
Recently the Kubeflow Community released Kubeflow 1.0. Kubeflow brings together features such as TensorFlow, PyTorch, and other machine learning capabilities into a cohesive tool – from data ingestion to inferencing. Cisco is one of the top contributors to Kubeflow, helping to make operationalizing machine learning for large scale deployments easier for everyone. As a result, we are announcing Cisco Kubeflow Starter Pack.
Here are are the major components of Kubeflow 1.0:
Jupyter Notebook
Many data science teams live on Jupyter notebook since it allows them to collaborate and share their projects, with multi-tenant support. Personally, I use it to develop Python code because I like its ability to single step my code, with immediate results. Within the data science context, Jupyter becomes the primary user interface for data scientists, machine learning engineers.
TensorFlow and Other Deep Learning Frameworks
Originally designed to only support TensorFlow, Kubeflow version 1.0 now supports other deep learning frameworks, including PyTorch. These are two of the leading deep learning frameworks that customers are asking about today.
Model Serving
Once a machine learning model is created, the data science team often must create an application or web page to feed new data and execute the trained model. With Kubeflow, there are built-in capabilities with TFServing enabling models to be used without worrying about the detailed logistics of a custom application. As you can see in the screen shot below, the data pipeline enables data model to be served. In fact, the model can be called through a URL.
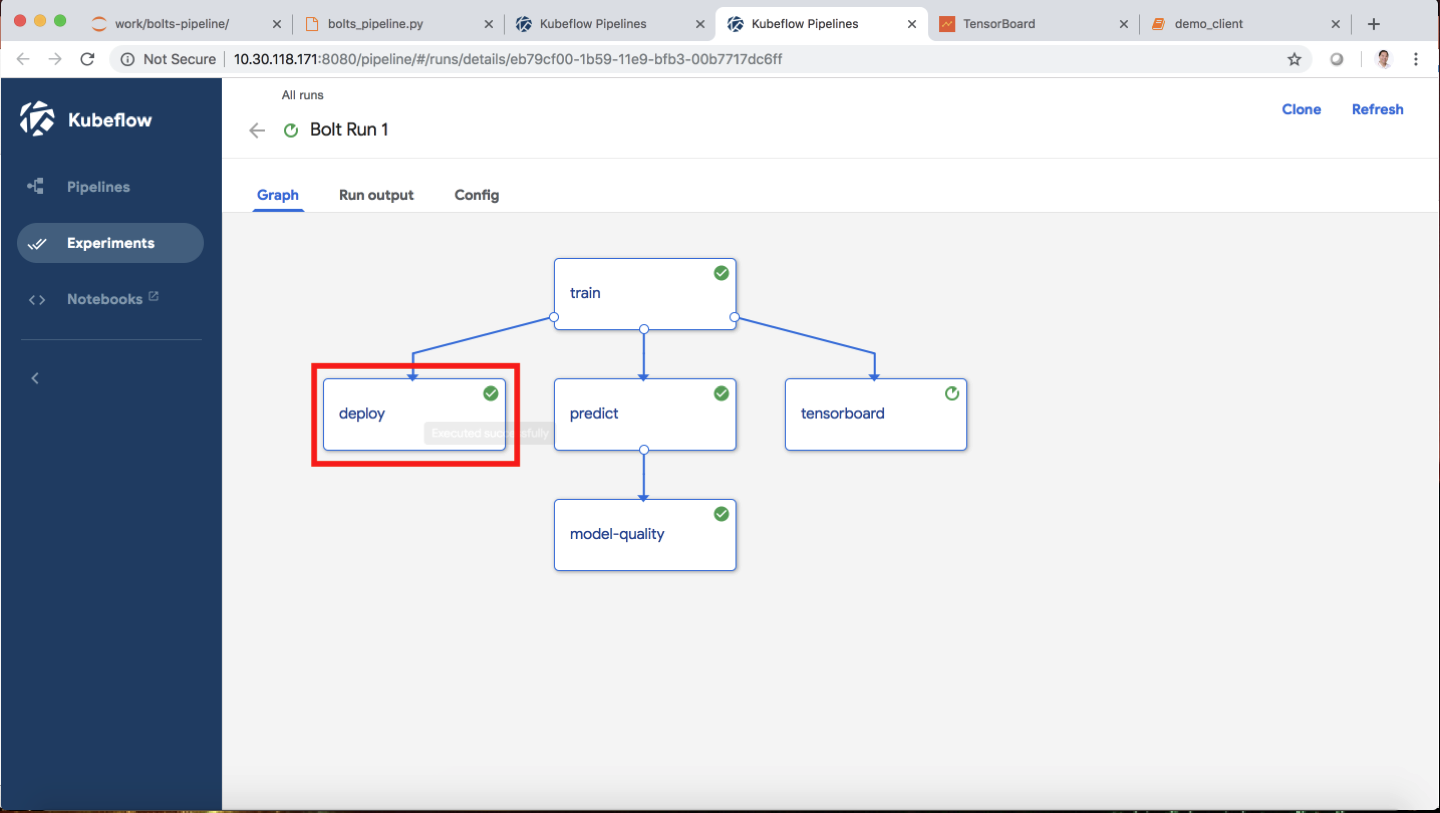
