
This post was authored by Mahdi Namazifar and Yuxi Pan
Once a piece of malware has been successfully installed on a vulnerable system one of the first orders of business is for the malware to reach out to the remote command-and-control (C&C) servers in order to receive further instructions, updates and/or to exfiltrate valuable user data. If the rendezvous points with the C&C servers are hardcoded in the malware the communication can be effectively cut off by blacklisting, which limits the malware’s further operation and the extent of their damage.
To avoid such static detection mechanisms recent attackers have been taking advantage of various Domain Generation Algorithms (DGA) in choosing and updating the domain names of their C&C servers. DGA embedded in the malware generate a large amount of pseudo-random domain names within a given period, most of which are nonexistent. With the same random seed, e.g. time of the day or most popular tweets of the day, the attackers can generate exactly the same list of domain names remotely, among which they will only register a few. The malware will contact some or all of the domains generated by the DGA, giving its opportunity to be able to connect to the C&C server. The sheer amount of nonexistent domains produced by the DGA on a daily basis presents a great burden for security specialists if blacklisting is still to be pursued.
One of the counter-strategies against malware equipped with DGA is to reverse-engineer the algorithm and use it to automatically generate the target blacklist. Although this method is highly effective if the reverse-engineering is successful, it is a resource- and time-consuming task. New DGA detection methods have been proposed[1][2] which analyze the statistical and linguistic features of the domain names and the related network traffic to determine whether they are generated algorithmically. In this blog post we introduce the first component of our DGA detection system. This component utilizes a novel language-based technique for detecting strings that are generated by chaining random characters, with the assumption that most of the DGA generate domain names which can pass various randomness tests in order to avoid conflicts with existing legitimate domains.
The output of our component is a randomness score on which decision can be made as to whether the input is an algorithmically generated domain name. To calculate such a randomness score we started with building a large set of dictionaries encompassing various languages, e.g. English, French, Chinese, etc. For some languages different versions or dialects were built as well. The set also includes languages that were manually constructed, e.g. Esperanto and Interlingua. In total there are over 60 dictionaries assembled to cover different languages, a list of these dictionaries is shown in Figure 1. In addition English names from US 1990 census data, Scrabble words, Alexa 1000 domain names and texting acronyms have also been added to the set. The goal of constructing these dictionaries is to identify non-random sequence of characters or words in the domain names, which are less likely to appear in a DGA-generated name.

Figure 1. The list of language dictionaries
For each domain name under investigation we then enumerate all of its substrings whose initial or final character aligns with the original string. Dashes and underscores in the domain names help with the tokenization as well. Features involved in computing the randomness score include:
1. the number of dictionary hits of the substrings
2. the length of substrings that appeared in a dictionary
3. the number of different languages needed to cover the substrings
A linear model was built to calculate the randomness score, the weights on the features values as well as thresholds involved in the decision were carefully tuned against legitimate domain names in the Alexa dataset as well as the illegal ones generated by a variety of reverse-engineered DGA. Figure 2 shows the result of the false negative rate on a set of algorithmically generated domains produced by 9 different DGA, together with some of the sample domain names missed by our detection method.
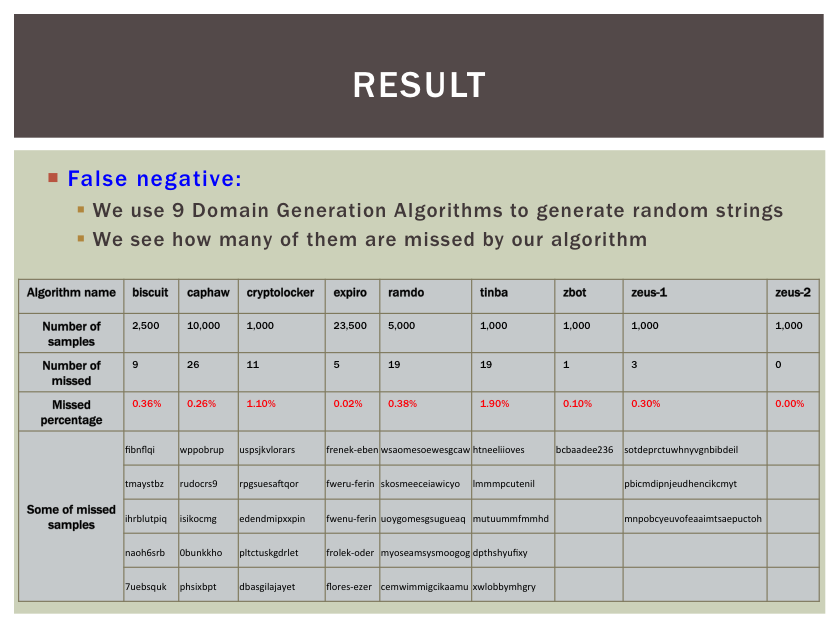
Figure 2. False negative rate of our DGA detection component
Figure 3 shows the result of running our method on Alexa 10000 domains dataset which is believed to consist of only benign domains. Some of these domain names were considered as randomly generated by our detection method therefore constitute the false positive sample.
