
Information security is one of the largest business problems facing organisations. Log data generated from networks and computer systems can be aggregated, stored, and analysed to identify where misuse occurs. The enormous amount of data involved in these analyses is beyond the capability of traditional systems and requires a new, big data approach. Given the right tools, skills and people, security teams can take advantage of big data analysis to quickly identify malicious activity and remediate attacks. Together, the big data platforms, the administration tools, analysis tools, skilled analysts, and pressing problems form an evolving ecosystem driving innovation. It would be a mistake to believe that this ecosystem is not without its challenges.
Big data remains a new phenomenon. The Hadoop file system that underpins most current big data solutions has its roots in an antecedent dating from 2004. Hadoop permits the storage and access to large amounts of data, which in turn enables many analyses that were previously prohibitively time consuming. For example, extracting information from billions of records in order to identify clusters of related activity can be performed in minutes using the parallel computing capabilities of Hadoop and MapReduce rather than the days previously required. The tools that make sense and interpret these data are still evolving. At the same time, the numbers of individuals who are skilled in operating these tools to use them to answer relevant questions is also evolving from a very low base. Ten years ago, the concept of big data and demand for big data analysis skills hardly existed. It is testament to the flexibility and knowledge within the workforce that we have progressed so far in such a short amount of time.
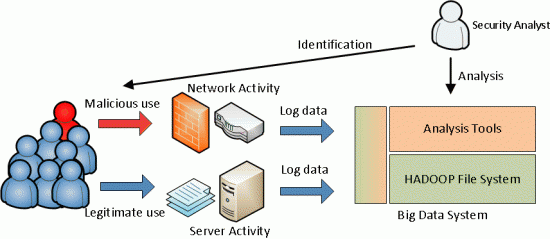
The big data systems allow security analysts to collect log data to identify malicious activity.
Implementation of big data may be held back by outdated attitudes and stale received wisdom as managers seek to apply old ways of doing things in a new world. Conversely, hype and false expectations may lead big data projects to be perceived as failing when they are unable to live up to overly high promises. Organisations must be realistic about what big data can deliver and what can be achieved with the tools and skills that are available. Working step by step toward a well-defined goal of addressing a small number of pressing business issues may be the best approach to delivering results that demonstrate the capabilities of big data, without risking disappointment.
Big data is being used to transform many different disciplines, from improving health care, to reducing carbon emissions, to improving marketing efficiencies. The approach is able to identify hidden trends and associations as well as spot the data equivalents of needles in haystacks. However, each domain is different and techniques developed in one domain may not be easily portable to another. It is as if each problem has its own different types of needles hidden within different sized haystacks. Ideally, we require domain experts skilled in big data approaches wielding domain specific tools. Skilled individuals will emerge over time, as will the development of custom data analysis tools. But for the moment we are often faced with having access to domain experts without data analysis skills, data analysts without domain experience, and generic tool sets developed for answering different questions than those that we seek.
Customising tools and analytic algorithms is part and parcel of the current big data ecosystem. The choice of approach to analysing data is often dictated more by gut instinct and familiarity with certain statistical algorithms than by a rigorous scientific evaluation of which approach may work best in a given environment. This sense of being on the edge of knowledge and trail blazing techniques is part of the attraction for many researchers. The intellectual freedom associated with big data projects attracts many skilled people. We can expect the ecosystem to mature over time, but for the moment it retains a certain “Wild-West” cachet for practitioners.
Technically, managing the resources of the many separate computers that together operate as a big data cluster poses a large problem for system administrators. Enormous efficiencies in processing can be leveraged by running big data queries in parallel on many machines within the cluster. This requires chunks of work to be allocated to different machines. Each machine must not only complete its allocated work, but also deliver the results of its task so that the final answer can be collated and delivered to the end user. As the machines within the cluster may have different amounts of memory or disk space and different speed processors running under different loads, allocating an appropriate amount of work to each machine is not a trivial task. Administrative tools to manage this process are developing but may not yet be optimal in scheduling work within large clusters.
Sharing tasks and data across a large number of machines is one of the fundamental tenets of big data. This allows new machines to be added to a cluster to expand the disk storage and processing capacity as needed. Nevertheless, system admins still need to know that data is stored in such a way so that if a disk drive fails data is not lost. Big data systems may contain far too much data to be backed up on traditional media rendering the usual backup procedures obsolete. Ensuring that there is no single point of failure within the cluster that could halt the entire cluster is vital. Adding additional machines to a cluster increases the probability of experiencing a machine failure. Equally, at some point obsolete machines must be removed from the cluster. These eventualities must be planned for and appropriately managed by systems admin tools so that the loss of one machine is not catastrophic.
Big data is fundamentally changing our approach to solving problems within information security despite being a relatively new technology. The success of the technique relies on a whole ecosystem of supporting tools, technologies, and skilled individuals. As the technology develops, invariably the ecosystem will lag, leading to numerous areas where supporting tools and relevant approaches are lacking. These challenges and weaknesses in the wider ecosystem present major opportunities for those who are able to create solutions to meet these new needs. Big data is not going to go away any time soon and neither will the prospects for those willing to contribute to the development of this vibrant community.
This post was co-authored with Min-Yi Shen and Jisheng Wang.





