
The author of this blog is Patrick Riel, software engineer with Cisco DevNet
Inference at the Edge
“Inference” is the process of using a trained Machine Learning model to make predictions on new inputs.
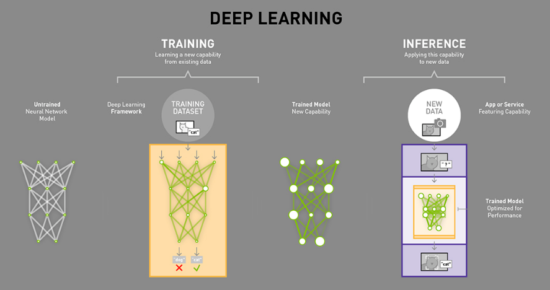 This diagram from NVIDIA shows how inference works for AI driven deep learning.
This diagram from NVIDIA shows how inference works for AI driven deep learning.
There are many technical benefits of running Inference at the Edge.
- Reduce network bandwidth
- Real-time predictions
Use cases for running Inference at the Edge span across all industries.
- smart cities
- video surveillance
- predictive maintenance in factories
- collision avoidance
- voice/sound recognition
- image recognition
Challenges with enabling Inference at the Edge
The opportunities for innovative solutions utilizing Inference at the Edge are great. But so too are the challenges in building and implementation. Let’s take a look at a few:
Network
Bandwidth is usually expensive, low latency is required for some inference-based applications, and internet connectivity might not be available.
Constrained Devices
Power consumption is a major concern, generally more power means higher cost. Constrained devices are inherently resource constrained (limited memory and compute). There’s also a wide range of operating systems and different architectures.
ML/AI Frameworks
Developers use a wide range of frameworks and tools. Providing support for popular frameworks is a must (Caffe, MXNet, Tensorflow, etc.)
Management
Providing a familiar and standard way to schedule, deploy, and update applications is a must.
Solving these four things independently from the ground up is no easy task, let alone providing them in one comprehensive solution. Luckily, we were able to leverage a mix of Cisco Solutions, Partner products, and projects from the open source community to create a secure and scalable prototype.
Getting the green light for our Inference at the Edge project
Co-Creations pitched the idea to internal stakeholders and received the greenlight at Cisco Live Barcelona 2019, targeting DevNet Create as our demo date.
In general, we were hoping to be able to offload specific tasks and workloads from an IOx application that required accelerated compute to a dedicated ML/AI device.
We decided on using the newly announced IR1101 and the NVIDIA Jetson TX2 as the core components of our project.
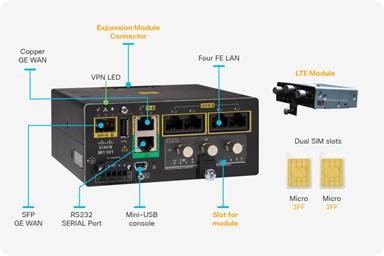 IR1101
IR1101
- IOx enabled
- SD-WAN ready
- Low Power Consumption (10 W)
- Modular LTE and 5G ready
- Powered by Cisco IOS XE
- Edge-Computing Enabled
- Compact Form Factor (<2RU)
NVIDIA Jetson TX2
- 7.5-watt supercomputer on a module
- Allows for true AI computing at the edge
- Runs a modified version of Ubuntu
Taking a “developer first” approach
Drawing inspiration from the Lean Start-Up, DevNet Co-Creations pioneered a Developer First Approach to building Hardware, delivering an all-in-one solution for enabling Inference at the Edge. A Developer First Approach is a philosophy for building software and hardware that will be primarily consumed by other Developers. During the early stages of development, Developer feedback is valued more than secrecy. Leveraging open source projects when possible is encouraged, as it reduces time to MVP (minimum viable product), and reduces fear of vendor lock-in. Providing a low barrier to entry is prioritized, the less difficult it is to learn, the more likely Developers will adopt it.
Connecting the TX2 to the IR1101
Architecting the best way to schedule workloads from the IR 1101 to a NVIDIA Jetson TX2 was an open item that had to be resolved. Considering that we needed a portable way to run workloads that leverage different ML/AI frameworks, using containers seemed like a logical solution. Managing containers at scale requires an orchestration layer. Kubernetes being the industry standard seemed like a great option besides the fact that we are dealing with constrained devices. Fortunately, we came across an open source project called k3s, which was announced in early 2019 and is specifically targeted for IoT use cases. We were quickly able to validate that we could in fact run a k3s node on a NVIDIA Jetson TX2 and a k3s master on an IR 1101.
The “master” refers to a collection of processes managing the cluster state. Typically all these processes run on a single node in the cluster, and this node is also referred to as the master. The master can also be replicated for availability and redundancy.
The nodes in a cluster are the machines (VMs, physical servers, etc) that run your applications and cloud workflows. The Kubernetes master controls each node; you’ll rarely interact with nodes directly.
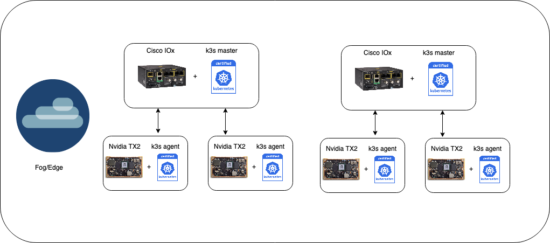
Scheduling workloads at the edge
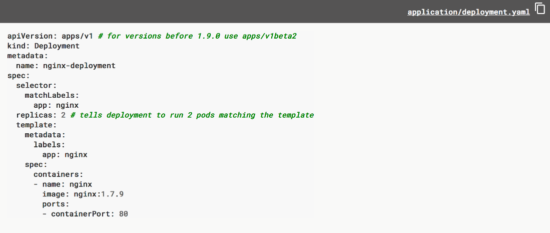
k3s provides a fully compliant Kubernetes API, scheduling workloads is as easy as describing a Kubernetes Deployment object.
Partner hackathon
At DevNet Create, we invited four Partners (Amazon, Wipro, Tech Mahindra, and Deloitte) to participate in a hackathon to provide feedback on our prototype.
 The NVIDIA Jetson TX2 (custom 3d printed box) on-top of the IR1101
The NVIDIA Jetson TX2 (custom 3d printed box) on-top of the IR1101

General Observations
- Excited and happy to be part of the developer first approach that Cisco DevNet is leading
- Go-To-Market is usually challenging. Partners are looking at Cisco to lead in some ways for the Go-To-Market of their solutions
- Partners loved having Cisco and AWS together and want to use products from both to build solutions
Constructive Feedback
- Each partner wants to see Cisco differentiate its offer with Networking controls e.g.: class of service, policy etc.
- Want to see Comparative Study with other vendors, recognizing the potential value of network-based solutions vs compute-based solutions
- Providing pre-built Docker containers that contain popular ML/AI frameworks would reduce development time
Conclusion
Taking a Developer First Approach and engaging with customers/partners in the early stages of a project can help steer vision and enable success. It might take several tries to achieve success or you might be one of the lucky ones and succeed on your first try. Either way, don’t be afraid to fail. In order to innovate, failure is something that will inevitably happen. Each project that you take on, successful or not, is an opportunity to grow.
If you’d like to learn how to deploy a k3s master as an IOx Application, please check out this Learning Lab!
Learn more about DevNet Co-Creations and how to engage with us?
Related resources
- DevNet AI/ML developer resource center
- Automation and programming learning paths
- IoT learning tracks
- IoT use case library
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Twitter @CiscoDevNet | Facebook | LinkedIn
Visit the new Developer Video Channel






