 It’s been a very busy few weeks. The Data Storage Innovations (DSI) conference, the Ethernet Summit conference, EMCWorld, and next week at CiscoLive, I’ve been starting to talk about a new concept in Data Center storage networks called Dynamic FCoE. Understandably, there have been a lot of questions about it, and I wanted to try to get this blog out as quickly as possible.
It’s been a very busy few weeks. The Data Storage Innovations (DSI) conference, the Ethernet Summit conference, EMCWorld, and next week at CiscoLive, I’ve been starting to talk about a new concept in Data Center storage networks called Dynamic FCoE. Understandably, there have been a lot of questions about it, and I wanted to try to get this blog out as quickly as possible.
The TL;DR version: Dynamic FCoE combines the best of Ethernet Fabrics and traditional deterministic storage environments to create massively scalable and highly resilient FC-based fabrics. If you thought you knew what you could do with storage networks, this takes everything to a whole, new level.
As conversations about Ethernet networks move into different technology types and uses, the exciting part is the capability for network topologies to morph into a variety of configurations. I’ve mentioned ages ago that each Data Center is like a fingerprint – no two data centers are exactly alike.
When I was at the 2014 Ethernet Summit there were keynotes being made by Google, Comcast, HP, as well as Cisco, and each of the speakers were talking about how much of the network traffic in their data centers had shifted from the traditional “Access, Aggregation, Core” layered system – a traditional Cisco North-South approach – into a much heavier East-West traffic pattern:

In other words, data centers are beginning to see much more server-to-server connectivity, which in turn brings new demands on networks. For networks that are designed to handle higher loads “in and out” of the data center, obviously you can wind up with architectural bottlenecks when traffic patterns change.
For that reason, new architectures are emerging that capitalize on the predictable performance and tried-and-true “Leaf/Spine” architectures (also called Clos). These architectures often are designed to have 40, or even 100G connections between the leafs and spines, which give massive bandwidth capabilities the more they scale.

What about Storage?
While this does help solve some of the Ethernet issues inside a modern data center, most storage environments are still “North-South.”

So, many question arise when we start to figure this out:
- What can we do with storage traffic that typically goes “North-South?”
- How do we configure all of these connections so that we can continue to have dedicated SAN A/B traffic best practices?
- What happens when we add a new spine? Do we have to re-configure the ISL connections?
- Can storage even participate at all, or do we have to have a completely separate network for storage again? Wasn’t this the whole point of convergence in the first place?
Introducing Dynamic FCOE
Dynamic FCoE is the ability to overlay FCoE traffic across these types of architectures dynamically, but it does require a slightly different way of thinking about how storage is done over the network.
For example, in a typical storage SAN environment, we keep the resiliency and redundancy by keeping “SAN A/B” separation, like the image below:
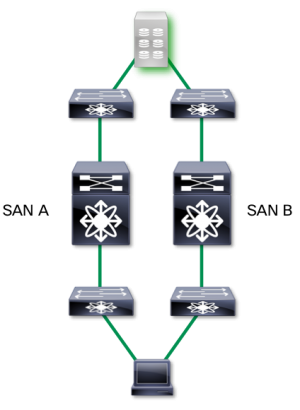
Each of these is a duplication of the other. When designing these types of environments, savvy storage architects have to take into consideration how much bandwidth they need in order to handle not just normal traffic, but bursty traffic as well. That number is based on something called “oversubscription,” which is where you calculate how many hosts you need to have connected to each target (storage) port. Generally speaking, that can fall anywhere between 4:1 (hosts:targets) to 20:1, depending on the application environment.
(For comparison, NFS and iSCSI networks can be an order of magnitude or more oversubscribed).
On top of that, because storage is the most persistent item in the data center (storage can stay in use for years), architects have to plan for growth as well. This kind of overprovisioning gives them a comfortable overhead for growth, but can wind up being an expensive use of resources that are simply waiting to be “grown into.”
Then they have to plan for what happens if a SAN were to have an issue, like a link failure or, worse, if an entire switch were to go down:

If something like this happens, though, you don’t simply lose the use of that particular switch or link. Instead, you lose the storage capability of all the bandwidth on SAN A. If the network has not been architected to accommodate this traffic, SAN B may wind up completely overloaded, and performance can take unacceptable hits.
