
 Written by Gitesh Shah, Technical Marketing Engineer Cable Access Business Unit
Written by Gitesh Shah, Technical Marketing Engineer Cable Access Business Unit
We have discussed the benefits of a Distributed Access Architecture (DAA) with Fiber-Deep topology using R-PHY standard in a previous blog (DAA for Cable Access, separating myths from reality). Today I wanted to talk about deploying that architecture, specifically how to design a flexible, resilient, extensible and easy to manage network to interconnect the CCAP-Core and R-PHY Node Devices (RPDs) in the field. Also called the Converged Interconnect Network (CIN).
Cable operators already have previous experiences with the CIN with M-CMTS implementation. In these deployments, external E-QAMs were deployed to allow for downstream convergence in the hub/headend. The M-CMTS CIN would be composed of a few top of rack (ToR) Layer-2 switches to provide connectivity between the M-CMTS and the co-located E-QAM(s). In comparison, a fiber-deep R-PHY environment CCAP core needs end-to-end Ethernet connectivity with RPDs in the field. This poses additional challenges, I will highlight some of them:
- Multiple and de-centralized cores: The R-PHY spec defines Primary and Auxiliary CCAP Cores as devices that use MHAv2 to interconnect to an RPD. Each RPD will likely need to connect to many cores, either centrally located on a single CCAP device or spanning multiple devices. Providing this connectivity poses a fundamental networking question, should bridging or routing be used?
- Bandwidth Planning: The R-PHY CIN requires a nonblocking network architecture. Hence the aggregation points within the CIN, where potential bottlenecks reside, have to be provisioned with maximum bandwidth usage in mind. At the point in the CIN where CCAP core devices are aggregated the requirement is to provision for the CCAP core capacity. For example, the cBR-8 Digital Physical Interface Card (DPIC) with 4+4 10G connectivity should be provisioned with 40G per LC. However, on the RPD interconnect switches the aggregation links should be designed with the total number of service groups served and the maximum per service group bandwidth per switch.
- Full-Mesh or Point-to-Point: A full mesh design ensures physical connectivity to and from all CCAP-Core devices and their respective ports to all RPDs. If such flexibility isn’t required or desired, partial mesh or point-to-point scenarios provide a mechanism to achieve desired connectivity. However, the operational complexities of future migration of cores and re-mapping of RPDs increase significantly with a partial-mesh or point-to-point design.
- 1588/PTP Requirements: R-PHY architecture requires CCAP-Cores and RPDs to connect to a common 1588 clock. The CIN network needs to provide, symmetric and predictable latency while minimizing the overall end-to-end latency.
- Redundancy: The CIN can incorporate fiber redundancy, RPD + CCAP core link redundancy and switch redundancy, any combination aforementioned options are in addition to CCAP core High Availability features that protects against software and hardware failures on those devices. The benefits of each additional layer of redundancy need to be weighed against the complexity and costs.
To summarize, we need to design an L2/L3/L2+L3 CIN with a non-blocking architecture, low and predictable latency, and with some level of mesh and redundant connectivity. We can look to modern data-center designs where these precise requirements are met using Clos network-based spine-and-leaf architecture.
