MAC Addresses associated to its VXLANs. Each entry will have a version number, for this example we are using version 0 as the initial version of each entry.
(2) The PE then sends the MAC Address routing information to the MP-BGP EVPN RR.
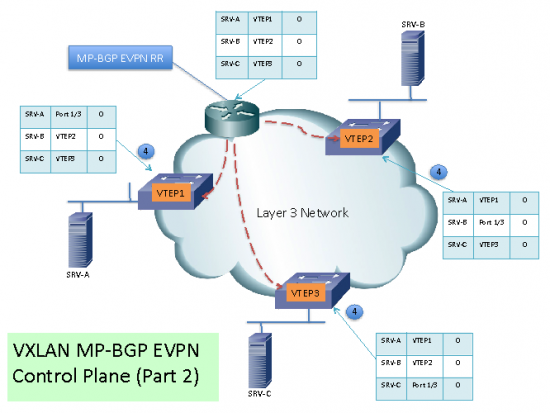
(3) Just like with regular BGP RR, the MP-BGP EVPN RR will send that information to the PE’s.
(4) The PE’s will receive the MAC Address routing table and will have knowledge of the VTEPs for destinations in a particular VXLAN.
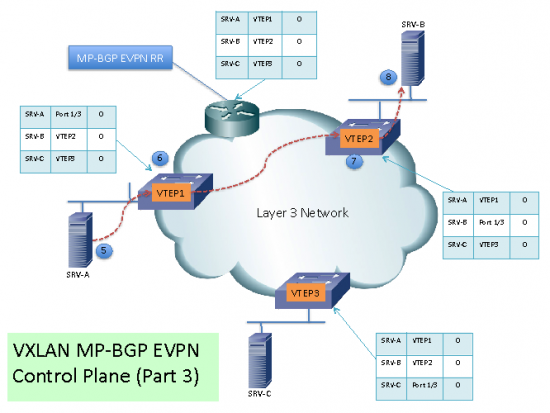
(5) When SRV-A sends an ARP request looking for SRV-B, the local PE will generate the ARP reply, avoiding flooding or broadcasts.
(6) Traffic from SRV-A to SRV-B will found the destination VTEP in its local table and will unicast the traffic to VTEP2.
7) VTEP2 receives the packets and de-encapsulates them.
(8) The original Ethernet packet arrives to SRV-B. The same process happens with traffic from SRV-B to SRV-A.
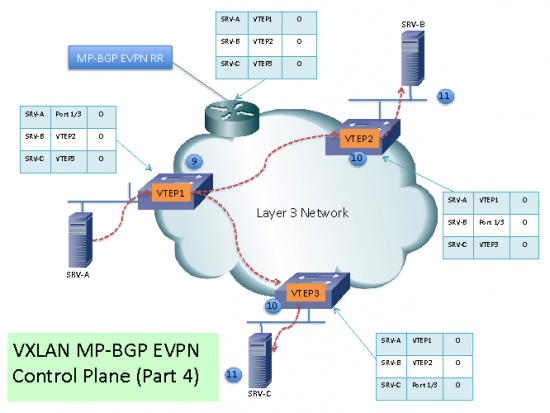
(9) If there is multicast or broadcast traffic from SRV-A, the PE sends a copy to each VTEP part of the same VXLAN. (I haven’t found a clear explanation for the behavior for multicast and broadcast traffic. This is one of them. Another technique is for each VXLAN network to build a multicast-forwarding tree to handle multicast for one or more VNIs.)
(10) The remote VTEP receives and de-encapsulates the packets.
(11) The multicast or broadcast packet is delivered to the servers in the same VXLAN segment.
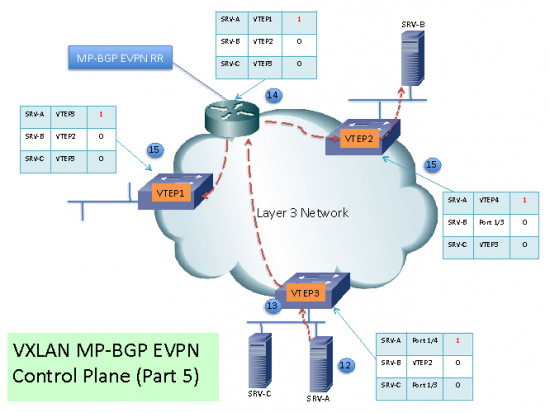
(12) If a server is migrated to another PE, once it generates a packet (i.e. ARP request) it will be detected by the new local PE.
(13) The PE will find an entry in its local table and update it with a higher version number.
(14) The new route is sent to the RR where it is updated and “reflected” to the PE RR Clients.
(15) The PE RR Clients update their table now with the updated VTEP destination of SRV-A
VXLAN: a protocol in evolution
This blog tries to summarize the VXLAN control planes currently supported in some of the Cisco Data Center products. Keep in mind that VXLAN is a protocol in the making. It is a protocol evolving. There are many drafts around this protocol to keep an eye. Some of the IETF working groups working with these and some of the drafts:
- Network Virtualization Overlays (nvo3): http://datatracker.ietf.org/wg/nvo0/documents/
- Layer 2 Virtual Private networks: http://tools.ietf.org/wg/l2vpn/
- Virtual eXtensible Local Area Networks (VXLAN) RFC 7348: http://www.rfc-editor.org/rfc/rfc7348.txt
- VXLAN DCI Using EVPN: draft-boutros-l2vpn-vxlan-evpn-04: http://www.ietf.org/archive/id/draft-boutros-l2vpn-vxlan-evpn-04.txt






this is good post
Good summary! Thanks for sharing.