While this creates a highly redundant and scalable network, and has been popular for many years, it does wind up placing an incredible, inflexible burden on the architecture.
This was the problem that FCoE was designed to solve – the ability to consolidate I/O onto the same wire and switch types so that you could manage bandwidth more efficiently, especially as throughput speeds hit 40- and 100 Gbps. Simply having and paying for bandwidth that you don’t use gets very, very expensive. Moving away from a dedicated network into a more flexible, virtualized one upon which we can overlay FCoE traffic makes much more sense in these types of environments.
How It Works
Dynamic FCoE modifies the way we see storage networks, as it allows us to use FCoE as an overlay on top of Ethernet forwarding technology – in this case FabricPath. This allows us to use the Equal-Cost Multipathing (ECMP) capabilities of large networks to add resiliency and robustness to our storage networks.
Let’s take a look at a hypothetical Leaf/Spine architecture:

In this example we have our server (lower left) connected to a Top of Rack (TOR) switch, which in turn is connected to every Spine switch. In this environment, the leaf switch can capitalize on the bandwidth of each Spine to access the east-west traffic destination (which may include storage systems).
Because we’re using FabricPath between the leafs and spines, we can take advantage of the auto-discovery and lookup capabilities of the technology to dynamically discover and create the links between each of the switches. This means that as we add additional spines and/or leafs into the network, FabricPath does the heavy lifting of discovery and interconnectivity.
From a FCoE perspective, this is very cool. Why?
Because we don’t actually have to manually go in and create those connections (called Inter-Switch Links, or ISLs). We set up the leafs as the “FCoE-aware” or “Fibre Channel-aware” FCF switches (yes, it works with native Fibre Channel as well), and then transport the frames across the Leaf/Spine “backplane.”
In fact, once we have the FabricPath topology configured, when we establish the feature fcoe on the leaf switches the network:
- Dynamically discovers the paths across each spine to the destination FCF
- Dynamically creates the virtual Fibre Channel (vFC) ports
- Dynamically creates the VE_Port type
- Dynamically instantiates the ISL
In essence, you are setting up a dynamic, robust, multihop FCoE environment without having to do it yourself.
SAN A/B Separation
What about the SAN A/B separation? With Dynamic FCoE, physical SAN A/B separation occurs at the edge layer, which is often the most vulnerable part of the storage network.
So, while the physical topology may look like the diagram above, the actual Fibre Channel topology winds up looking like this (from a storage perspective):
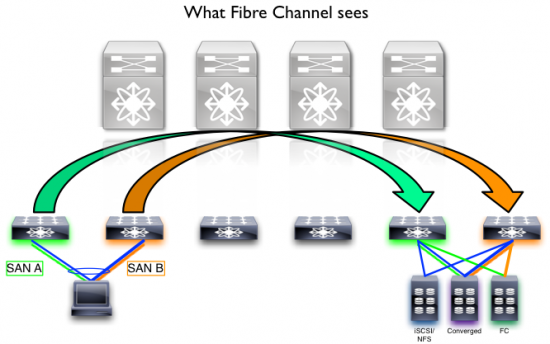
This gives storage environments an incredible flexibility in terms of deployment. Because of the fact that we are using the Ethernet topology for these dynamic discovery and instantiation, we can capitalize on eventual growth patterns that may include additional storage leafs, server leafs, or transport spines.
Moreover, we can take advantage of the higher bandwidth that naturally comes from robust leaf-spine communication, namely 40G interconnects and eventually 100G interconnects.
Resiliency and Reliability
Obviously, this would be a pointless solution if we didn’t have the same reliability that we’ve always had – or better. I’m going to argue that we have, in fact, upped the ante when it comes to both of these.
