
Today’s blog post is by Nathan Hjelm, a Research Scientist at Los Alamos National Laboratory, and a core developer on the Open MPI project.
The latest version of the “vader” shared memory Byte Transport Layer (BTL) in the upcoming Open MPI v1.8.4 release is bringing better small message latency and improved support for “zero-copy” transfers.
NOTE: “zero copy” in the term typically used, even though it really means “single copy” (copy the message from the sender to the receiver). Think of it as “zero extra copies, i.e., one copy instead of two.”
First off, what is the “vader” BTL, and how does it differ from the previous “sm” (shared memory) BTL?
The “sm” BTL is the original shared memory MPI transport that has been in Open MPI for a long time. Messages are copied from the sender’s buffer to a chunk of shared memory. The receiver then copies the message from the shared memory to the target receive buffer. This is typically known as “copy-in / copy-out” (CICO).
Vader is a shared memory MPI transport introduced in Open MPI 1.7 that originally provided support for XPMEM for large transfers, and lower latency/higher message rates for small transfers (compared to the traditional “sm” BTL).
Since then, Vader has been updated to support both additional single-copy mechanisms, and also traditional shared memory CICO methods. In most cases, Vader outperforms the sm BTL. This led to vader being made the default BTL for local communication as of Open MPI 1.8 (although the sm BTL is still available as an alternate transport).
Vader supports the following copy mechanisms, user-configurable using the btl_vader_single_copy_mechanism MCA variable:
xpmem(configure Open MPI with--with-xpmem[=PATH]): An open-souce Linux kernel module and user-space library originally developed by SGI. XPMEM provides support for processes to export memory regions to make them available for other node-local processes to map into their own memory space. Once mapped the process’ memory pages can be accessed using direct loads and stores. This allows transfers between source and destination buffers to happen completely in user-space. A modified (and likely not bug-free) version can be found in my personal Github clone.cma(configure Open MPI with--with-cma): Linux Cross-Memory Attach functionality has been included in the Linux kernel since 3.2. The interface allows processes with ptrace attach permission to use system calls to copy memory to/from local processes. More on CMA can be found in the commit message that introduced the feature.knem(configure with--with-knem[=PATH]): An open-source kernel extension and corresponding userspace library from INRIA that provides calls for transferring memory to/from a process. Like CMA, knem requires calls into the kernel to transfer data between processes. More information on knem (including publications) can be found at the Knem project page.none: Fallback for when no single-copy mechanism is available. This mode employs traditional shared memory CICO transfers.
So, how do these single-copy mechanisms compare?
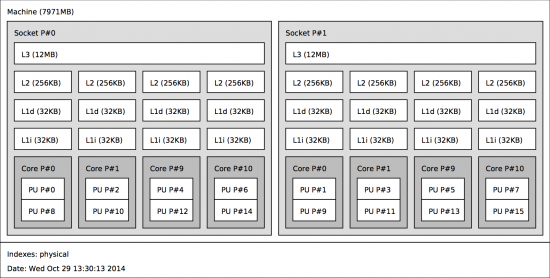
I measured performance on a mid-2010 Mac Pro with dual 2.4 GHz Xeon 5600 CPUs and DDR3 ECC 1333 MHz memory running Ubuntu 14.04.1 with Linux kernel 3.13. The benchmark was run using an Open MPI built from Git hash 75e8387 (on master / the development branch) using gcc 4.8.2.
The command used to launch the on-cache benchmark was mpirun -n 2 IMB-MPI1 Sendrecv. The off-cache benchmark was run with mpirun -n 2 IMB-MPI1 Sendrecv -off_cache -1.
The following graph shows the latency of Vader’s different mechanisms vs. the old “sm” BTL:
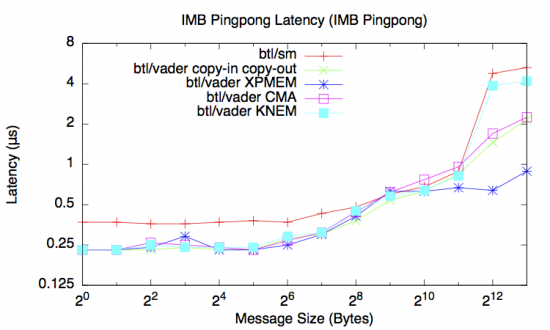
All the Vader mechanisms achieve better (lower) latency than the old “sm” BTL, especially at small message sizes. The XPMEM performance at large message sizes is particularly good.
The following graphs shows the on-cache and off-cache performance of all four Vader transfer mechanisms measured with the Intel MPI Benchmark (IMB) v4.0.
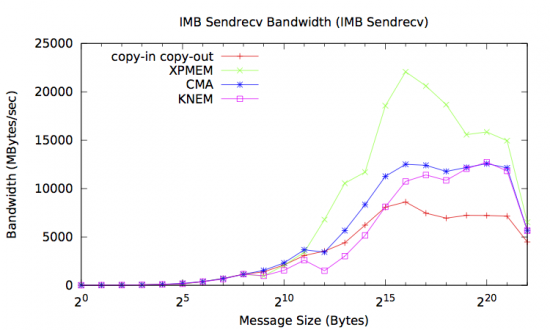
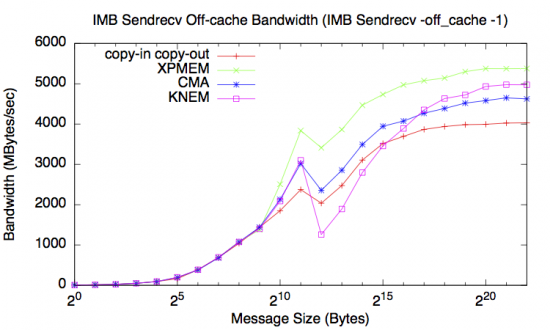
As expected, all three single-copy mechanisms provide better large message bandwidth than the CICO approach, particularly at large message sizes. Of the three single-copy methods, XPMEM is the clear bandwidth winner with this benchmark, due to a combination of lower overhead from fewer system calls and faster user-space memcpy routines.
The moral of the story is: if you haven’t enabled some flavor of single-copy mechanism in your Linux kernel, you should!





