
Prologue
The Compressed Pcap Packet Indexing Program (cppip) is a tool to enable extremely fast extraction of packets from a compressed pcap file. This tool is intended for security and network folk who work with large pcap files. This article provides a complete discussion of the tool and is split into two parts. The first part, intended for end-users, will explain in detail how to build and use the tool. The second part, intended for C programmers, covers cppip’s inner workings.
Introduction
Cppip is a command line utility designed to make packet extraction from large pcap files extremely fast — without having to uncompress the entire file. It relies on pcap files that have been compressed using the freely available bgzip, a backward compatible gzip utility that boasts a special additive — the ability to quickly and cheaply uncompress specific regions of the file on the fly. You will find cppip quite useful if you work with large pcap files and have the need to extract one or more packets for subsequent inspection. As you’ll see, preparing your pcap files for use with cppip is a two step process of compressing the pcap file with bgzip and then indexing it with cppip. But before you can use cppip, you first have to install it.
Installation
Cppip is distributed with a GNU autoconf script intended to make your life easier. Those of you familiar with autoconf-scaffolded tools are familiar with the `./configure && make` sequence of commands for configuring and building such packages. In cppip’s case however, one of the core dependencies, the tabix library, does not neatly install itself on the host operating system without some intervention. Because the tabix maintainer does not employ GNU’s powerful autoconf framework, you have to do a bit of prep-work before cppip can be built and installed. To do so, follow these easy steps:
- Download cppip: Cppip lives at GitHub and can be found here.
- Download and build tabixtools: Download the most recent version of the tabix toolkit (at the time of this writing that is 0.2.6):
[sb:~]$ curl -O http://superb-dca2.dl.sourceforge.net/project/samtools/tabix/tabix-0.2.6.tar.bz2It contains the bgzip utility as well as libtabix.a, a simple static C library that contains all of the bgzip functions. To build and use cppip, you’ll need both (bgzip will be used to compress your pcap files and you’ll need the library against which to link the cppip tool). After uncompressing and unarchiving, go ahead run `./configure && make` to build the tool and library. Unfortunately, the tabix maintainers did not include an install target in their Makefile so you can’t just run `make install` and have everything deposited where you need it. Because of this, it is recommended that you copy bgzip somewhere in your $PATH so it is convenient to use (/usr/local/bin or /opt/local/bin are probably good choices). It is also because of the lack of the install target that you have to perform the next two steps:
- Tell cppip’s configure script where the libtabix.a library lives:Here are two easy options: either copy libtabix.a to something like /usr/local/lib where the configure script will find it:
[sb:tabix-0.2.6]$ sudo cp libtabix.a /usr/local/libOr if you don’t have root privileges or don’t plan to use libtabix.a again, you can pass the fully qualified path of where you built libtabix.a (usually this will be something like “tabix-0.2.6”) to cppip’s configure script. For example, if you built tabixtools in the directory adjacent to cppip as per the following:
[sb:cppip]$ ls cppip tabix-0.2.6Then you will invoke configure with something like:
[sb:cppip]$ ./configure LDFLAGS=-L/Users/mike/Code/cppip/tabix-0.2.6/ - Inform configure where bgzf.h is kept: In much the same vein as above, if you plan to use libtabix.a again you can copy it to /usr/local/include where configure will find it:
[sb:tabix-0.2.6]$ sudo cp bgzf.h /usr/local/includeOtherwise you can pass another argument to configure to tell it where to find the header file:
[sb:cppip]$ ./configure CPPFLAGS=-I/Users/mike/Code/cppip/tabix-0.2.6/ - Invoke configure with the added options:You can indicate both sets of flags with something like:
[sb:cppip]$ ./configure CPPFLAGS=-I/Users/mike/Code/cppip/tabix-0.2.6/ LDFLAGS=-L/Users/mike/Code/cppip/tabix-0.2.6/ - Build cppip: Now run `make`.
