
written by Martin Rehak and Blake Anderson, on behalf of Cognitive and ETA teams
Introduction
How many engineers does it take to find malware in encrypted traffic? In case of Cisco, the core of machine learning team that enables Encrypted Traffic Analysis (ETA) is about 50 engineers, security researchers and AI researchers based in Europe and United States. Their goal is pretty simple to describe, but far more difficult to achieve. They make sure that Cisco customers will be protected against malware despite the fact that most of the network traffic is now encrypted and an even larger majority of malicious traffic uses TLS, Tor or other encrypted protocols.
Our answer is based on ETA telemetry produced by a growing range of Cisco routers and switches. ETA telemetry is conceptually very simple. In addition to the normal Netflow export, the switch or router produces additional data fields that add information to specifically address our targeted use cases. The Initial Data Packet (IDP) contains the payload from the first packet of each unidirectional flow. In the case of TLS, the client and server IDP would contain the client and server hello’s, and in the case of HTTP, it would contain the initial request and response. The Sequence of Packet Lengths and Times (SPLT) contains information about the sizes and timing of the connection’s initial packets. This information allows us to differentiate between different categories of communication inside the TLS tunnel, e.g., web browsing, email downloads, file uploads and downloads, and many others. The Netflow and ETA information elements are processed by the on-premise Stealthwatch appliance, but the malware discovery is done in the Cisco cloud.
The Engine that Powers ETA
So, how do we secure something that we can’t decrypt and inspect on the content level? Our answer is based on a combination of modern machine learning and automated communication analysis performed on a global scale. ETA malware detection has not been built from scratch, but is based on Cognitive Threat Analytics (CTA), a cloud-based behavioral detection engine.
The CTA engine receives and processes the behavioral data from Cisco clients and returns them the list of suspected ongoing infections of their devices, with an estimation of risk, malware actor attribution and other information that is critical for the investigation. As our input, we are processing more than 10 billion Netflow records and proxy logs per day, together with information coming from additional channels. All the flows and requests are attributed to a specific customer, and most of the engine’s processing is customer-specific. This allows us to guard against information leakage that might implicitly arise if we were to process the behavioral data across multiple customers.

The first stage of the processing is a behavior-based anomaly detection filter. It is not based on a single anomaly detection algorithm. Instead, it is composed of approximately 70 different algorithms that model various aspects of behavior related to individual hosts, company-wide patterns, and the interactions between internal hosts and external servers [3]. For example, some models model the activity of individual devices during the day, while other models concentrate on weekly or longer-term periodicity. Other models have been built to estimate the applications used on each host for specific activities and to identify any unexpected discrepancies.
Some of the most advanced behavior models are specific for ETA customers. The ETA-data specific models rely on the information from the TLS metadata and the SPLT field to build the model of cryptographic primitives used by the software on a given host or the capabilities selected by a given server. The ETA information makes the Netflow produced by ETA-compatible elements similar to activity logs provided by network proxies, thus enabling behavior models that would otherwise be usable only on proxy logs and not on pure Netflow. This information can further be correlated with additional application layer protocols exported in the IDP information element, e.g., HTTP, DNS, FTP, etc.
The information we extract from ETA specifically helps us to build very detailed models of the behavior for the server side of the communications. Unlike the baseline behavioral models, the Internet server behavior models use all of the global information available to Cisco in order to predict whether a given server has a current or future use in malware ecosystem. This is not a reputation game. We diligently map and track completely legitimate services and capabilities that are often used by malware authors, and assess the risk related to benign servers that might be exploited and misused in the future. The fact that the server models are constructed (and automatically verified) on the global scale makes them less sensitive to evasion attempts.
The whole point of the behavioral modeling layer is to filter the input data. All the input flows with low anomaly scores can be discarded before additional processing. At this point, the system looks at the remaining anomalous flows and attempts to explain their existence and the reason of their anomaly. Advertisement, user tracking, and some media transmissions are very often statistically anomalous, which allows these categories to be identified and removed from further processing. We then apply hundreds of classifiers to categorize the remaining flows as either malicious or suspicious.
