
Imagine you’ve been asked to create an architecture that can apply analytics on very voluminous data such as video streams generated from cameras. Given the volume and sensitivity of the data, you don’t want to send it off-premises for analysis. Also, the anticipated cost of centralizing the data might invalidate your business value assessment for your use case. You could apply machine learning (ML) or artificial intelligence (AI) at the edge—but only if you can make it work with the available compute resources.
This is the exact challenge I recently tackled with the help of my colleague, Michael Wielpuetz.
It’s not always easy or even possible to change or scale the available compute resources in a typical edge scenario. A ML- or AI-enabled software stack consists of libraries, frameworks, and trained analytical models. In relation to the available resources at the network edge, the frameworks and the models tend to be large in size. Additionally, such setups often require multiple CPU-, or even GPU-enabled environments during operation.
To provide food for thought, to incubate new ideas, and to proof possibility, Michael Wielpuetz and I started in our free time to minimize the resource requirement of an exemplary setup. We thought about a use case that relates to a current public challenge: detect human faces on a video stream and whether those faces are covered with a protection mask.
We decided to create a base Docker image that allows us to host two stacked neural networks: The first neural network to detect all faces in a video stream, and the second neural network to detect masks on the faces found. To minimize the container, as well as to have it available across x86_64 and ARM64 architectures, we compiled, cross-compiled, and minimized the footprint of all components from gigabyte to megabyte size. To allow using one of the smallest possible AI frameworks, we transformed, quantized, and stripped the trained models. We decided to invest the extra effort for optimizing the frameworks and libraries because when we started there was no ready-to-use installable package available for the most recent versions of the components.
See how the standard Docker images compare to our base image:
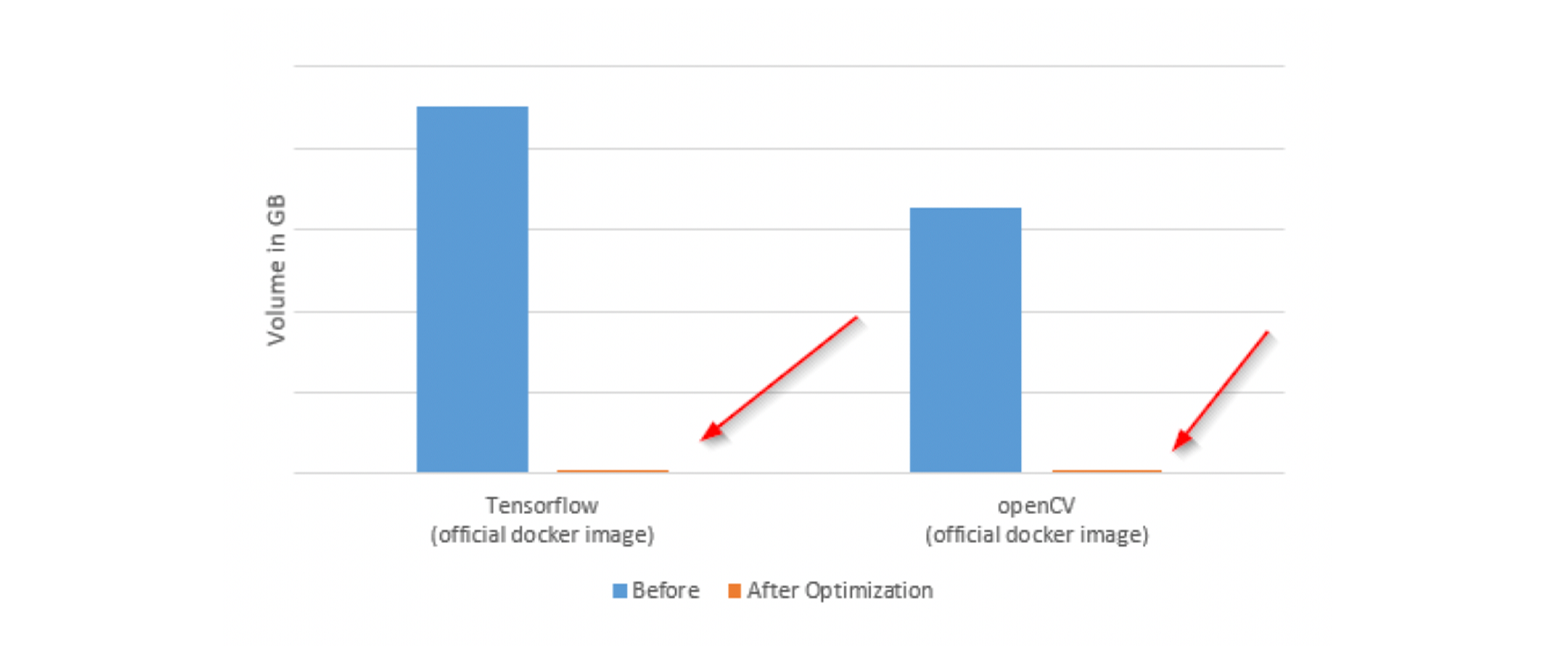
The final size of our image on ARM64 is 184MB, and there is still potential for further optimization.