The Tool: CPPIP
You’ll be working with the first official release of cppip, version 1.3. Before you dive into some examples, let’s first explore all of the options you can specify when using the tool, to do that, invoke cppip with the -h switch:
[sb:cppip] $ ./src/cppip -h
Compressed Pcap Packet Indexing Program
(c) Cisco Systems 2013, Inc
Mike Schiffman
Fast compressed pcap indexing and extraction, made easy
see http://blogs.cisco.com/tag/cppip for complete documentation
Usage: cppip [options] [file(s)...]
Indexing:
-i index_mode:index_level index.cppip pcap.gz
index a bgzip compressed pcap.gz file using `index_mode`
index.cppip will be created or overwritten and packets
will be indexed at every `index_level` mark.
invoke with -I for more information/help on indexing
-I print supported index/extract modes/format guidelines
-v index.cppip verify index file
-d index.cppip dump index file
Extracting:
-e index_mode:n|n-m index.cppip pcap.gz new.pcap
extract using `index_mode` the nth packet or n-m packets
from pcap.gz into new.pcap
invoke with -I for more information/help on extracting
-f enable fuzzy matching (timestamp extraction only)
General Options:
-D enable debug messages
-V program version
-h this message
Let’s talk through some of the main options:
- -i (index) Typically, this is the first step — you’ll create one index file for every pcap.gz
- -e (extract) This mode is used when you want to extract one or more packets from the pcap.gz
- -I (print modes) This option displays supported indexing modes
- -v (verification) This option is used to verify an index file was built correctly, check its version, and see how many records it has
- -d (dump) This option dumps the entire index file
- -f (fuzzy matching) This option allows for fuzzy matches when extracting in timestamp mode (more on this later)
- -D (debug) Enable debug messages
Compressing the Pcap
First things first. We need to compress your monster pcap file using bgzip. Sidebar: in the following examples, in order to obtain information about what’s inside a pcap file (compressed or not), we will use Wireshark’s capinfos tool. For all following examples we will use a 2GB pcap file containing just over 7.5M packets:
[sb:cppip]$ ls -l *.pcap -rw-r--r-- 1 mike staff 2000000101 Apr 19 20:43 pktdump.pcap [sb:cppip]$ capinfos -cuae pktdump.pcap.gz File name: pktdump.pcap.gz Number of packets: 7552072 Capture duration: 411 seconds Start time: Fri Apr 19 16:56:44 2013 End time: Fri Apr 19 17:03:35 2013
For reference, you’ll notice the pcap compresses with plain old gzip to about 892M:
[sb:cppip]$ ls -l *.pcap*
-rw-r--r-- 1 mike staff 838087510 Apr 19 20:43 pktdump.pcap.gz
Compressing a file with bgzip will introduce some overhead, in our case only about 7% at 838M:
[sb:cppip]$ bgzip pktdump.pcap [sb:cppip]$ ls -l *.pcap* -rw-r--r-- 1 mike staff 892089319 Apr 19 20:43 pktdump.pcap.gz
Packet Indexing
Once you’ve compressed the file, you’ll need to index it with cppip. When indexing, cppip will create a companion file that will contain bgzip offsets for packets in pcap.gz. In other words, the index file will hold addresses to packets that live in the compressed pcap. These addresses will subsequently be used to rapidly extract packets later on.
Currently, cppip supports two modes of indexing: packet number and timestamp. The packet number mode indexes packets via their ordinal position in the pcap file while the timestamp mode indexes packets by their pcap header timestamp. Deciding which mode to use to build the index is going to be tied to how you expect to need to extract packets. We’ll learn more about both in the next few sections.