The flows in the first category can be immediately recognized as malicious. The classifiers that make this decision are either trained to identify generic attack techniques (e.g., the use of generated domains or botnet command & control), or are trained to identify the traffic patterns specific to malware categories (e.g., adware, crypto mining, ransomware). Yet another category of classifiers identifies the patterns specific to individual threat actors that were discovered by the system in the past. In general, if any already anomalous flow hits any of these specific classifiers, it is enough evidence for our system to raise an alarm.
ETA data is critical, as it allows us to strengthen the existing classifiers and also allows us to design additional classifiers that specifically target the malware’s use of cryptographic techniques. These classifiers combine the ETA data, flow data, host behavioral data, and server information. One of them is based on the original ETA proof-of-concept classifier [1], while the others extend the current set of classifiers inside of CTA.
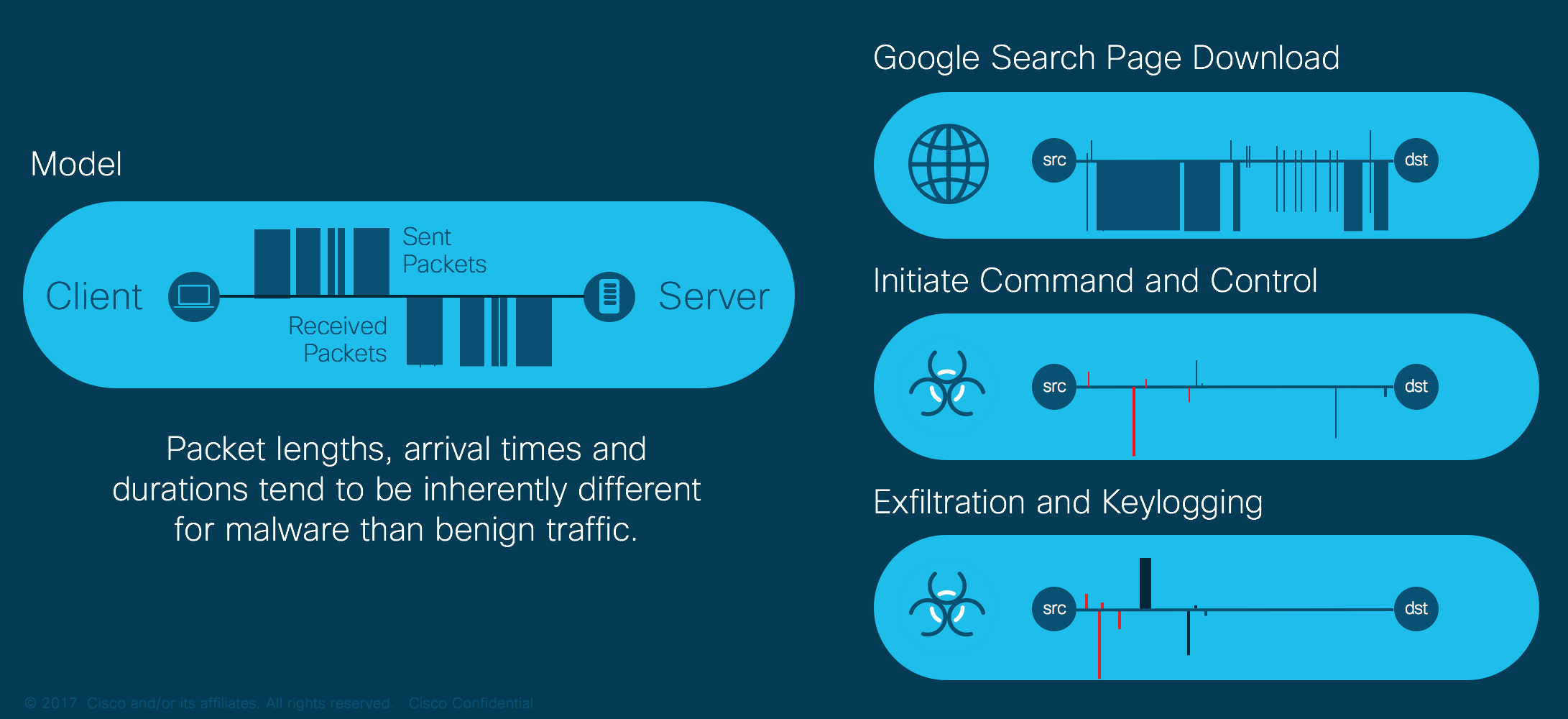
The most important question still remains. How do we classify the flows that are neither obviously malicious nor legitimate? This category is much larger than malicious flows. Its correct classification is critical because it contains a mix of odd, yet perfectly legitimate behavior combined with new and previously unseen malware behavior. In general, a single flow or a short-term observation is rarely sufficient to convict this class of malware. Therefore, we employ a cascade of techniques where we group flows into activities (bags) [2]. Each activity is then individually classified. All the activities that occur on the host under question are then considered as a group and the CTA system decides whether it has accumulated enough evidence to trigger an alert. The period of observation can vary dramatically – some such incidents are triggered within minutes, while others may take hours to weeks. The delay obviously depends on malware’s sophistication and amount of network activity.
