
Last week I attended the 2015 London Gartner Data Center conference.
In my first blog (part 1) on this event, I covered some of my main learnings and observations, #1 .. #5:
- Bi-modal IT,
- Anti-fragility,
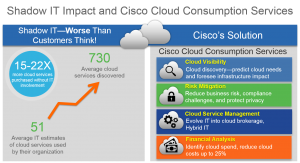
- Shadow IT (and how Cisco Cloud Consumption Services can help you here, SDN, and
- Software asset management,
Let’s now go on and discuss #6 … #10 … on topics from buzzwords, to SDx, and on to Scotch Whisky!
Here are my observations #6 .. #10 :
- New buzzwords abound. With the Cisco Visual Network Index (VNI) predicting traffic flow in the Zettabyte range by next year (2016), the next measurements will be called yottabyte and brontobyte!
- Software Defined Anything – “SDx” – was shown to be a complex area with multiple potential pitfalls including lack of SDx compatibility between vendors. After a prediction that 60% of Enterprises will adopt SDx from a top-down perspective (e.g. considering the whole SDDC), as opposed to the primarily “bottom up” (e.g. considering individually technologies areas such as SDN and SDS) approach of today, I was more than disappointed when the final two words in the presentation were “business need”. I wasn’t disappointed simply that these words were at the end, rather than in all the preceding tech-heavy discussion, “business need” didn’t appear at all! Business need should be consideration #1 in my view.
- The session entitled “Predicting Service Outages” was one of my top 3 picks of this conference. Most outages in IT shops today are caused by failed changes. Unfortunately this is the same as it was 10 years back when I travelled the world talking to various service provider network operations teams. I began to wonder if we’ve really progressed. A key point on outages, it was asserted, is how you track metrics around changes in your IT infrastructure (planned and un-planned), and how you track the relationship between outages and any preceding changes. It turns out most IT shops do not correlate trouble tickets to change events. Only 5% of poll participants said they “always” correlate incidents to past changes. This means that 95% are missing out on the real benefits of being able to use past change behaviour to predict the likelihood of outages in future events. This is such an opportunity for improvement, that wouldn’t require any new tools, and that would only take a small amount of effort to achieve significant returns in future IT services stability.
- “White box” IT was discussed from time to time. As one presenter said, “It’s ok for Google with huge $10Bn+ R&D budget.” Can a typical enterprise afford the integration and support costs that come from white box IT, from initiatives like OpenCompute and so on? Not many can at the moment, so let’s be realistic on how relevant white box switches and servers are to the majority of IT shops.
- Thanks to Sumerian, an innovative developer of capacity management tools, I learned that the highest concentration of whisky distilleries is in the north east of Scotland. Hic 🙂 ! [I knew it was in Scotland, however I had no idea of the number concentrated in this small region!]
Wrapping up then, I hope you found this and part 1 interesting. All in all, this was a good conference. If you attended, or are attending the US “version” this week (w/c 7 December), what were your key takeaways? I’d be keen to hear!
follow @StephenSatCisco