Take a look at the graphic below:
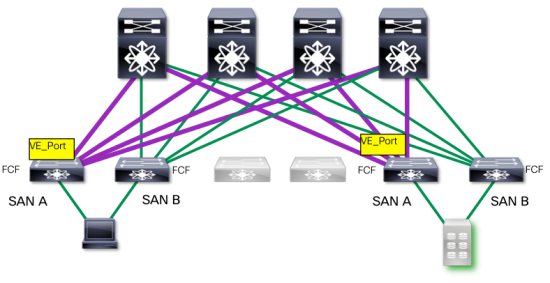
In our environment we have established a link between our leafs and spines, and made our connections across each of the spines. Now, let’s take a look at a particular link:

Looking at this from the perspective of a “SAN A” link, you have effectively a edge-core topology (with a transport spine in the middle). Our VE_Ports have been created to handle the ISL traffic. In short, this looks precisely like the “North-South” traffic that we were looking at earlier, just drawn on its side.
What happens if we were to lose the spine for this connection?
Because the traffic has been load-balanced across all the spines the FCF Leaf does not lose its connectivity to its destination storage leaf. That means that – unlike a more traditional storage topology, we don’t lose all the bandwidth for that side of the network, nor does the MPIO software kick in. In fact, from an FC perspective, there is no FSPF re-calculation, and no RGE (resume-generating event) for the admin.
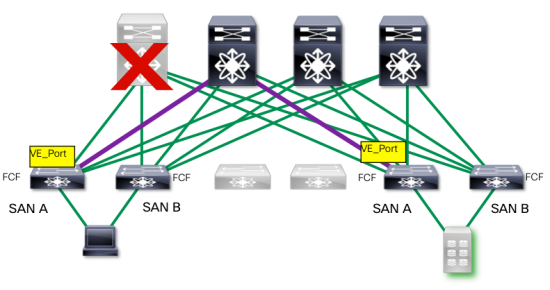
In short, in order to lose our SAN capability our entire data center spine would have to go down. This is what I consider to be a pretty impressive improvement in reliability.
What happens if we were to lose the edge switch?

In this case, the MPIO software would kick in exactly as it normally would, and traffic would failover to SAN B. However, in this case, we have not lost the remainder of the bandwidth on SAN A. SAN B can use the same spine transports it always could, and so we have restricted our failure domain to just the switch, as opposed to the entire SAN bandwidth capabilities.
Availability
Generally in blogs I don’t like to throw in a bunch of products in a technology piece, but it doesn’t make much sense to talk about the technology and not say where you can use it.
Right now you can configure Dynamic FCoE using FabricPath on the following platforms:
You’ll need the R7.0(1)N1(1) software release on each of the platforms for this capability. The Nexus 7000 support (as a Spine transport switch) is coming later this year.
There are no additional licenses beyond the normal FabricPath and FCoE (for the leafs) ones, and storage vendor qualifications are coming over the summer, or later this year as well.
If you happen to be going to CiscoLive, I will be discussing Dynamic FCoE in a number of my breakout sessions, as well as demonstrating it live and in action in the booth. Additionally, I’ll be presenting inside Cisco’s theatre booth.
Or, you can just look for the hat and corral me to ask me more questions.
Summary
Personally, I think that Dynamic FCoE is a very cool concept for a number of reasons, not the least of which is that we are adding additional options for customers, additional reliability and high availability mechanisms, and making it easier to deploy storage networks in an ever-changing world of smarter networks.
In short, we can:
- Dynamically create the individual component pieces for storage ISLs
- Dynamically create the appropriate port types
- Dynamically discover and initialize new leafs when they come online
- Increase our bandwidth efficiency and reduce our failure domains
- Improve our economies of scale by not overprovisioning “just-in-case” strategies
- “Bolt-on” new topological considerations into existing, Classical FC/FCoE storage environments
- Increase the availability through better architectures
- Increase our overall bandwidth capability through the use of 40G and 100GbE
- Continue to use standards-based solutions to improve Data Center performance for compute, network and storage
Does this mean that you must do this? Absolutely not. You can still do Classical Multihop FCoE or even Single-Hop FCoE that branches off to a traditional FC SAN complete with physical SAN A/B separation. In fact, you can even have a hybrid environment where both can run simultaneously. The point here is that if you are looking for one network ‘to run them all,” so to speak, you can have your FC and FCoE at the same time without needing to have a completely separate network.
