
Keeping your IT infrastructure operational
Before I get into data models, I want to take a slight diversion to incorporate some of the feedback that I received from the first blog. It was pointed out that my use of the ios_config module was “naïve.” I contend that it is more accurate to say that my use of Ansible in general was “naïve,” since this was a pretty straight forward use of the module. In any case, it was by design. Why? Well, if you are like the majority of the network operators that I’ve worked with over the years, you are not a programmer (or you are a “naïve” programmer). You spend 110% of your time busting your chops making sure that the network that underpins your company’s IT infrastructure is operational. I certainly do not want to discourage network operators going to classes, workshops, etc. to learn new skills if they have the time and the motivation, but it should not be necessary to consume network automation. We can do better!
The NTP example that I used in the first blog was also chosen for specific reasons. First, NTP and AAA were the questions that I got most from customers on this issue. They were able to configure these things initially, but ran into problems when they moved to an operational posture. Second, it is representative of the “naïve” approach that you’ll see in the examples and workshops that are being delivered in the Ansible network automation genre. These “naive” examples and workshops perpetuate the first reason. Lastly, there is no way to use the ios_config module, the most used Ansible module for Cisco IOS, to fix this. Nor is the issue addressed by an NTP-specific Ansible network module. Yes, there might be some other module in some git repo written by someone that addresses your corner case, but do you want to use it? Is writing a module for every single corner case for network automation a scalable approach? I say no. Partially because it is intractable, partially because it is a support nightmare.
Where do you get help for the modules that underpin the automation?
Red Hat supports a specific set of modules (generally the ones they write), other vendors support their modules, other modules are completely unsupported. Where do you get help for the modules that underpin the automation that makes your network work? Incidentally, we’ll cover a technique to augment the ios_config module with a parser to address this problem in a later blog, but it is not intuitively obvious to the casual observer.
I believe that we need to focus on a smaller number of more capable modules and couple that with a more sophisticated, or more realistic, approach to network automation. Subsequent blogs will focus on different aspects of this more realistic approach, but this one will start with the biggest: Data Models.
So, what is a data model?
I know what you are thinking: “Wait a minute! I didn’t need data models for automating my servers!” Well, building a system is a well-defined procedure with relatively few permutations or interdependencies on other systems. Also, provisioning a system generally consists of configuring values like hostname, IPs, DNS, AAA, and packages. Each of these are key/value pairs (e.g. nameservers = 8.8.8.8, 8.8.4.4) that define the operation of that system and there are relatively few of them for a system.
This is not the case for a network element. If we take a standard 48-port Top-of-Rack Switch, each port could have a description, a state, a VLAN, an MTU, etc. A single ToR could have hundreds of key/value pairs that dictate its operation. Multiply that across hundreds or even thousands of switches, and the number of key/value pairs grows rapidly. Collectively, all of these key/value pairs make up the Source of Truth (SoT) of your network and there can be a lot of them. In fact, automating networks is really more of a data management and manipulation problem than it is a programming problem.
So, what is a data model? Generally speaking, a data model is a structure in which the meaning of a key/value pair is defined by its relative position in that structure. As an example, let’s start with the de-facto standard in the networking space: YANG. According to RFC 7950, “YANG is a data modeling language used to model configuration data, state data, Remote Procedure Calls, and notifications for network management protocols.”
If we look at the way we setup a simple BGP peering on Cisco IOS and Juniper JunOS, we basically have a bunch of values accompanied by a bunch of words using a particular grammar that describe those values:
 But the values, two ASNs and an IP address, are the only things that really matter and they are the same in each.
But the values, two ASNs and an IP address, are the only things that really matter and they are the same in each.
 In fact, the switch hardware does not care about the words that describe those values since they get stored in a config DB anyway. The words are what the engineers gave to the humans to communicate the meaning of those values to the hardware. After all, we can’t just specify 2 ASNs because we need to know which is the local and which is the remote. We could, however, communicate their meaning by order: e.g. <Local ASN>, <Peer ASN>, <Peer IP>. This is basically a small data model. Well, BGP gets A LOT more complicated, so we’ll need a more capable data model. Here we have an example of the same data in the OpenConfig data model rendered in YAML:
In fact, the switch hardware does not care about the words that describe those values since they get stored in a config DB anyway. The words are what the engineers gave to the humans to communicate the meaning of those values to the hardware. After all, we can’t just specify 2 ASNs because we need to know which is the local and which is the remote. We could, however, communicate their meaning by order: e.g. <Local ASN>, <Peer ASN>, <Peer IP>. This is basically a small data model. Well, BGP gets A LOT more complicated, so we’ll need a more capable data model. Here we have an example of the same data in the OpenConfig data model rendered in YAML:
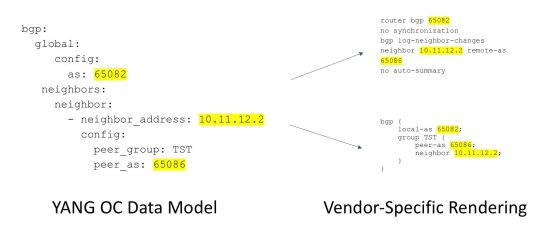 The data in the model on the left contains the information needed to deliver either of the syntax specific versions… just add words. Yes, we still have words as tags in the model, but it normalizes those tags across vendors and gets rid of the grammar needed to specify how values relate to each other. We do not want to add words back if we can avoid it, so the next step is to encode all of this data into XML and shove it into the device via NETCONF.