After you decide on an index mode, you’ll need to choose an index level. This is a value that indicates for how many packets cppip will store addresses. In a perfect world, you could choose the smallest possible index level and in some cases store the address of every single packet and have near instantaneous look-ups. This would also result in a very large index file. In practice, the index level will be a larger value that offers a good balance between index file size and look-up speed. To see how cppip expects an index level to be specified, invoke cppip with the -I option:
[sb:cppip] $ ./src/cppip -I
pkt-num: index_level should be a single integer from:
1 - (total number of packets - 1)
To index every 1000 packets: -i pkt-num:1000
timestamp: index_level should be a number indicating the index
followed by a time range specifier which can be one of
following:
d - days
h - hours
m - minutes
s - seconds
To index every 100 seconds: -i timestamp:100s
Packet Indexing via Packet Number
When choosing a packet number index level, you need to consider the number of packets in the pcap.gz and decide which is more important: disk space or execution speed. A smaller index level translates into more packets being indexed and results in a bigger index file. For pcap files with a large of number of packets, this will result in a very sizable index file. The benefit here is faster seek times since the more granular the indexing, the closer, on average, cppip will be able to get to your target extraction (we’ll see this in action shortly). If you choose the smallest possible index level of 1, you’re telling cppip “please store the address of every packet in my index file” and it will dutifully write an index record for every packet in the pcap. This will result in the largest possible index file and fastest possible extractions since cppip will know the address of every single packet and can seek directly to the index record containing the BGZF offset for the desired packet. In practice, you’ll probably want to choose something that offers a balance in terms of index file size.
In the following example, we’ll index the pcap.gz file using a reasonable index level of 1,000, which results in a 120K index file:
[sb:cppip]$ ./src/cppip -i pkt-num:1000 index-pn-1000.cppip pktdump.pcap.gz indexing pktdump.pcap.gz... wrote 7552072 records to index-pn-01.cppip [sb:cppip]$ ls -l index-pn-1000.cppip -rw-r--r-- 1 mike staff 120876 Apr 15 12:03 index-pn-1000.cppip
Packet Extraction via Packet Number
Now that you’ve got your index file built, you can actually get some work done! Say you have a pressing need for packets 3,480,123 through 4,080,012 from deep inside that pcap.gz. The infographic below depicts this typical workflow scenario:
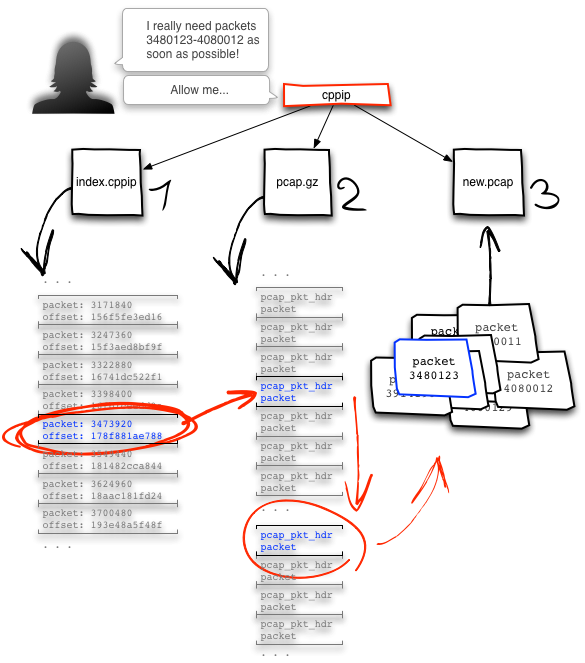
- Cppip consults in the index file: Using the specified packet range, cppip looks inside the index file to find the closest BGZF offset of the starting packet. If cppip is lucky enough to land directly on a packet index, it will know the exact address of where your desired packet range begins inside pcap.gz. If not, as is the case above, it will get as close as possible. This works because packets are stored in a sequential, monotonically increasing fashion. So cppip knows that packet number 3,473,920 is the closest antecedent neighbor that it knows the address for to the desired starting packet of 3,480,123.
- Cppip indexes directly into pcap.gz: Using the BGZF offset obtained from the index file query, cppip will directly seek to that address in the pcap.gz and do a linear search to find the desired starting packet.
