
Part 2: Bridging the Gaps of Operationalizing AI and ML
In the first part of this blog, I reviewed the areas in which IT can support data science teams. This week, we’ll discuss the three major gaps that prevent enterprise from taking advantage of AI/ML and how to bridge them – with Cisco’s help.
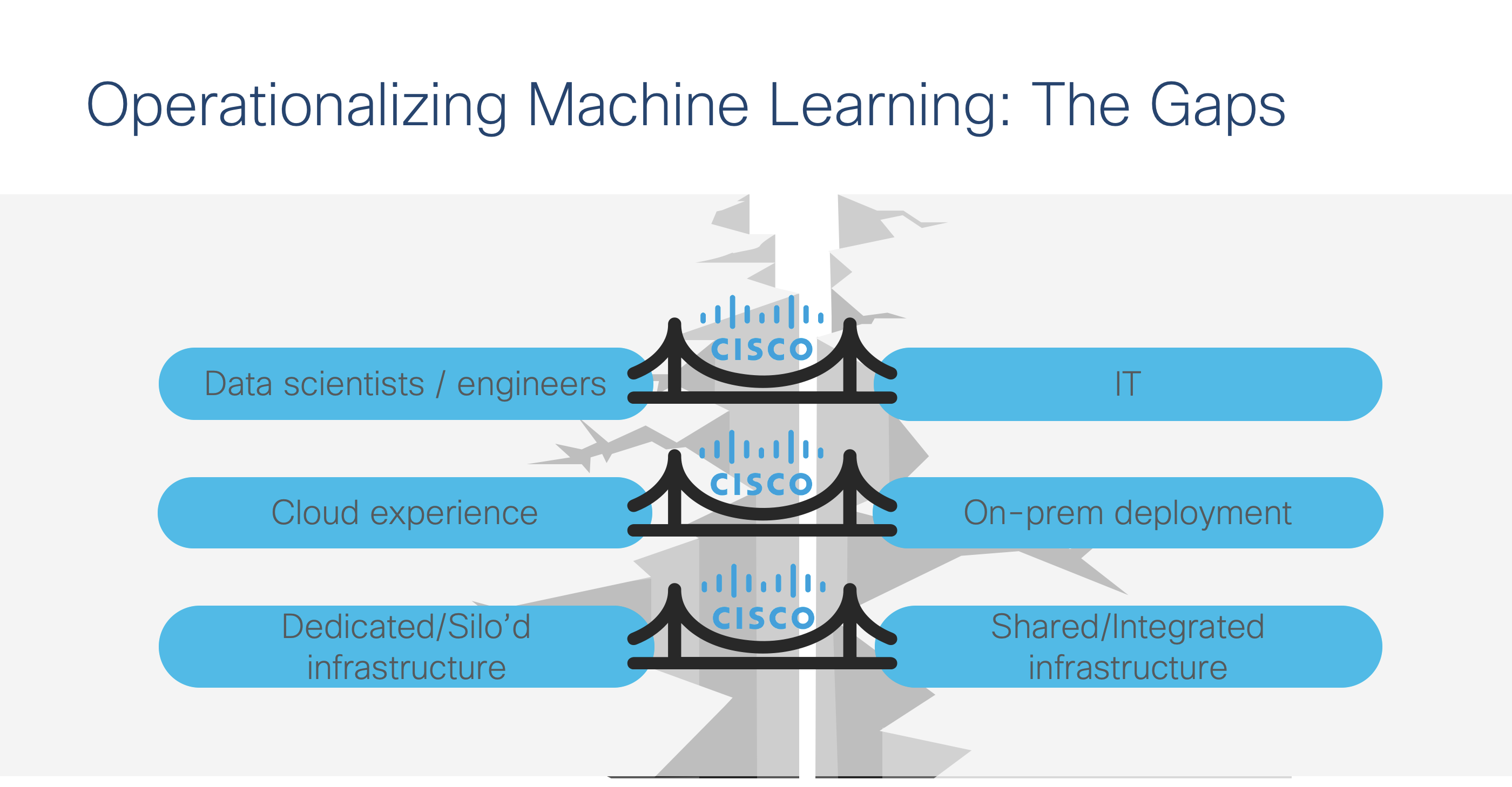
Data Science and IT Teams: Not Working Together
Earlier this year, at Cisco Live Barcelona, I had an opportunity to give multiple presentations at the World of Solutions area. When I asked the audience whether they knew how to deploy a virtual machine, almost everyone’s hands went up. As a follow-on question, I asked whether the audience knew how to deploy GPU enabled TensorFlow on a server, and almost nobody’s hand went up. Here’s the striking reality: IT teams may not know what hardware and software that the data scientists need. Without this knowledge, the two teams cannot effectively work together. That’s why we’ve crafted a variety of Cisco Validated Designs and Solution Briefs, in partnership with NVIDIA, Cloudera, Intel, and many others, to ensure that our customers have the right blueprint for accelerating AI/ML deployment with Hadoop, Kubernetes, hybrid cloud environments, and more. With the portfolio of networking and servers, infrastructure for the complete data pipeline can be architected, from the cloud to data center to the edge of the network. These offerings enable IT customers to have effective dialogues with the data science team.