In the coming months, Cisco will be releasing additional hardware and software capabilities, including Dynamic FCoE using DFA, but that’s a subject for a future blog post.
If you have any questions, please feel free to ask in the comments below.






Hi,
Thanks for the valuable blog. Its very useful for the data center deployments.
Keep writing!
Tushar
Thank you for reading!
Hi Dr. Metz
Would be interested to know, when this Feature will become available for ACI fabric.
Hi there. Thanks for reading the blog. I’m afraid the group that is working on ACI is different than my own, and I don’t have any insight into their plans. As soon as I’m made aware, however, I will likely create a followup post. 🙂
Hi J,
A nicely written summary of storage networks using an Ethernet fabric and FCoE with Cisco products.
I have a couple of questions.
1. Can you explain why the topology you show, leaf-spine or core/edge, for the Ethernet fabric transporting FCoE is NOT possible with a Fibre Channel SAN?
2. Can you explain why a FC SAN has to be over provisioned on day one but an Ethernet fabric transporting FCoE does not? Or said differently, what is about FC that requires overprovisioning and prevents incremental growth of the fabric?
3. Can you explain how your failure domains are reduced compared to FC SAN A/B fabrics when failure can include any component (hardware, firmware), operator error or act of God? Or said differently, can this design overcome a network failure and keep traffic storage traffic flowing for 100s or 1,000s of applications?
4. Based on the clarification for #3 above, can you explain what is “new” in this architecture when compared to FC SAN architecture and why it increases availability above that found in a FC SAN A/B fabric architecture?
Thanks for helping me understand your conclusions more clearly.
Best.
Brook.
Hi J,
A nicely written summary of storage networks using an Ethernet fabric and FCoE with Cisco products.
I have a couple of questions.
1. Can you explain why the topology you show, leaf-spine or core/edge, for the Ethernet fabric transporting FCoE is NOT possible with a Fibre Channel SAN?
2. Can you explain why a FC SAN has to be over provisioned on day one but an Ethernet fabric transporting FCoE does not? Or said differently, what is about FC that requires overprovisioning and prevents incremental growth of the fabric?
3. Can you explain how your failure domains are reduced compared to FC SAN A/B fabrics when failure can include any component (hardware, firmware), operator error or act of God? Or said differently, can this design overcome a network failure and keep storage traffic flowing for 100s or 1,000s of applications?
4. Based on the clarification for #3 above, can you explain what is “new” in this architecture when compared to FC SAN architecture and why it increases availability above that found in a FC SAN A/B fabric architecture?
Thanks for helping me understand your conclusions more clearly.
Best.
Brook.
Sorry about the double post. The site seemed to freeze when I posted the original one.
Hi Brook,
Thanks for taking the time to read the post and write the questions. I’ll try to see if I can address them adequately in turn.
1) Of course there is nothing that prevents a FC mesh architecture in this fashion. IIRC there are many FC training guides which show almost verbatim topologies. The issue is not whether you can’t do this with FC, but rather how to do this with consolidated I/O on Ethernet networks while maintaining FC best practices. In the FC scenario, for example, you cannot run Ethernet LAN traffic simultaneously with guaranteed minimum bandwidth like you can the other way around. Ultimately, from the perspective of an architect who is looking at deploying these kinds of Ethernet topologies, it’s good to know that they are not forced to create separate networks but can actually run deterministic storage over those topologies if they wish, and the endpoints can be any flavor of FC-based connectivity they desire.
2) This is a really good question. The question at hand is not whether you overprovision Ethernet networks in a leaf/spine configuration, but by how much and how efficiently the bandwidth you provision is used. In the case where a classic storage North/South network loses a core switch, as noted in the images above, it is impossible for SAN B to use the bandwidth between switches that belong to SAN A, even if they are still operational. In this case, though, SAN B is not dependent upon the underlying physical topology to continue to use the maximum available bandwidth in the network.
3) I think you know that I was not suggesting that a topology is going to be bulletproof under any and all circumstances or withstand an “act of God” merely because it’s a topology. 🙂 The “failure domain” I was referring to was specific to the SAN A failover aspect, where instead of taking down an entire SAN with the loss of the component (in the example above, it was the hypothetical switch in the SAN path), it is limited to the component itself.