- Cppip writes the packets to new.pcap: Once it finds the starting packet, cppip will copy over the original 24-byte pcap file header and then write to new.pcap each packet in the specified range.
Let’s see what this looks like at the command line, and so you have an idea of how long this takes, let’s time it:
[sb:cppip] $ time ./src/cppip -e pkt-num:3480123-4080012 index-pn-1000.cppip pktdump.pcap.gz new.pcap
wrote 599890 packets to new.pcap
1.42 real 0.56 user 0.84 sys
Sweet. Using the packet number index file with records every 7,552 packets on my admittedly speedy MacBook Pro it took cppip less than one and a half seconds to locate, read, and write almost 600,000 packets. For good measure, let’s check cppip’s work:
[sb:cppip] $ capinfos -c new.pcap
File name: new.pcap
Number of packets: 599890
Looks good! Using packet number indexing, cppip can extract a single packet, or a range of packets from a compressed pcap file. Next we’ll move on and have a look at cppip’s timestamp indexing and extraction capabilities.
Packet Indexing via Timestamp
Timestamp indexing indexes packets based on their capture timestamp in the pcap file. Cppip will be keying packets based on when they arrived in the pcap.gz file rather than their relative position in the file. While packet timestamps will almost always increase, we can’t rely on them to do so monotonically. When choosing a timestamp index level, you need to be cognizant of the duration of your capture file.
Currently, as of version 1.3, the smallest value you can choose for a timestamp index level is 1 second. Let’s have a look at the standard workflow for timestamp based indexing and extraction:
Since we know the pcap.gz file spans the relatively short timeframe of 411 seconds, let’s create an index file using the smallest possible index level of 1 second which will result in a tiny index file of 411 records:
[sb:cppip]$ ./src/cppip -i timestamp:1s index-ts-1s.cppip pktdump.pcap.gz indexing ../pktdump.pcap.gz... wrote 411 records to index-ts-1s.cppip [sb:cppip]$ ls -l index-ts-1s.cppip -rw-r--r-- 1 mike staff 9920 Apr 20 16:21 index-ts-1s.cppip
Packet Extraction via Timestamp
While you can’t specify microsecond resolution for packet indexing, you have that option for extraction. You can specify timestamps with or without microseconds:
- With microseconds: YYYY-MM-DD:HH:MM:SS.uuuuuu
- Without microseconds: YYYY-MM-DD:HH:MM:SS
Let’s take a look at another typical cppip use-case. In this scenario, your stalwart Cisco IPS has informed you of a break-in attempt that happened at 5:00pm, local time. Your internal forensic team wants all network traffic from 4:59pm to 5:02pm. Since you had previously setup an automated process that bgzip compresses and cppip indexes all of your perimeter pcap files, you’re all set to handle this request. Let’s grab all packets from one minute before the incident and two minutes afterwards:
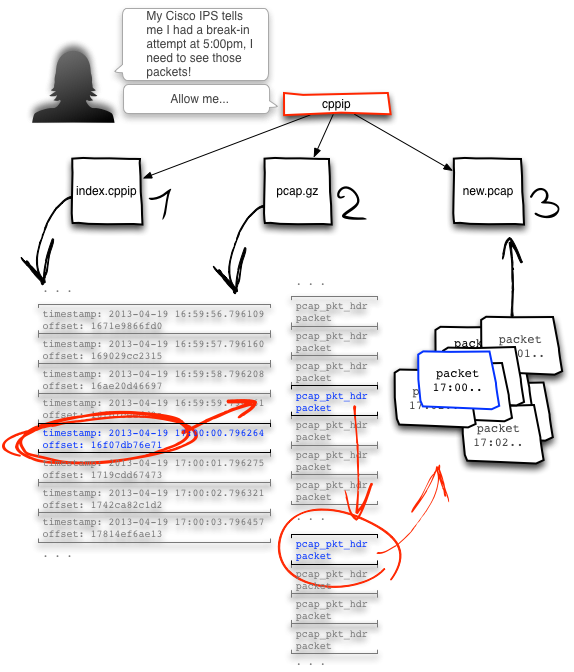
The command line for this looks like:
[sb:cppip] $ ./src/cppip -e timestamp:2012-10-07:16:59:00-2012-10-07:17:02:00 index-ts:1s pktdump_20121008000335.pcap.gz new2.pcap
extracting from pktdump.pcap.gz using index-ts:1s...