The combination of different categories of classifiers is intentional. The specific classifiers allow the system to achieve short detection times in case of known and easy-to-detect attacks. For most of the specific classifiers, they also annotate the finding with risk assessment, threat information and predict the files that can be found on the infected host, as well as other system damage. On the other hand, the generic, long-term classifiers give the system the ability to find new malware, distinguish it from known attacks and to start building its behavior models as discussed below.
Global visibility
The next steps in processing are no longer customer-specific. The CTA system consolidates the incidents identified across all the customers, which allows some incidents to be attributed to known malicious actors. Given this information, the behavioral models representing these actors’ techniques, tactics, and resources are updated. The behaviors of incidents that cannot be attributed to known actors are then cross-references with information coming from other Cisco security products such as AMP and ThreatGrid. This preliminary model can then be confirmed to create a model of a new malicious actor. These models are then transformed into additional classifiers that are applied to the data in the classification phase.
CTA leverages the global intelligence collected across several products offered by Cisco. In particular, the above-mentioned correlation of data from endpoint-based security products such as AMP and ThreatGrid and data from network-based security products allows Cisco to track malicious campaigns as well as server groups used by legitimate applications in real time.
While monitoring network behavior of known and well established legitimate applications on the endpoints may seem redundant, it is actually crucial for the effectiveness of our system. CTA is aware of legitimate servers typically used by these applications at any point in time. At the same time, we create behavioral models of such servers and applications. Both the servers models and application behavioral models are then used in ETA classifiers in order to improve their precision and reduce false positives.
Tracking the network behavior of known malware families allows us to create behavioral models of malicious behavior. Consequently, any abrupt change in the behavior of any malware family is promptly observed and behavioral models are updated; leaving little to no space to evade detection. As such, this improves the recall of the classifiers.
Conclusions
Globally, our system is based on two main principles. It is built as an cascade of hundreds of classifiers, progressively analyzing the data and discarding anything found normal. This allows us to solve the base-rate problem (as malware constitutes only a small part of traffic) while maintaining the system’s ability to discover the new malware. The other principle is feedback. The knowledge generated by complex classifiers and subsystems deep in our funnel is used to constantly generate updated classifiers and parameters for the early stages of the funnel. Updated classifiers then produce even better data and information and start the self-improvement cycle.
Finding malware in encrypted traffic (or even non-encrypted traffic, for that matter) is not an easy job, but it is the job that we love and can be very passionate about. It is not magic. Anything that we achieve is the result of the hard work of a passionate and dedicated team. Our engineers release 5 or 6 new versions of the software every week and make sure that the platform can constantly receive, process and destroy the vast amounts of input data. Our researchers constantly design new algorithms to find even mole malware for you. And our security researchers are engaged in a daily battle of wits against the attackers, to make sure that the results we give you are as complete and as actionable as possible.
[1] Blake Anderson, David McGrew; Machine Learning for Encrypted Malware Traffic Classification: Accounting for Noisy Labels and Non-Stationarity; KDD, 2017
[2] K Bartos, M Sofka, V Franc; Optimized Invariant Representation of Network Traffic for Detecting Unseen Malware Variants; USENIX Security Symposium, 2016
[3] M Grill, T Pevny; Learning combination of anomaly detectors for security domain; Computer Networks, Vol. 107, 2016






Love the integration of AMP and Threat Grid!
Nice write up!