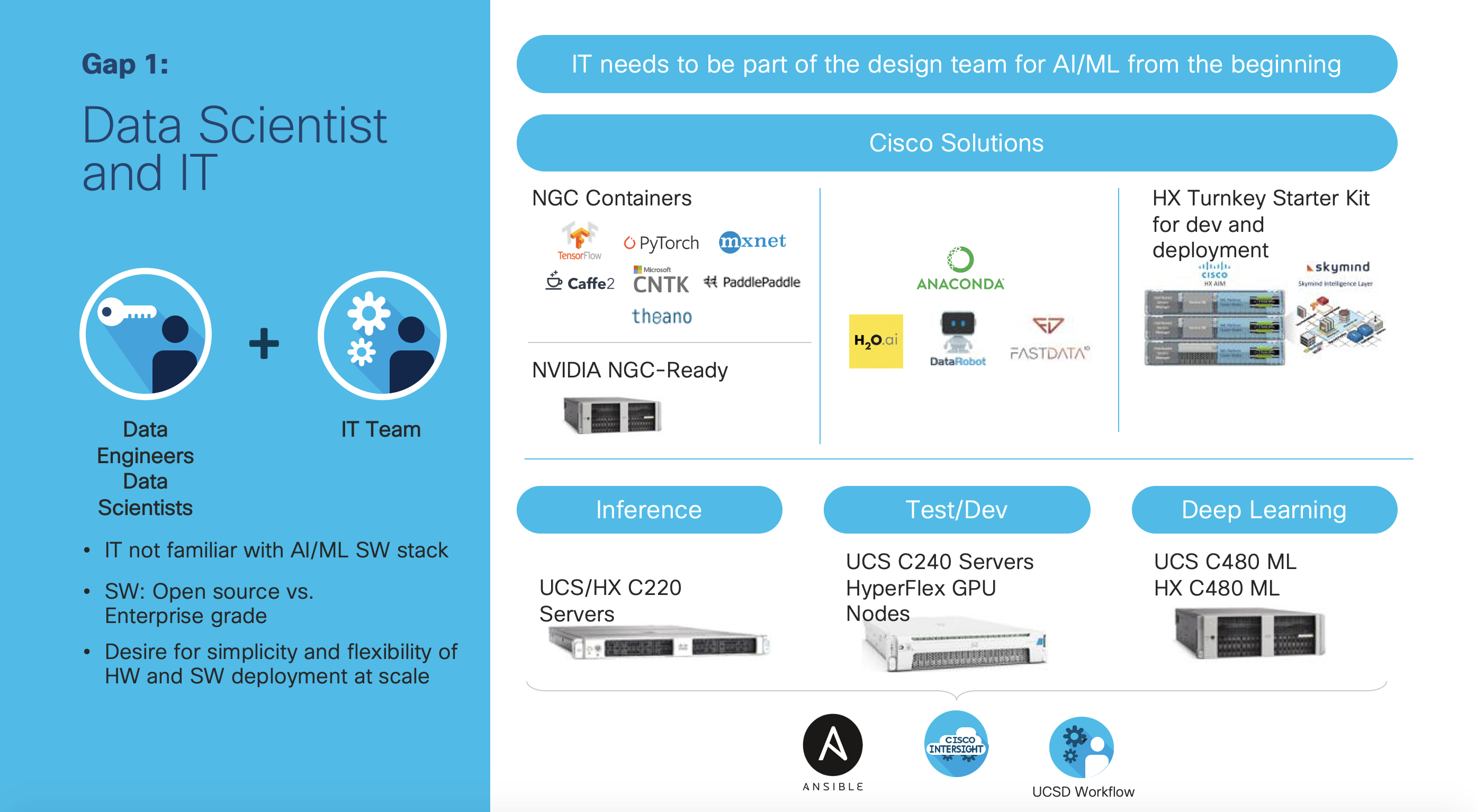
Consistent Cloud and On-Premise Machine Learning Experience
Because so many customers may start an AI/ML project in the cloud and find that they have even more data on-premise, they often ask about having a consistent machine learning experience for both on-premise and the cloud. Cisco has been the number two contributor to the Kubeflow open source project, just behind Google. Having Kubeflow enables data science teams to focus on the data pipeline, while the IT teams can have the proper infrastructure whether in the cloud, data center, or at the edge. To get started, check out Cisco Kubeflow Starter Pack that was announced just a few weeks ago.