extract(): 2013-04-19 16:59:00.000000 not found, closest is 2013-04-19 16:59:00.000102 (try -f)
wrote 0 packets to new2.pcap.
Huh. What happened here? Evidently we didn’t specify a specific enough timestamp for cppip to match a corresponding starting packet. To solve this, you have two options:
- Specify the specific timestamp: Cppip was kind enough to tell you the closest matching timestamp to your request so you could just use that one. However, it’s likely you’ll run into the same problem with the closing timestamp (this is, however, a useful way to capture all packets from a starting timestamp until the end of the pcap.gz).
- Use fuzzy matching: With this handy option, cppip will look for the specified timestamp, but if it can’t find it, cppip will start and stop matching on the timestamps closest to the ones specified at the command line. Let’s try that.
[sb:cppip] $ ./src/cppip -f -e timestamp:2012-10-07:16:59:00-2012-10-07:17:02:00 index-ts:1s pktdump_20121008000335.pcap.gz new2.pcap
extracting from pktdump_20121008000335.pcap.gz using index-ts:1s...
start ts: 2012-10-07 16:59:00.000000 not found, instead fuzzy matched on 2012-10-07 16:59:00.000102
stop ts: 2012-10-07 17:02:00.000000 not found, instead fuzzy matched on 2012-10-07 17:02:00.000046
wrote 3461342 packets to new2.pcap.
Awesome! You’ve got your packets and it’s time for some forensic analysis.
Finally, let’s explore some of cppip’s diagnostic functionality.
Packet Verification and Index Dumping
Cppip offers some diagnostic functionality that will give you an opportunity to look inside the index file to ensure its validity and explore its contents. The first is a simple command that verifies the index file and displays some of its metadata:
[sb:cppip] mike% ./src/cppip -v index-pn-1000.cppip
valid cppip index file
version: 1.3
created: 2013-04-19 20:03:17.463926
packets in pcap:7552072
indexing mode: packet-number
index level: 1000
record count: 7552
We see that our index file is pretty much as expected. One takeaway here is to ensure the version of the index file you’re using is in-line with version of cppip. I can promise I’ll try to make future versions backward compatible, but as with all things, your mileage may vary.
The other nifty diagnostic feature cppip exposes is an option to dump the contents of the index file. This is useful if you want to see how the packets are physically laid out inside your pcap.gz:
[sjc-vpn5-288:~/Code/cppip/cppip] mike% ./src/cppip -d index-pn-1000.cppip |& more
valid cppip index file
version: 1.3
created: 2013-04-19 20:03:17.463926
packets in pcap:7552072
indexing mode: packet-number
index level: 1000
record count: 7552
pkt num:1000
offset: 153b9d4c5
pkt num:2000
offset: 30e3bae9f
pkt num:3000
offset: 4dadb7482
pkt num:4000
...
That wraps up the user manual, so let’s move on to have a look at how cppip does what it does.
Under the Hood
As I’ve done in the past, in all of my technical blogs where I release code, I like to choose some linchpin code block and discuss it. So how does cppip do what it does? Let’s find out! We’ll have a look under the hood at the index file header, the index record and a few of the functions used to extract the index.