4) There’s a great deal in the blog itself that addresses this specific question, but at its heart I think you actually reinforce my point in a round-about way. The goal here is that we are not trying to insert something ‘new’ into the FC SAN design principles. On the contrary, we want to sustain and maintain those best practices when applying them to consolidated networks. The fear comes that the tried-and-true FC designs will somehow be sacrificed when moving to these Ethernet topologies when in fact it’s not a necessity. At the same time, there is nothing that mandates this, either. You can still run single-hop topologies or multihop FCoE topologies (or mixed) simultaneously, instead, or in addition to Dynamic FCoE.
Hope that helps.
Best,
J
J,
Okay. That helps. I must confess, some of the phrasing you chose in the write up could have lead a reader to certain conclusions not based on the facts which is the reason for my asking these questions to clarify what you were saying.
I humbly submit that at its heart the story you are telling is about how Ethernet networks need to be like a FC SAN fabric if you are going to use them to transport block storage traffic for lots of applications. I agree with that observation and have for several years.
But, the devil is in the implementation details, as always seems to be the case. And the detail that needs close attention is the relationship between a “fault domain” and availability of its resources. I believe block storage traffic requires a design that survives complete loss of the fault domain so the application never new about the failure. Or else one day it sucks to be you and your company too.
To be clear, the best practices and design principles validated with FC SANs for a decade and a half are imposed by the requirements of the application (SCSI or FICON)that use the fabric. Therefore the fabric has to be designed to satisfy the application requirements and not the other way around.
Block storage traffic for any application, let alone a 1,000 applications using the same network, requires “guaranteed” delivery even when (not if) a fault domain fails. Thus, A/B fabrics are physically isolated fault domains and they exist to fulfill that guarantee. Short of magic, there isn’t any other way to meet the guarantee when faced with real world “details” about what can go wrong.
Why I raise this point is that you can’t have your cake and eat it to. If you have to survive complete loss of a failure domain, then you can’t share it’s resources with any other domain, period. That’s the “devilish detail” that converged network architectures never seem to address head on. In fact the price you pay for guaranteed delivery of traffic is that when a failure domains is lost all of its resources are too; there is no “sharing” or you only have one failure domain and now you are lost when disaster strikes.
Thank you for posting this material. It’s beneficial.
Best.
Brook.
I didn’t say you can’t have shared resources and survive some failures. But I did say you can’t guarantee survival and have shared resources because that requires magic.
J,
I have a couple of comments that I typically see in data center practice…
First, I have never seen any shop running a modern SAN, for instance Gen5 (16 Gbps), say they are BW constrained. This includes Core-Edge ISLs after fan-in. If they are BW constrained then they add 1 or more additional ISLs. Shops use large quantities of BW in the anticipation that they may need it when fabric A or B goes down, or maintenance and the such. Its all part of the planning process and should be to nobody’s surprise. I do not buy the, if Fabric A goes down, then Fabric B is under duress. That is just not true, IMHO plus I’ve never seen that.
Second, a network as you are describing is still just one network and it must be one network to gain the benefits of not having to purchase, deploy and operate two identical networks, otherwise, FCoE would have marginal added value at best, but that is a different discussion. Inherently, one network is a major problem for critical enterprise workloads. Workloads in which the enterprise itself is based and an outage spells pure disaster.
Because it is a network, everything is interconnected and no amount of: VDC, VRF, VSAN, VLAN… will protect you if a memory leak (that’s just an example) in the kernel decides to take this network for a ride to hell. The worst type of network problem is the type in which there is no actual identifiable failure, instead there is just random aberrant behavior that is extremely difficult to diagnose. No amount of QA and OEM testing can be done to ensure all defects have been eliminated. Can Cisco guarantee that this one network will never go down? It can be guaranteed that if fabric A goes down, it won’t take fabric B down with it as long as there are no connections between them, hence, the concept of the “air gap”.