The particular use-case for the spine-leaf architecture for the R-PHY CIN is to optimize east-west traffic. Since the CCAP cores predominately communicate with RPDs and vice-versa, both of these elements are part of a common spine-leaf construct. There will be a minimal amount of control plane and management traffic that will be north-south bound, but the amount will be trivial in nature in most deployments. This unique characteristic provides a way to optimize spine-leaf topology to be suited for the R-PHY CIN. Example Topology:
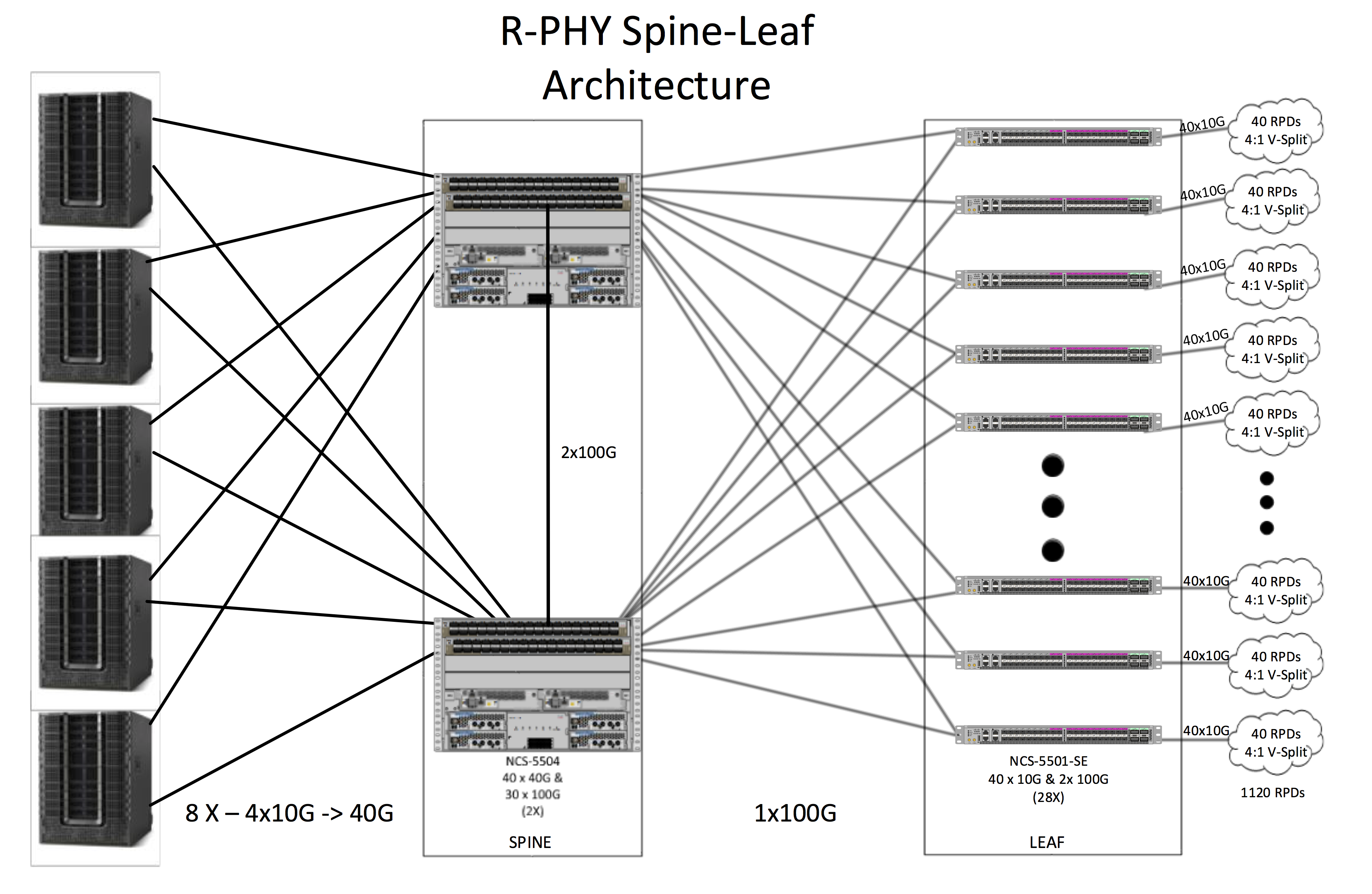
A well-designed CIN will pave the way for seamless deployments of RPDs in the production at scale. Additionally, it will reduce operational complexities associated with operating the R-PHY eco-system along with paving the way for future growth and migration to virtualization technologies.







It was very good to read the information on CIN, the diagram really helps a lot in understanding it. Thanks for sharing.
Appreciating the hard work you put into your site and in depth information you offer. It’s great to come across a blog every once in a while that isn’t the same outdated rehashed material. Great read! I’ve bookmarked your site and I’m adding your RSS feeds to my Google account.
http://dreamingnow.eklablog.com/roof-replacement-revealed-a-simple-intro-and-other-tips-a126680034
you are really a good webmaster. The site loading speed is amazing. It seems that you’re doing any unique trick. Moreover, The contents are masterwork. you have done a wonderful job on this topic!
http://wiki.nuitdebout.fr/index.php?title=Solutions-To-Handle-Anti-Aging-Cream-l
Useful information but i think it is not slimier to virtual reality or augmented reality (AR & VR) Zed Interactive is top 3D specialist company of products visualization in VR & AR.
Thanks