The Packet Number Index Record
Since we’re going to explore the indexing and extraction process for the packet number mode, it’s only fitting that we open with a look at the packet number index record. As you would expect, it’s a pretty simple structure. It has room for an unsigned 32-bit counter for the packet number and a 64-bit address into the pcap.gz:
/* * Packet Number Index Record: * * 0 1 2 3 * 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 * +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ * | Packet Number | * +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ * | Virtual BGZF Virtual Record Locator | * | | * +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ */ struct cppip_record_pn { uint32_t pkt_num; /** the packet number */ uint64_t bgzf_offset; /** its offset into bgzf file */ }; typedef struct cppip_record_pn cppip_record_pn_t; #define CPPIP_REC_PN_SIZ sizeof(struct cppip_record_pn)
Packet-Number Indexing
The next block is the main event loop for building the index file. You’ll notice the first thing cppip does is obtain the current address of the file pointer into the pcap.gz. Not shown is the code block that already read and wrote out the pcap file header, so for the loop’s first iteration, the call to bgzf_tell() will reflect the fact that cppip has already read those bytes. After reading a packet and ensuring it didn’t encounter an error or end of file, cppip checks to see if it’s got the first packet in the pcap or (via the modulo operator) one that is a multiple of the index level. If either state is true, cppip will write the packet number, offset to the index file, and bump a few counters. If debugging is enabled, the you’ll get a nice message informing you what just happened. The next block simply skips the contents of the packet — cppip doesn’t care about them while it’s indexing. This process repeats until an error is encountered or cppip reaches the end of the pcap.gz.
for (rec_cnt = 0, pkt_cnt = 1, done = 0; !done; pkt_cnt++) { /** ...[pcap packet header][packet]... * ^ * bgzf fp is pointing here, the BGZF offset to this * packet.. This is * the offset we will record in our index */ offset = bgzf_tell(c->pcap); switch (bgzf_read(c->pcap, buf, PCAP_PKTH_SIZ)) { case -1: snprintf(c->errbuf, BUFSIZ, "bgzf_read() error\n"); return (-1); case 0: /* all done */ done = 1; break; default: pcap_h = (pcap_offline_pkthdr_t *)buf; /** write first packet then write as per index_level */ if (pkt_cnt == 1 || pkt_cnt % c->index_level.num == 0) { cppip_rec.pkt_num = pkt_cnt; cppip_rec.bgzf_offset = offset; if (write(c->index, &cppip_rec, CPPIP_REC_PN_SIZ) == -1) { snprintf(c->errbuf, BUFSIZ, "write(): %s", strerror(errno)); return (-1); } rec_cnt++; if (c->flags & CPPIP_CTRL_DEBUG) { fprintf(stderr, "DBG: add> [%d]: %d @ %llx\n", rec_cnt, pkt_cnt, offset); } } /** * we don't care about the contents -- we skip past the * packet */ if (bgzf_skip(c->pcap, pcap_h->caplen) == -1) { snprintf(c->errbuf, BUFSIZ, "bgzf_skip() error\n"); return (-1); } } }
Packet-Number Extraction
The extraction logic is responsible for getting you your packets. Let’s see how it works. First of all cppip wants to make sure you didn’t screw up at the command line and specify a stop packet that exceeds the total number of packets in the pcap.gz. If your input passes that test, cppip will then set itself to locating the start packet. If the start packet is smaller than the index level, cppip will issue a linear search from the very first packet until it reaches the specified starting packet. If the start packet is larger than the index level, cppip will divide the first packet by the index level to obtain the closest index record and then lseek() to that location in the index file. Next, cppip reads that record, seeks to the appropriate location in the pcap.gz, and again executes a linear search until it finds the start packet. Cppip then descends into the extraction loop, reads the pcap header to obtain packet capture length, and then reads the packet itself. It then copies both the pcap header and packet to a memory buffer and writes that buffer to the new pcap file. Cppip continues this process until it hits the stop packet or encounters an error.
