
Grapheme to Phoneme (G2P) is a function that generates pronunciations (phonemes) for words based on their written form (graphemes). It has an important role in automatic speech recognition systems, natural language processing, and text-to-speech engines. In Cisco’s Webex Assistant, we use G2P modelling to assist in resolving person names from voice. See here for further details of various techniques we use to build robust voice assistants.
We developed an open-source PyTorch transformer-based model for Grapheme to Phoneme (G2P) conversion. Check out the github repo here.
Why we transitioned to PyTorch
We had relied on a popular open-source, pre-trained Sequence-to-Sequence (seq2seq) G2P model developed by AC Technologies LLC (published here). The model uses a 3-layer transformer models for encoding and decoding with 256 hidden units and 4 attention heads at each transformer layer. The model was implemented in TensorFlow 1.15. Transformer models have been providing state-of-the-art results on various sequence learning tasks and based on results from AC Technologies, these models provided superior performance than recurrent neural networks.
We wanted to transition this model to the PyTorch framework for the following reasons:
- Since we used a pre-trained model in production deployment, we were forced to use an out-of-date TensorFlow version that had lots of security vulnerabilities in its dependencies.
- We wanted greater ownership of the data generation and model development of this component since we could improve the model’s performance.
- PyTorch had a lighter security footprint than TensorFlow. See here to analyze the security footprint of 3rd party libraries.
Since the PyTorch community did not provide an open–source G2P alternative to CMUSphinx, we decided to build a PyTorch G2P model and open source it.
Experiments
We used CMUdict 2014 for training and validation, and the data from CMUdict PRONASYL 2007 for testing. This was done to directly compare results against the pretrained CMUSphinx model which was benchmarked in a similar way. CMUdict 2014 and Pronasyl both have data containing the grapheme and its phoneme. The phoneme is defined according to the ARPABet specification of 39 phonemes, however CMUdict 2014 also adds stress data to each phoneme, which is numbered from 0 (no stress) to 2 (secondary stress), but Pronasyl does not. More details on the format can be found here. The dataset size of CMUdict 2014 is 135,155 while Pronasyl’s test dataset size is 12,753. We could not use Pronasyl’s train data since it did not have the stress information, but we were able to evaluate on Pronasyl’s test data by simply removing the stress information outputted by the model.
We modelled the G2P problem as a transformer-based seq2seq model as shown in figure 1. Here, the encoder transformer learns from the grapheme sequences and the decoder transformer learns to decode it to phonemes. This architecture is like AC Technology’s system.
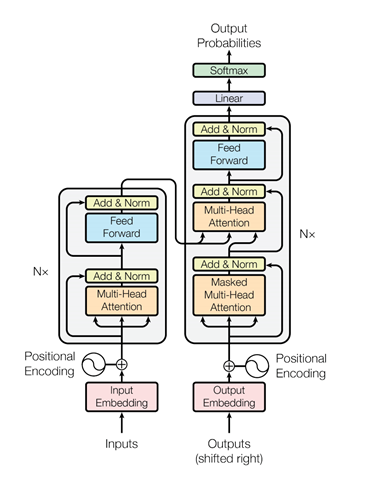 Figure 1: Encoder-Decoder (Source: Vaswani, Ashish, et al. “Attention is all you need.”
Figure 1: Encoder-Decoder (Source: Vaswani, Ashish, et al. “Attention is all you need.”
Advances in neural information processing systems. 2017)
To compare against CMUSphinx and to explore other possible architectures, we built two models, one with similar specifications as CMUSphinx (PyTorch_small) and another with double the parameters (PyTorch_big). We wanted to test how the architecture complexity affects performance while trying to benchmark our model against CMUSphinx.