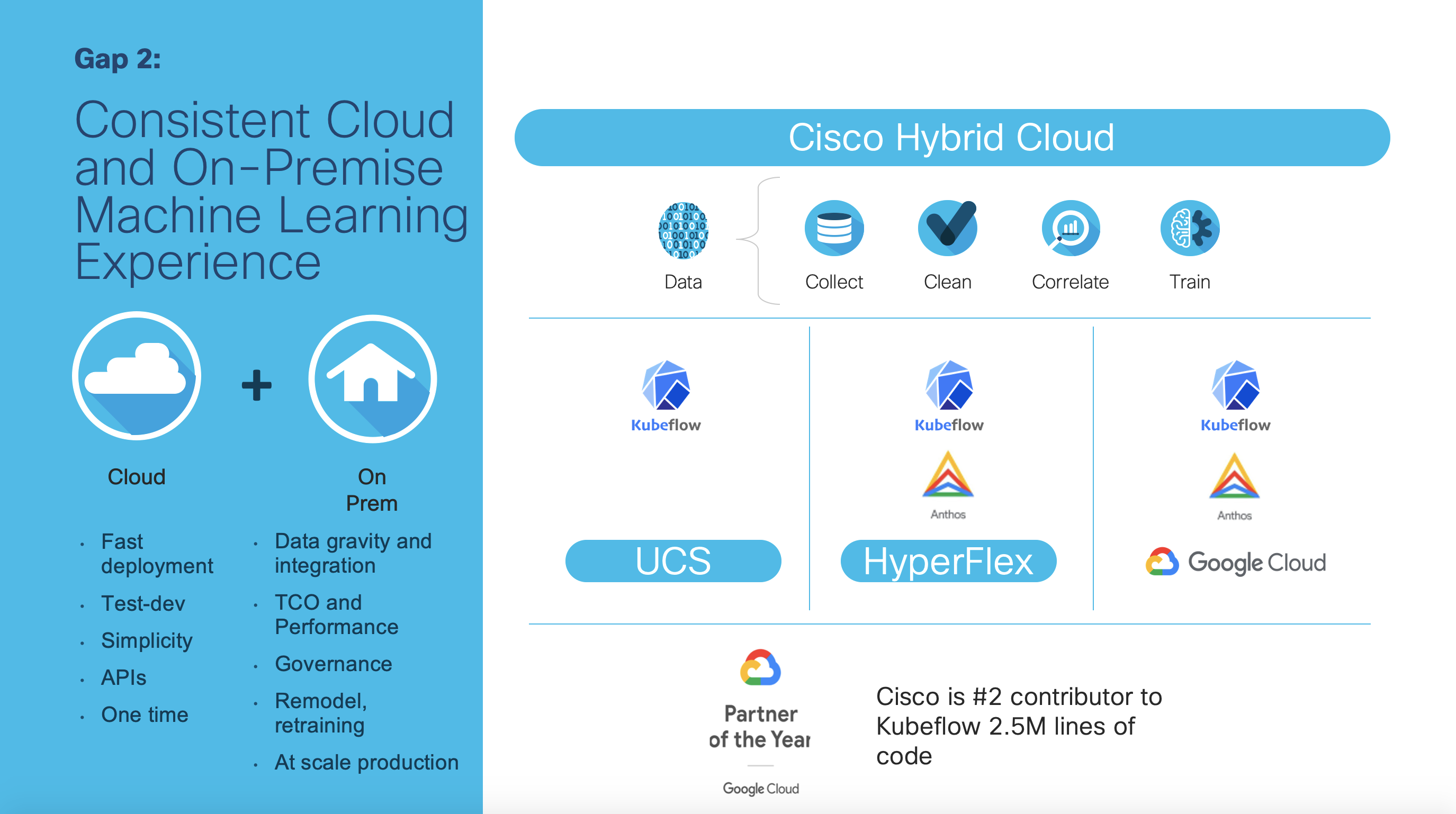
Dedicated vs. Shared Infrastructure
I have spoken with many data science teams who make it a practice to have GPU servers at their desk so that they have exclusive access. From an IT perspective, dedicated resources often have low utilization and difficulty justifying the added budget. As a result, Cisco has been working with a variety of partners, from VMware, Red Hat, and others, to create multiple cluster-wide solutions. For example, a Red Hat OpenShift cluster allows some resources to be dedicated and others to be shared. Hence, data science teams can have the dedicated resources for their own use, and have a pool of GPU resources to share when they want to do compute-intensive workloads, such as hyperparameter tuning. In a similar way, a cluster of HyperFlex with virtual GPU or PCI passthrough can also be shared and reserved for the data science team. With Cisco’s unified architecture, even mission critical applications, such as Oracle and SAP, run on the same architecture. These applications are important data sources for AI/ML, which is why IT, in using Cisco’s unified architecture, is able to create an architecture that can be scaled appropriately for both traditional enterprise applications as well as the latest AI/ML workloads. Cisco’s unifying architecture enables IT to accelerate AI/ML deployment, just as it has done with previous applications.