The data in the model on the left contains the information needed to deliver either of the syntax specific versions… just add words. Yes, we still have words as tags in the model, but it normalizes those tags across vendors and gets rid of the grammar needed to specify how values relate to each other. We do not want to add words back if we can avoid it, so the next step is to encode all of this data into XML and shove it into the device via NETCONF.
NETCONF/YANG gives us programmability, but we still need automation since the two are not the same. This is where Ansible enters back into the story. In my opinion, it is the best of the open-source IaC tools for delivering data models to devices. I’ll explain why and dig deeper into the power of data models in my next blog.
Want to learn more about data models before we start to use them in the next few blogs? Check out Model Driven Programmability at Cisco DevNet. As always, please drop me a comment on this blog if you have questions, or topics you’d like this series to cover.
Get your free DevNet account for access to network automation resources, learning labs, and sandboxes.
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Twitter @CiscoDevNet | Facebook | LinkedIn
Visit the new Developer Video Channel





Good stuff! You have a small error in the "OpenConfig data model rendered in YAML", the picture says "YANG OC data model".
Looking forward to the next post!
Thanks for the feedback, Karl. YANG is the description of the model. It is traditionally rendered in XML, but I did so in YANG because it is easier to read. Sorry for the confusion.
This is the second part/second entry and I cannot wait for the next one.
A really good approach, explanation and examples for such a beginner in network automation like myself.
However, please do this Netflix-style and drop the whole "season" to binge-read/absorb and lab; without the need to wait another 4 weeks for part 3 and then part 4 in November 😉
Well done Steven
Would JSON or XML schema be useful for doing the same job?
I get more into this in the next blog, but YANG _is_ an XML schema. Any type of organization helps, but the standardization that YANG brings is particularly helpful (even though different vendors use different YANG models). The main point is that your network is the manifestation of configuration data. Organizing and maintaining this data, in whatever way is most conducive to your situation, is the first step to a successful automation strategy.
You could use JSON as well, but NETCONF expects XML payloads, so it easier for that purpose. As I point out in Blog 3, you can change the encoding to suit the particular use case.
Great stuff Steven, both blogs so far. I really like the way you're explaining models and showing how YANG is just that for network configurations. Abstractions are everywhere in computer science from programming languages to tensorflow graphs. Very similar to how exponents build upon multiplication which builds upon arithmetic. Turtles all the way down!
It's nice to see it now being applied more to the networking world and to see how you are also considering heterogeneous environments.
I'm really interested to see how you can use Jenkins and things like this in NetDevOps so hoping you have some more material on that coming in the future!
Excellent article(s) Steven, I look forward to more of them! In relation to your comment "This is where Ansible enters back into the story. In my opinion, it is the best of the open-source IaC tools for delivering data models to devices. I’ll explain why and dig deeper into the power of data models in my next blog."
I'm certainly interested in seeing where this goes but I'm equally interested in you thought on Data Models + Ansible vs Data/Service Models using NSO. This is the real question for me, build it all myself or use tools that get us half way there (or more) without having to code myself. After all, for most enterprises Infrastructure is not my company's core business so I need to deliver services as easily and as fast as possible.
Seems to me that there are so many if/then/else statements, corner case support or no support at all in developing automation using Ansible (leading to custom scripting) that make me shy away from using it, especially since whatever I custom code, I have to support and update as the need arises.
I'd appreciate your viewpoint on this, especially wrt to Ansible vs NSO 😉 …..
Great question, Michael. I do not look at it as an either or, but as levels of capability. Ansible provides a great baseline capability to push out models, but starts to struggle when you want more checking/validation before the models are pushed out. Later in the series, we'll introduce NSO for some of that. As use-cases get more complex, the introduction of controllers to mitigate some of that complexity for Ansible is very helpful.
Excellent, thank you for providing some context for me. Comparisons between Ansible/NSO are non existent so its been difficult to peel back the layers to understand why one or the other or why one for A and the other for B.
Part 3 is clear and concise too, keep it up!
Yes, we still have words as tags in the model, but it normalizes those tags across vendors and gets rid of the grammar needed to specify how values relate to each other. We do not want to add words back if we can avoid it, so the next step is to encode all of this data into XML and shove it into the device via NETCONF.
I lost it in above paragraph ?