
Data has always been important for many (if not all) companies. Today however it is becoming increasingly easier to collect data about customers, business transactions, devices etc…, . This data enables companies to (more dynamically) optimize their business models and processes and differentiate themelves from their competitors. Before embarking on a (Big) data strategy it is important to understand what is driving this evolution and what are basic  architecture building blocks to take into account when transforming into a more data driven enterprise.
architecture building blocks to take into account when transforming into a more data driven enterprise.
Several trends are fueling the evolution towards a more data-driven enterprise: Price/performance improvements in network, storage and computing and the rise of Cloud computing , make it more cost effective to deploy large IT infrastructures and capture data. New data management technologies and products such as Hadoop (MapReduce) and NoSQL/NewSQL provide scalable and more cost effective solutions than traditional SQL databases for various classes of problems. The IT consumerization trend results in departments more actively pursuing analytics capabilities. Another important trend is the Internet of Things (IoT): The advent of cheaper sensors and improved connectivity are bridging the gap between the physical and digital world, enabling collecting data from more devices and environments. This sensorization is unlocking the potential to gather enormous amounts of data and details about almost everything.
These trends are creating new challenges and opportunities to harness and understand the data tsunamis, and leverage the analytics for decision making purposes, to better monitor, control, and understand complex systems from business dashboards to IoT eco-systems.
Architecture Considerations
Architectures will play an important role in the evolution of the data-driven enterprise. It is therefore important to identify some of the commonalities and differences when designing a data architecture.
It all starts with (un) structured data gathering through either software or hardware sensors and (network) connectivity to transfer this data. Data can be processed at the edge, on a network gateway for example (data in motion) or sent to larger data storage and processing facilities (data center/ Cloud service). There might be a hierarchy of processing, aggregation, and integration steps (edge processing) between the local data acquisition and the larger storage and processing facility, where data will come to rest, potentially involving integration (or data virtualization) with multiple (legacy) data sources on-premise or in a Cloud. At each step there might be a real-time* feedback loop towards sensors or other controllable hardware/software components. Besides real-time feedback, data is stored and used for trend (historical) analysis and correlation with potential other large datasets. What is real-time and what is not depends on the application domain and requirements. For example, in-memory data stores are gaining popularity and can speed up traditional analytics by two or three orders of magnitude. This hierarchical view, while not incorrect, might be too limited under certain circumstances where data needs to be shared within multiple business entities and the sys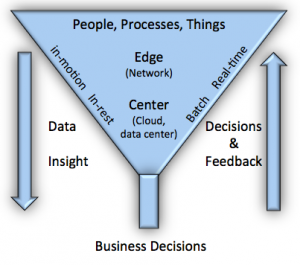 tem will need to evolve over time. A more generic consumer/producer data sharing model (fabric) for data distribution, processing and integration can therefore be more suitable and scalable. Equally important are different levels of data security and (access) policies. Encryption of stored data is not always sufficient. Secure transfer of data and proper access policies in multi-user infrastructures are very important.
tem will need to evolve over time. A more generic consumer/producer data sharing model (fabric) for data distribution, processing and integration can therefore be more suitable and scalable. Equally important are different levels of data security and (access) policies. Encryption of stored data is not always sufficient. Secure transfer of data and proper access policies in multi-user infrastructures are very important.
It is also important to understand the relation between data and time. The value of fast data (some might call this real-time) is high when this data is created, (as it can be used to immediately trigger actions or alerts), but over time this value decreases. However after a while this data becomes valuable again as it can be used for historical analysis and the outcome of this analysis can be leveraged to improve the rules that govern this fast data.
Although on the surface there are commonalities, there are also differences. Data models between different domains such as healthcare, agriculture, retail… can be very different, and legacy applications and infrastructure can have an impact on how and where data is stored and integrated. This can result in the development of customized wrappers or leveraging standard wrappers for frequently used products such as SAP, SharePoint, SalesForce, etc. Different classes of problems will need different platforms based on requirements such as scalability, and performance: Data warehouse, Hadoop, NoSQL, edge processing, etc. Depending on the domain, the volume, data rate (velocity), the number of (un) structured data sources (variety), and data quality (veracity) will be substantially different, impacting the scale and type of the most suitable architecture. With the rise of IoT, connectivity is becoming another important parameter. Within certain domains, for example transport or agriculture it is possible to collect big data volumes but network capacity to a Cloud or data center can be limited. These high volumes can potentially be analyzed at the edge (for example on a gateway) and reduce (through filtering) the volume transferred. Sometime real-time requirements means that data is only processed at the edge and rules (and control) are executed close to where the data is gathered.
Conclusions
Regardless of the size of the data, a proper data infrastructure and strategy are becoming key competitive differentiators for companies. IoT is one of the trends that will accelerate this data driven transformation.
It is becoming more important for companies to secure access to the technology and the talent (data scientists) to unlock this potential. As a result more and more non-tech (or non-software) corporations are acquiring tech startups . These acquisitions are in part fueled by the big data/analytics and sensorization trends.
Not every company has the budget or know-how to invest in new data infrastructures. Service providers are offering Cloud based data infrastructures that lower the threshold for adoption through different kinds of “pay as you go” models.
The traditional warehouse has been omnipresent during the last four decades and will not be phased out by new technologies such as Hadoop, NoSQL, or real-time systems like for example Storm. Traditional data warehouses still perform many vital functions within enterprises and can be very suitable for highly structured data. Replacing traditional data warehouses with newer technology (where suitable), will take time (and money). But several classes of problems are better served with newer technologies such as Hadoop, NoSQL, or real-time infrastructures such as Storm, and data-driven enterprises will have to deal with a greater variety and volume of data sources (on premise and in Clouds) than before, due to trends like Cloud, IT consumerization and the rise of IoT.
* We use the term real-time to describe data that needs to be immediately processed for particular outcomes, but acknowledge that real-time can mean different things to different people. A more accurate term would be low latency.
Special thanks to Marco Valente for the discussions and insight on this subject.