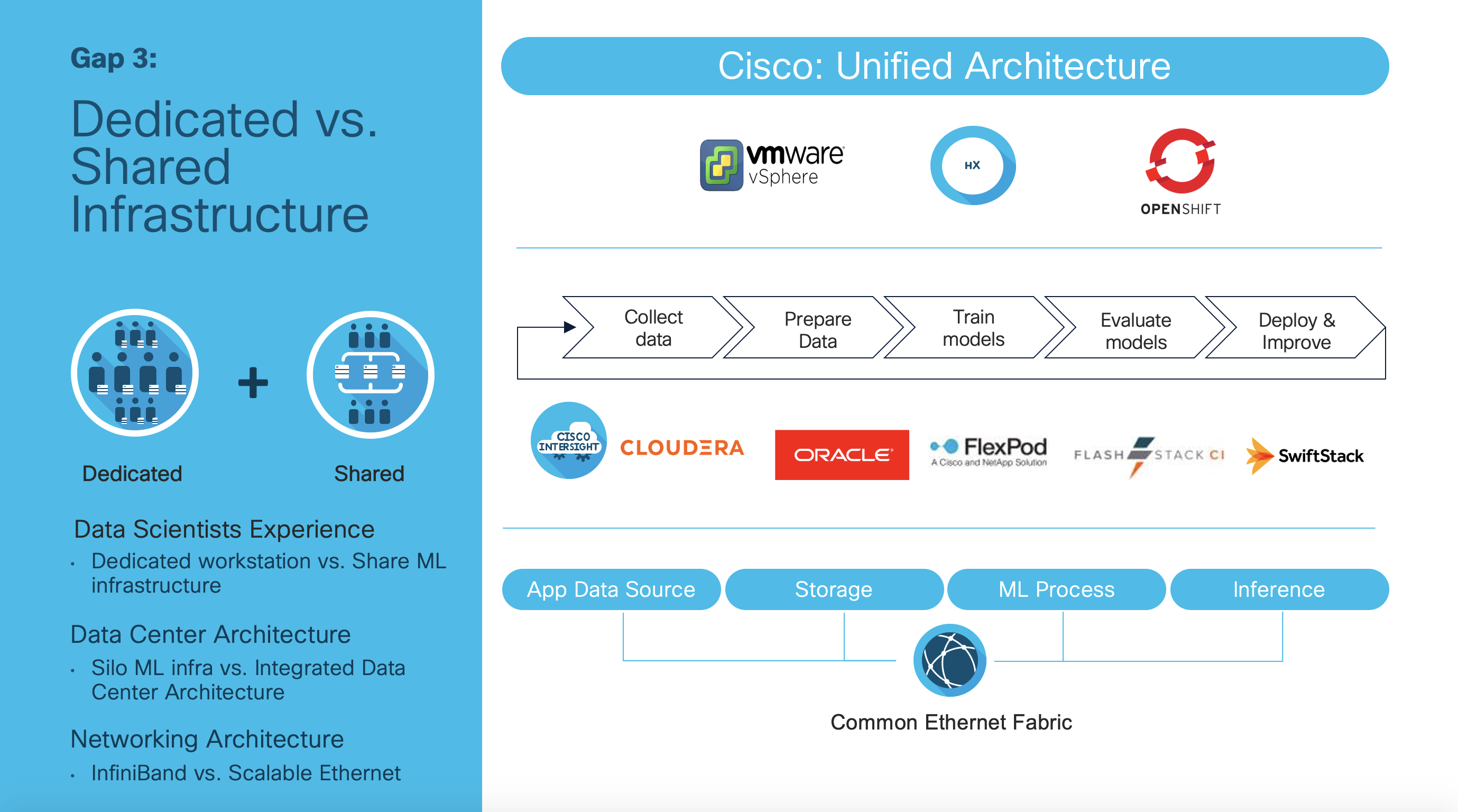
Cisco Tools to Help
Here are a set of tools to get you started in helping your data science team. Check out
Let your journey begin to help your data science team with AI/ML, and if you need help, please reach out to your Cisco account team!
@hanyang1234





