
In my prior blog entry, I described the basics of Open MPI’s tree-based launching system over ssh (yes, there are still some valid / good reasons for using ssh over a native job scheduler / resource manager’s parallel launch mechanisms…).
That entry got a little long, so I split the rest of the discussion into a separate blog entry.
The prior entry ended after describing that Open MPI uses a binomial tree-based launcher.
One thing I didn’t say in the last entry: the tree-based launcher is not only an optimization, it’s also necessary for launching larger parallel jobs. There are operating system-imposed limits on the number of open file descriptors in a process, meaning that mpirun simply can’t open an ssh session to all remote servers as the number of servers scales up.
There were real-world cases of users hitting those limits, thereby forcing the move to a more scalable, tree-based system.
Since the initial implementation of the tree-based launcher in 2009, server CPUs and networks have gotten significantly faster: an individual ssh session is significantly faster to establish than it was six years ago. As a direct result, Open MPI added two more improvements to its ssh tree-based launch.
The first was to remove the serialization of ssh sessions on a single server: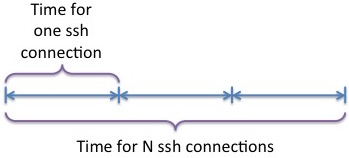
Instead, overlap initiating all the ssh connections from each interior node in the tree. Meaning: fork all the ssh connections at once, and then process them as their connections start progressing. Or, more simply: parallelize the initiation of ssh connections.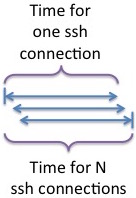
Not only does the overlap of ssh session initiation significantly speedup the overall process:
- Modern servers tend to have a lot of cores; during job launch, it’s common to be able to co-opt many cores to effect job startup duties. Hence, the individual ssh processes can be load balanced across all available cores.
- The progress of each ssh process blocks on network IO for “long” periods of time (thousands or millions of CPU cycles), allowing the OS to swap it out and progress other work (e.g., other ongoing ssh processes).
The second Open MPI improvement was to switch from a binomial tree to a radix tree.
Specifically, by default:
- For jobs up to 1K servers, each server in the interior of the launch tree (including mpirun) launches on 32 servers.
- For jobs between 1K-4K servers, each interior server launches on 64 servers.
- For jobs larger than 4K servers, each interior server launches on 128 servers.
While users can certainly override the default radix value at run time, these defaults reflect two observations:
- A heuristic: because modern CPU processors are so fast, the time to complete N overlapped ssh connections from a single server tends to be less than the time to complete N overlapped ssh connections split between a single parent-child pair in the interior of a launch tree.
- Open MPI’s “out of band” command-and-control network is routed through the launch tree structure. As such, it is desirable to keep the tree shallow.
These two improvements — pipelining ssh and using a radix tree — together make launching via ssh quite viable, even at large scale.
More improvements are certainly possible (and desirable). For example, there is ongoing work to separate the “out of band” message routing from the job launch topology, thereby allowing smaller radixes, more parallelization, and potentially shorter overall job launch time.
Stay tuned for future blog entries on this topic!






Oh no – the tree guy is back… 🙂
http://en.wikipedia.org/wiki/Radix_tree
http://en.wikipedia.org/wiki/K-ary_tree
Trees are how we stay green in Open MPI.
Nyuk nyuk nyuk…
Hi Jeff, this is cool.
Couldn’t this same technique be used for collective operations?
And save on latency as a result?
Yes, tree-based algorithms — and many other smart algorithms — are used to speed up MPI collective operations. 🙂