
In my previous post, I discussed the problem of spurious correlations. Today, we’ll explore how AI can fall prey to spurious correlations in the context of networking and how automation can help overcoming these limitations.
In the example we used in Part 1 of this series, we were in a train station, looking at the number of passengers on a platform (process A) and the arrival of a train (process B):
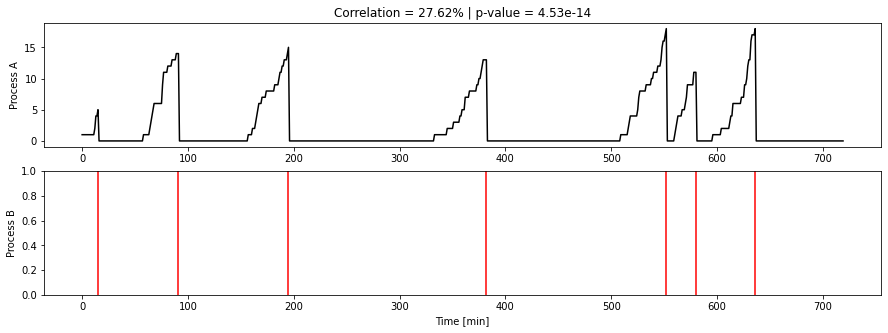
Deep learning algorithms (or any non-causal machine learning algorithm for that matter) only see data: they can’t understand and aren’t fed the (critical) information of what A and B represent. Common sense immediately allows us as humans to rule out a causal relationship between A and B, even when nothing in the data alone would prompt an algorithm to do so. This demonstrates a fundamental limitation of machine learning as an approach to machine intelligence.
Situations like our train example happen all the time in the analysis of networking telemetry. For instance, you may correlate the packet loss measured along a given path across the internet with the amount of traffic that a router of your organization is sending along the said path. This correlation may be high and its p-value close to zero. Despite these seemingly conclusive statistical values, they do not imply that the traffic congestion is causing the packet loss. Indeed, the congestion might simply be the result of global internet traffic patterns, which coincidentally corresponds to the same temporal patterns as the traffic of your organization. This is because they have a common cause, a third variable, C: the congestion and associated packet loss are driven by increased internet traffic created during business hours- going up during working hours and then down during nights and weekends. We can summarize this knowledge with the following causal diagram:
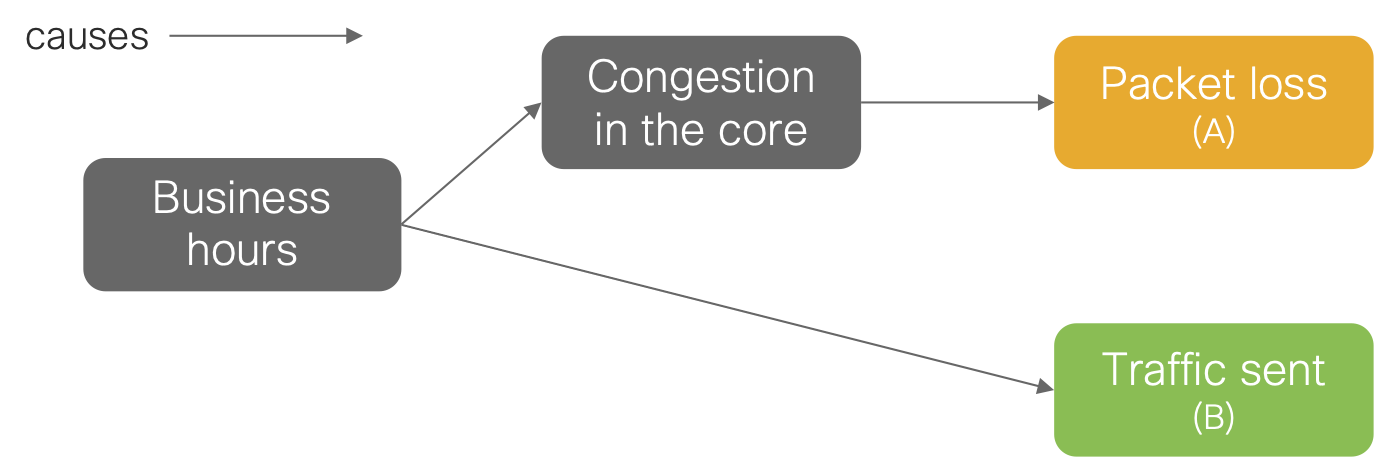
Now, here is the crux of the matter: had your traffic been sent along a different path, the congestion and packet loss would still have occurred. Going back to our train example, had the passengers not been on the platform, the train would have still arrived. A machine learning model trained on such data would predict that packet loss goes to zero when the traffic is low. However, you should not interpret such predictions as a causal claim such as “had the traffic been low, the loss would have been zero”. Instead, what the model tells you is: “in the data I have been trained on, the traffic is low whenever packet loss is high, and vice-versa”. The only way for an AI to truly ever articulate causal claims is by relying on an internal causal model, which one might call common sense.
The problem of endowing AI with common sense is a huge research topic! There are several ingredients that are key to get there, such as self-supervised learning, but this is a topic for another day. Today we focused on the most fundamental missing piece: the criticality of giving AI systems a way to interact with the world, that is, to perform interventions. This is not always possible of course: one cannot give an AI the ability to bring passengers on the platform, only to discover that (of course) no train will magically appear because passengers are waiting.
However, in networking, we have other approaches on hand. In our example of internet congestion, the system may use automation to send the traffic on a different path during a congestion event and validate whether the increased packet loss persists. If it disappears, then the system may indeed conclude that the extra traffic sent along this path was a cause of the congestion. This is an example of the criticality of automation in unlocking the potential of AI in networking, because it would allow such systems to discover true causal relationships. Understanding these causal relationships are foundational to developing truly self-healing networks.
In my next blog in this series, we’ll dive deeper into the problem of endowing AI with common sense and the research happening today in pursuit of that goal.
Subscribe to Analytics & Automation Blog
to receive new posts directly in your inbox!
Further reading and references
Pearl, J., & Mackenzie, D. (2018). The Book of Why: the New Science of Cause and Effect. Basic books.
Vigen, T. (2015). Spurious correlations. Hachette UK.
Deep learning, neural networks and the future of AI – TED talk by Yann LeCun where he talks about common sense.
The GitHub notebook used to produce the figures and examples in this article.





thanks alot of information
You are welcome Reyhan!