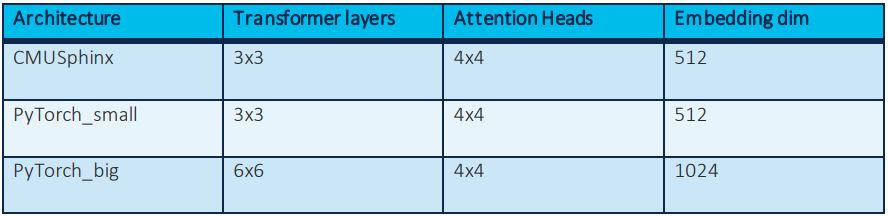 Table 1: Different architectures experimented
Table 1: Different architectures experimented
We used Facebook’s FairSeq library to implement the transformer architecture. FairSeq is a wrapper around PyTorch that provides advanced modelling of seq2seq models, like in-built beam search functionality which is absent is PyTorch’s transformer implementation. It also provides infrastructural benefits like multi-GPU training, which we leveraged to speed up training.
Results
We benchmarked PyTorch_small and PyTorch_big with the following metrics:
- Phonetic error rate (%): For each word, calculate the percentage of the total number of predicted phonemes that are correct when compared to the gold phonemes. Average this across all words.
- Word error rate (%): For each word, compare the entire sequence of predicted phonemes to the gold phonemes. We calculate the percentage of words whose predicted phonemes are an exact match to the gold phonemes.
- CPU Latency (milli-seconds): Time taken to execute the G2P function on a CPU machine
- GPU Latency (milli-seconds): Time taken to execute the G2P function on a GPU machine
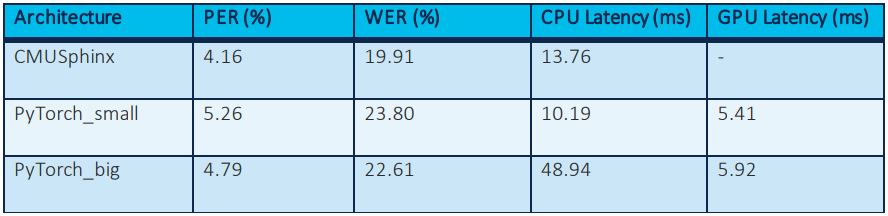 Table 2: Metrics tested
Table 2: Metrics tested
Discussion
We found that PyTorch_small underperforms CMUSphinx by ~1% error rate while PyTorch_big underperforms slightly to CMUSphinx. However, PyTorch_small has much better latency performance than PyTorch_big and is equivalent in performance to CMUSphinx. Qualitatively looking at each regression in PyTorch_small versus CMUSphinx revealed that many of regressions weren’t true regressions, instead both models provided acceptable pronunciations for words. A few such examples are provided below:
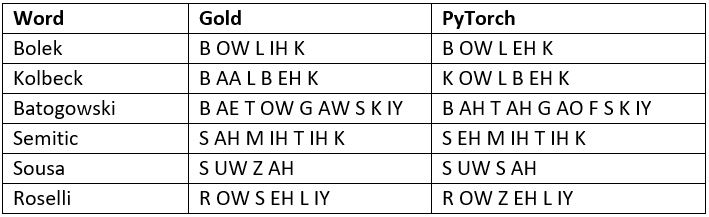
We also performed end to end tests where we integrated PyTorch_small into our knowledge base and tested person name recall on an evaluation set of noisy names outputted from automatic speech recognition (ASR) systems and found the results were equivalent to CMUSphinx.
Concluding thoughts
We developed a PyTorch implementation of a transformer-based G2P model that performs equivalently well to the CMUSphinx TensorFlow model. Developers who are building voice assistants in their products will find this repository useful for providing intelligent results to their users by augmenting signals from Automatic Speech Recognition (ASR) system with pronunciation information from the G2P model.
Please check out the G2P model here, and be sure to contribute/share it.
Find out more about Cisco AI use cases and technologies.
If you find this type of work interesting, send us an email at mindmeld-jobs@cisco.com.
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Twitter @CiscoDevNet | Facebook | LinkedIn
Visit the new Developer Video Channel





Hey great to see an aspiring data scientist to have come so far