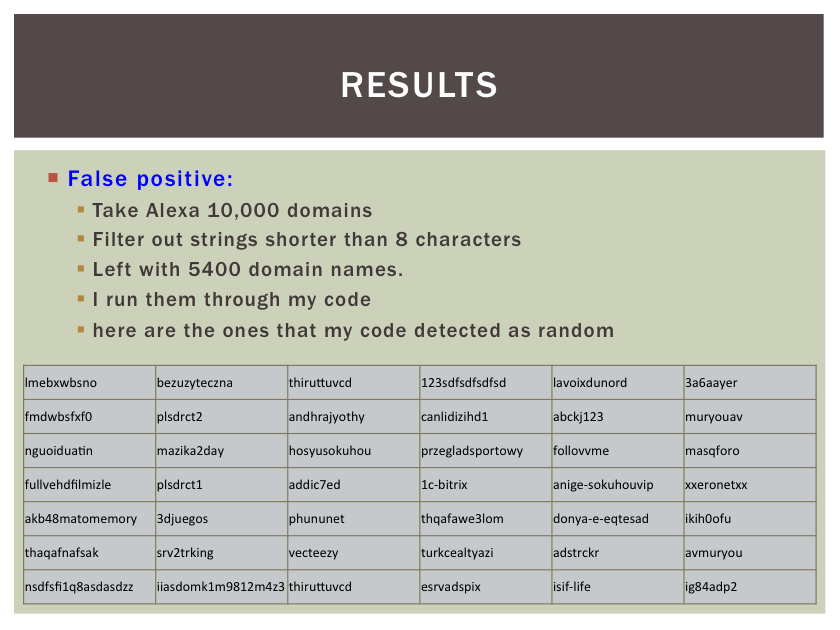
Figure 3. False positive samples of our DGA detection component
As a real-world example, we looked into the domain names generated by an actual Cryptolocker malware[3]. Cryptolocker encrypts all the files on a victim system using random keys generated by itself. Then it encrypts these keys using RSA with a public key received from the C&C server. Users of the systems are asked to pay an amount of money to the attacker if they want to unlock their files. For this reason Crytolocker is also called a ransomware. The way Cryptolocker connects to its C&C server to receive the public key is through contacting DGA-generated domains. Ref.[3] displays the result of a tcpdump captured on a system right after infection. The second-level domain labels include:
uqxypfdjiwwrdvi
uqxypfdjiwwrdvi
iqnueumtiyugvjt
iqnueumtiyugvjt
vmivkpqyunlqfpl
vmivkpqyunlqfpl
ptiautjthpnxdcw
ptiautjthpnxdcw
qednmophtxheusk
qednmophtxheusk
qpswpewjtgcwdqq
qpswpewjtgcwdqq
rankhydwgovdetm
Our method successfully identified these 13 domain names as DGA-generated domains.
The current DGA detection component has been operating on our private cluster analyzing up to 200,000 newly registered domain names on a daily basis, and among them, 6,000 suspicious DGA domains are detected. Like any machine learning algorithm, the precision and recall of the algorithm is subjected to adjustment through a few parameters, depending on the targeting DGA domains. Fighting cyber-criminal is like a chess match, and DGAs adopted today are becoming more complicated, making room for more sophisticated detection algorithm. Nevertheless, the simplicity of the algorithm and the effectiveness of it on the prevalent DGA domains make it an essential component in our threat detection portfolio.
[1]. Sandeep Yadav, Ashwath Kumar Krishna Reddy, A.L. Narasimha Reddy, and Supranamaya Ranjan. 2010. Detecting algorithmically generated malicious domain names. In Proceedings of the 10th ACM SIGCOMM conference on Internet measurement (IMC ’10). ACM, New York, NY, USA, 48-61.
[2]. Leyla Bilge, Sevil Sen, Davide Balzarotti, Engin Kirda, and Christopher Kruegel. 2014. Exposure: A Passive DNS Analysis Service to Detect and Report MaliciousDomains. ACM Trans. Inf. Syst. Secur. 16, 4, Article 14 (April 2014)
[3].Getting prepared for the next Cryptolocker DGA. Frank Denis random thoughts.
https://00f.net/2013/11/05/cryptolocker-dga/






do you plan to release the source and dictionaries so that everyone can benefit from this? Your talk really didn’t seem to touch on how, specifically you combined various signals that you were looking at to actually compute your randomness score, which seems key to this work.
Great article but I am seeing more and more CNC connections to ligetimate web sites like AWS. If I were creating a CNC server I would direct it to one of the many public cloud web services and then encrypt the traffic from the infected host to the cloud. It seems the only way to detect this is to decrypt at the perimeter, which doesn’t scale very well.
Can the algorithm be adapted to find newly created domains that visually resemble legitimate ones? For example, detect bob@lnventiv versus bob@inventiv (leading L versus I).
I’m sure this is a very basic question. Why would a domain name registrar even register a domain that might look like iqnueumtiyugvjt. If your going to come up with a name that cannot be remembered any easier then just remembering the IP address (why DNS was created to begin with) shouldnt the registrars see some of this as supicious and require some level ‘normalcy’ in the naming? Or is the use of random domains widely used in legitimate applications?
Detecting cryptolocker domain names like the cited “uqxypfdjiwwrdvi” is easy. You can reliably detect them even by looking at bigramms only. Did you compare your approach to simple n-gramm approaches?
How does your algorithm cope with word list based DGA that yield domains like “saladdoctorbike.com”? There are quite a few families that use wordlists, e.g., Multibanker, Gozi, Matsnu, Suppobox, …? I reckon they must get very high “non-DGA” scores.
Exploit Kits are constantly altering their techniques to compromise additional users while also evading detection.
Hi,
My laptop got infected yesterday with some ransomeware. Probably all files (word, excel, ppt,pdf,jpeg,videos etc) is now with Extension .0x0. Tried renaming by removing .0x0 but now luck.
System restore can’t restore to any previous restore point than yesterday even in safe mode.
Otherwise computer is working fine.I tried contacting source person and they are demanding 3 bit coin for releasing my files.
Can somebody help me in restoring my files?
Thanks