Both neural networks are embedded into an application that allows dynamic configuration, such as configuring the video stream to be used, defining the resolution and the sampling rate, and more. These settings have a major impact on the throughput and data availability latency of the setup.
On the systems we tested, the throughput was up to five frames per second at a resolution of 720p with only a part of the available resources made available to the Docker container to allow for multiple containers to be hosted at the same time. The optimal setting and required throughput depend on the use case requirements. Many of the use cases we thought of are perfectly fine with one frame per second or even less.
The internal architecture of the Docker container is as follows:
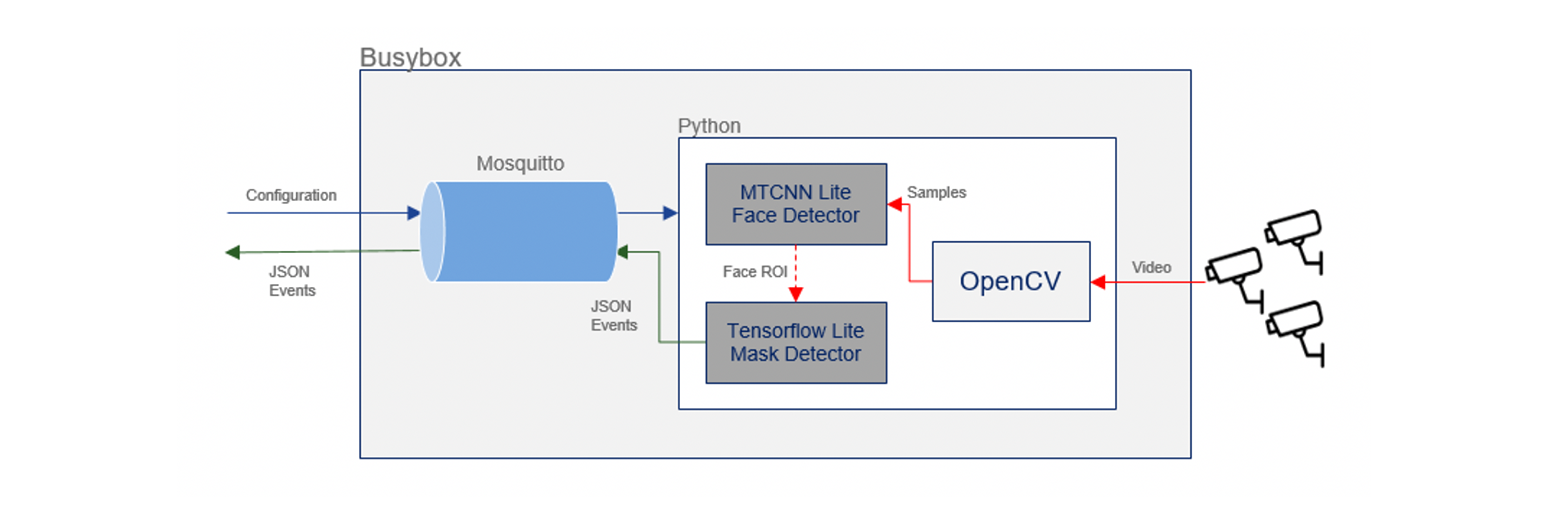
Since the base Docker image works with configurable video streams, it’s easy to think of additional use cases. It becomes an exercise of replacing or retraining the model to cover other scenarios based on video streams to enable use cases like detecting room occupation, people counting, threat detection, object detection and many more.
Here is an example of the setup in action. The video will show you:
- in the first segment, the dynamically anonymized faces are detected
- in the second segment, a visual representation of the analytical result, including the face location, the facial features, as well as the probability that the person is wearing a mask
- in the third segment, the original input video stream with a visualization of the detections
- in the fourth segment, the output of the setup
The fourth segment is exactly what this setup will provide to external consumers. To maintain privacy, the setup will not send video or image data outbound.
There is still room for optimizing the accuracy of the analytical results. For this first setup, we intentionally set our focus on the proof of possibility and resource allocation reduction of performing ML and AI at the edge, rather than creating a ready-to-use product.
We plan on creating a handful of other examples based on video, then we’ll turn our focus to machine telemetry and how we can use this approach on high dimensional data. Our plan is to continue to release different Docker images for different use cases to help others getting started with ML and AI at the edge.




Hi Daniel, hi Michael
Your solution sounds interesting, have you planned to implement it on the DevNet Sandbox environment.
(https://developer.cisco.com/site/sandbox/)
Either way, I look forward to the further development (thumbs up).
I am talking to DevNet about that. It sounds like a good idea to provide wider access to it for testing purposes.
nice information keep it up
Great !
Thanks for providing in-depth knowledge of the IoT technology. I look forward to seeing many more inspiring articles by you.
Stay tuned! 🙂
Really interesting to see the difference that can be achieved by optimizing the image! Good work!