
In today’s climate of rapid innovation, it’s easy to find examples of companies leveraging data, analytics, and automation to increase revenue, cut costs, improve customer experience, develop new offerings, and achieve other goals. However, very little is written on how these companies operate differently at a time when the vast majority (~85%) of analytics projects fail.
Based on dozens of interviews with leaders in academia and Fortune 100 tech companies (many digital native and many not), as well as my own experience supporting digital transformation efforts within Cisco and its customers, I’ve concluded that the most significant differentiator between success and failure in digital transformation is not infrastructure or hiring, but rather the mindset of the organization and the culture it creates.
Silicon Valley is rife with myths (some of which are true) about how the digital giants operate differently to achieve higher rates of success. You may have heard that all Amazon employees are fluent in SQL and that data hoarding is a fire-able offense. Or that Google’s success is inseparable from its single data lake, (as opposed to the proliferation of databases which tend to occur in non-digital native companies) creating a common understanding of the facts so that competition is focused on insights as opposed to which data is more accurate.
Based on these findings, I’m proposing the following Data Science & AI Hierarchy of Success (based on Maslow’s Hierarchy of Needs and adapted from current versions of the Data Hierarchy of Needs) for which the first and most critical layer is mindset, comprised of Data Literacy and Democratization.
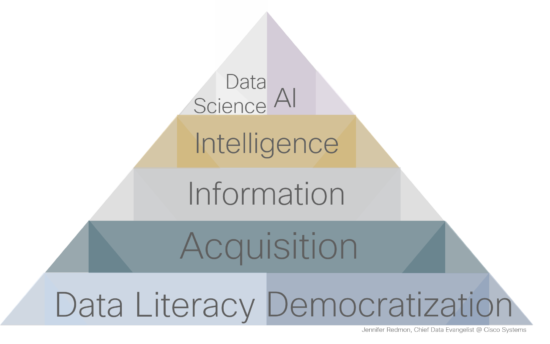
Level 1: Mindset
Data Literacy: As I introduced in a prior blog, high Data IQs are essential for employees at all levels to not only transform the data they have today into insights but to build for the future. Cisco’s DevNet is a great example of this foundational layer as it provides training along with a plethora of tools, creating a highly Data Enabled community, in which partners can easily develop value-add services on top of network data.
Data Democratization comprises access and curation (also referred to as stewardship). The first does not imply that security requirements such as GDPR and network segmentation should be ignored but rather that they set the boundaries within which each employee should be granted access. Without this, individuals are limited to assumptions, conjecture, and ignorance. Data Stewardship is a force multiplier within the enterprise because when data is curated upstream, employees can use the highest quality, most trustworthy data from their initiative or project’s start- minimizing front-end cleanup, which consumes a whopping 80% of data scientists’ time today. Stewardship also implies that companies need to get serious about discarding low quality data when more useful data exists. Some data may be gold, but a fair amount is fool’s gold, too.
Level 2: Acquisition
Most versions of the Data Hierarchy of Needs refer to this level as “Collection,” however, collected data is only one of many options. Intelligent data collection, by which I mean automated and sensor-based, remains the holy grail of data acquisition, (i.e. Uber using your phone’s GPS to determine your precise location), equally useful data can be obtained via alternate methods. Enterprises can purchase data and/or create new value propositions to its partners and customers in which services are provided in exchange for data, as Facebook and Google do. Knowing which data to acquire and developing a strategy to do so is a critical element of the digital giants’ mindset and culture.
Making the transition to a culture which fuels digital transformation and innovation isn’t an easy feat, but its dividends are astronomical. Below are a few things you can do to get started:
- Assess your team members’ Data IQ and Data Enablement. Are they Data-Driven? Data Illiterate? Enthusiasts? Siloed High Performers? Even if you lack the perfect assessment tool, opening this dialogue may lead you to valuable insights.
- Establish a company-wide data literacy program. Not sure where to get started? Check out The Data Literacy Project.
- If poor data quality is a barrier to analytics-driven decisions, implement positive feedback loops in which individuals with deep domain understanding can help data owners improve their data’s quality.
- Enable data sharing via platforms, processes, and permissions. Doing so will create opportunities for employees to uncover insights that may be masked by organizational or procedural silos today.
- Give data a seat at the table when making decisions. If the data isn’t available, understand why and begin making the requisite changes. Start with the data supporting the most business impacting decisions to maximize the return on these efforts, both financially and culturally.
Interested in the rest of the pyramid? Continue to Part 2 of this post: “Is Data Science a Pre-Requisite for AI? The Data Science & AI Hierarchy of Success“.




