
I’ve previously written about libfabric. Here’s some highlights:
- libfabric is a set of next-generation, community-driven, ultra-low latency networking APIs
- The APIs are not tied to any particular networking hardware model
- Cisco is actively helping define, design, and develop the libfabric APIs as part of the community
- My fellow team member Reese Faucette recently contributed a libfabric usNIC provider (plugin) to libfabric, enabling ultra-low latency Ethernet functionality on Cisco UCS servers
Today, we’re pleased to announce the next step in our libfabric journey: my team at Cisco (the UCS product team) is contributing an open source plugin to Open MPI that uses the libfabric APIs.
Specifically, we have revamped the usNIC Byte Transfer Layer (BTL) plugin in Open MPI to use the unreliable datagram (UD) libfabric APIs to directly access the Cisco Ethernet NIC hardware from userspace.
We have multiple goals for developing this new libfabric-based BTL:
- Assist in the co-design of libfabric itself. Being the transport layer of an MPI implementation is a major use case for libfabric. Actually trying to use libfabric in a current, production-quality MPI implementation yields insights that help hone the design of libfabric.
- Develop our next-generation usNIC Open MPI product. Cisco’s current Open MPI support is based on the Linux Verbs API; our next generation will be likely based on libfabric.
In short: we happen to be in a perfect position to develop libfabric and a production-quality MPI implementation that uses libfabric.
This work, especially when released in to the open source community for peer review, validates the libfabric design.
All that being said: design is one thing; results are another. So let’s look at some data.
In our implementation, the libfabric-based BTL gets better Ethernet short message latency compared to our prior Linux Verbs-based BTL plugin:
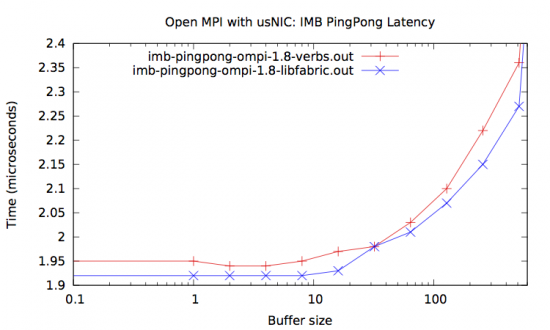
The above graph shows the Intel MPI Benchmark, version 3.2.1, PingPong test, on a pair of Cisco UCS C240 servers with Intel Xeon E5-2690’s at 2.9Ghz running RHEL 6.5 using the Open MPI 1.8 branch development head (post-1.8.4 rc1). The red line is the latency of the usNIC BTL in Open MPI with the verbs API; the blue line is our updated usNIC BTL using libfabric.
It’s worth noting that not only is the small message latency better, but the bidirectional bandwidth is also better. On a pair of Cisco UCS C240 servers with Intel Xeon E5-2690 v2’s, note the top-end bandwidth in the IMB Sendrecv test:
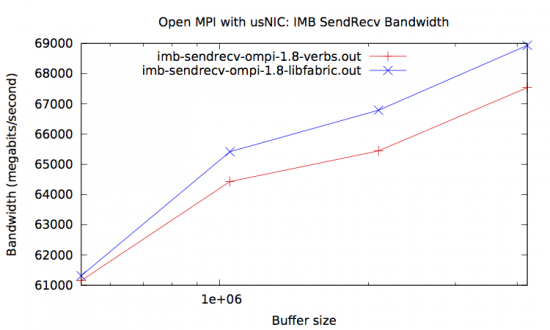
Over a Cisco 40Gb Ethernet VIC, the usNIC BTL using the Verbs API tops out at 67Gbps for 4MB messages (i.e., the sum of the simultaneous send and receive bandwidth). With the libfabric API in the same test, the usNIC BTL achieves nearly 69 Gbps.

For the most part, the efficiency gained is due to the fact that the flexible libfabric APIs are able to map directly to the Cisco VIC hardware. The Linux Verbs API contains inherent InfiniBand abstractions; Ethernet drivers must perform many conversions and translations to make their underlying hardware match these IB semantics. With libfabric, such contortions are no longer necessary. Yay!
We are initially publishing the new usNIC libfabric-based BTL to the “topic/v1.8-usnic-libfabric” branch of my personal GitHub fork of the main Open MPI repository.
It is important to note that this is a work in progress; it is not (yet) a finished product.
This first version contains an embedded snapshot of the libfabric library because libfabric itself is a work in progress. (Temporarily) Embedding a copy of libfabric allows publication of a single unit of code that can be examined, reviewed, and tested as a whole. Once libfabric is API-stable and generally available, we’ll remove the embedded libfabric copy. And once we get close to completing our overall development, we’ll move this libfabric-based usNIC BTL to the main upstream Open MPI GitHub repository.
Viva libfabric!