/** sanity check only checks stop, we verified earlier stop > start */ if (c->e_pkts.pkt_stop > c->cppip_h.pkt_cnt) { snprintf(c->errbuf, BUFSIZ, "extraction would exceed packet count, %d and/or %d > %d\n", c->e_pkts.pkt_start, c->e_pkts.pkt_stop, c->cppip_h.pkt_cnt); return (-1); } /** * We need to locate the offset of pkt_start and then we can * extract in a linear fashion until we hit pkt_last. * * If the indexing is too coarse the pkt_start will lie before the * first index. If this is the case we have to do a linear search from * the very first packet until we find pkt_first... */ if (c->e_pkts.pkt_start < c->cppip_index_pn_hdr.index_level) { if (linear_search(c, 1, c->e_pkts.pkt_start) == -1) { return (-1); } } /** seek to index, obtain closest offset, linear search from there */ else { /** * pkt_start / index_level will give us the closest index record to our * starting packet. We lseek to 1 before this location so we don't * step past the record we need. */ if (lseek(c->index, (((c->e_pkts.pkt_start / c->cppip_index_pn_hdr.index_level) - 1) * CPPIP_REC_PN_SIZ) + CPPIP_FH_SIZ + CPPIP_INDEX_PN_H_SIZ, SEEK_SET) == -1) { snprintf(c->errbuf, BUFSIZ, "lseek() error: %s\n", strerror(errno)); return (-1); } if (read(c->index, (cppip_record_pn_t *)&rec, CPPIP_REC_PN_SIZ) != CPPIP_REC_PN_SIZ) { snprintf(c->errbuf, BUFSIZ, "read() error: %s\n", strerror(errno)); return (-1); } if (bgzf_seek(c->pcap, rec.bgzf_offset, SEEK_SET) == -1) { snprintf(c->errbuf, BUFSIZ, "bgzf_seek() error.\n"); return (-1); } if (linear_search(c, rec.pkt_num, c->e_pkts.pkt_start) == -1) { return (-1); } } /** we've got pkt_first, do extraction until we hit pkt_last */ for (c->e_pkts.pkts_w = 0, i = c->e_pkts.pkt_start; i < (c->e_pkts.pkt_stop + 1); i++, c->e_pkts.pkts_w++) { if (bgzf_read(c->pcap, (pcap_offline_pkthdr_t *)&pcap_h, PCAP_PKTH_SIZ) != PCAP_PKTH_SIZ) { snprintf(c->errbuf, BUFSIZ, "bgzf_read() error: cant read pcap hdr\n"); return (-1); } pkt_caplen = pcap_h.caplen; if (bgzf_read(c->pcap, buf, pkt_caplen) != pkt_caplen) { snprintf(c->errbuf, BUFSIZ, "bgzf_read() error: can't read packet\n"); return (-1); } memcpy(&buf2, &pcap_h, PCAP_PKTH_SIZ); memcpy(&buf2[PCAP_PKTH_SIZ], &buf, pkt_caplen); if (write(c->pcap_new, buf2, PCAP_PKTH_SIZ + pkt_caplen) != PCAP_PKTH_SIZ + pkt_caplen) { snprintf(c->errbuf, BUFSIZ, "write() error: %s\n", strerror(errno)); return (-1); } } return (1);
Conclusion and Future
In this article you learned about the latest craze in compressed pcap packet indexing and extraction, cppip. We explored how to install and use the tool as well as peeking at some of its internals. In the future, I plan to do a fair amount of code cleanup and optimization. I also plan on adding microsecond level timestamp indexing, endianness information in the file header, creating a C library, possibly some new indexing methods based on protocol. As always pull requests are welcomed. Thanks for your time, and please feel free to leave some comments!






Mike, you came a long way since I thought you the basics of hacking. This stuff looks legit though, but I’ll email you few pointers where you can improve the code. Don’t worry, I won’t charge you. Call me when you get my email 🙂
Thanks Abe! Tell me, where do you think I can improve the code? Clearly the extraction module is a mess. Where should I start?
Both the index module and the extraction module need tweaking.
Check your email.