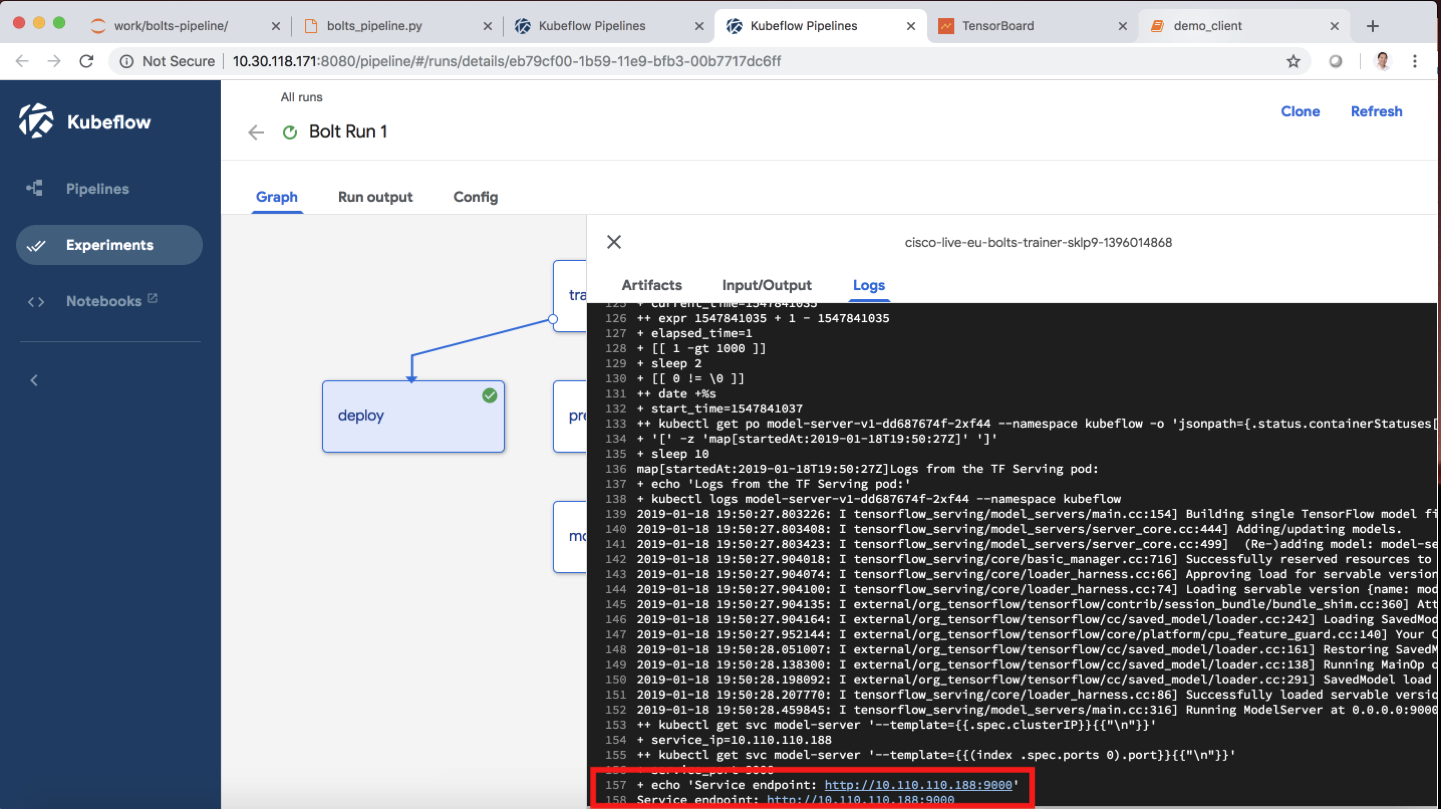
Other Components
There are many other components to Kubeflow, including integration with other open source projects that enable more advanced model inferencing, such as Seldon Core. The Kubeflow Pipelines platform, currently in beta, allows users to define a machine learning workflow from data ingestion through training and inferencing.
As you can see, Kubeflow is an open source integrated tool chain for data science teams. At the same time, Kubeflow enables the IT team to manage the infrastructure for the resulting data pipeline.
Cisco Kubeflow Starter Pack
To enable IT teams to work more closely with their data science counterparts, Cisco is introducing the Cisco Kubeflow Starter Pack, which provides IT teams with a baseline set of tools to get started with Kubeflow. The Cisco Kubeflow Starter Pack includes:
- Kubeflow Installer: Deploys Kubeflow on Cisco UCS and HyperFlex
- Kubeflow Ready Checker: Checks the system requirements for Kubeflow deployment. It also checks whether the particular prescribed Kubernetes distribution is able to support Kubeflow.
- Sample Kubeflow Data Pipelines: Cisco will be releasing multiple Kubeflow pipelines to provide data science teams working Kubeflow use cases for them to experiment with and enhance.
- Cisco Kubeflow Community Support: Cisco will be providing free community support for Cisco customers who would like to check out Kubeflow.
Get Involved
Check out the Cisco Kubeflow Starter Pack on Cisco DevNet. Join the community and provide feedback. We can’t wait to hear from you. For more information about Kubeflow, here are some additional resources.
@hanyang1234