Storage shops were not stupid back when the idea of A & B fabrics came about and we are just becoming enlightened now that there is this “new” way to converge them. The technology to converge FC fabrics into one has always existed and it could have certainly been done. There was no ulterior motive just to sell twice as much equipment. The reality is that the opposite is true, we were smart to keep them separate which has proven to work and be highly reliable. And, if shops move towards removing this absolute redundancy then they are becoming less enlightened as those that have gone before them.
MSD
Hi Mark,
Thanks for taking the time to reply to the blog. I think you may have been confused by a couple of the points I was making, and I do appreciate the opportunity to clarify.
Re: Bandwidth constraints
The issue here is not bandwidth constraints at all. It’s how you can add the ability to handle deterministic storage traffic that is normally architected in a North-South paradigm into an Ethernet topology that is East-West. The concern can be for storage administrators – I had one come up to me today at CiscoLive ask this question, for example – how we can prevent the fight for bandwidth when using multiple protocols. My point is that not only can you guarantee the bandwidth using standards-based ETS, but also capitalize on the additional bandwidth going through the network as well. If you’ve got it, you’ve got it.
Again, you are correct. I did say that this is how you plan for and architect storage SAN A/B topologies. However, if the topologies are mis-calculated, and/or if storage capacity growth exceeds plans, it is possible to place a burden on an unprepared failover network.
Leaf/Spine architectures may not be commonplace, even in Ethernet deployments. This does not mean that there hasn’t been a lot of interest in these types of topologies. ACI, DFA, FabricPath, etc., are just a few of the possible means to do this. This, however, is not a discussion about the merits of Leaf/Spine (which are used heavily in InfiniBand architectures, btw, and are well-understood), but rather how storage networks can be used in conjunction with them as a possible option.
I’m not sure where I implied that storage shops who had implemented physical separation were either unenlightened or duped. In fact, I believe I was very careful to indicate that this logical separation was simply an option, and it’s not just possible (but highly likely) that data centers will continue to use Classical FC/FCoE environments in this fashion.
Although I think it’s pretty clear where you stand on the matter. 🙂
Hi J.
How could we guarantee that’s SCSI flows from one intiator to a specified target won’t take exactly the same Spine in emulated Fabric A and B?
And if this was the case, what would be the impact (in terms of reading/writing) of a reboot/failure of this spine? If we consider that we have approximately 100ms of reconvergence, is there any “chance” that the server completely lose connectivity to its remote disks/datastrores?
In any case, your article is great and gives a good perspective of a possible future for mutualized NextGen DC Architecture.
Best.
Pierre-Louis
Hi Pierre-Louis,
That’s an excellent question, and I’m glad you’ve given me the opportunity to clarify here.
The best way to think of the interconnections between the leafs through the spine is that it’s similar to a port channel between typical FC switches. That is, we load-balance using SRC/DST/OXID.
The way Cisco handles ISLs in a port-channel is by using SRC/DST/OXID. Exchanges (which are made up of sequences, which are made up of FC frames) are sent across available links according to their OXID, not just their source and destination. Dynamic FCoE works exactly the same way. Just like if you lose a link inside of a port-channel you don’t lose the entire connection, Dynamic FCoE creates the same behavior.
I’ll be writing a deeper-dive on this soon, I promise.
What about Dynamic FCoE overklig ACI?
lets assume N7K is the Spine or might be in bth the spine and leafs
do we need storage VDC ? if yes then how this architecture will look like in this case !
Excellent question. With all of these architectural and design questions, I think I’m going to have to write a more specific, detailed blog on how this is put together. 🙂
The important thing to remember at this point is that the spine does not process FCoE traffic, which means that there is no Fibre Channel Forwarder (FCF). If there’s no FCF, then the N7k does not have to have a storage VDC (nor a license) in the spine. The only thing that will be necessary is for the spine to be able to handle SRC/DST/OXID load-balancing of Fibre Channel traffic, which is how we handle port-channels between switches right now.
Hope that helps. 🙂
Thanks J Metz, it dose help 🙂
but based on that if we have the N7K as the leaf switch then we will need to have storage VDC, right ? if yes I see it here going to be a bit complicated design and not as simple as simple FP architecture , not sure !!
Yes, N7k topologies and specifics/best practices will be forthcoming in the future.