
When software development involves many developers and components, the tools and techniques that are used to maintain software quality need to evolve beyond simply code and test. With bugs still making it into releases, we clearly do not have a foolproof process. So, what will it take to enhance software quality from development to release?
Here are key considerations that go into maintaining software quality.
Beyond Unit Testing
Bugs, or software defects, are regular part of software engineering. For smaller projects, it is enough to write the code, put it through some tests, fix any bugs resulting from the tests, and then declare it done. If you are a fan of Test-Driven Development, (TDD) you can do the reverse, where you write the tests first and then write the code to pass the tests.
Both approaches are unit test approaches and can be used to validate that the unit under test performs the function that it was designed to do. Furthermore, if you archive the tests, you have the beginning of a set of regression tests that will allow the developer to validate that any changes made to the unit still allow the unit to function as originally designed.
The development of a strong unit-testing framework is one of the foundations of software quality but this, alone, is not enough to ensure software quality. This type of testing assumes that if the units are working fine, then the sum of the units is working fine. The other issue is that as the number of software units grows, maintaining and running the increased number of tests—that can grow to thousands—becomes an onerous chore.
Tests of Tests
Taking testing to the next level, unit tests move into feature and solution tests. These tests start with a functioning system and then exercise the interfaces from the perspective of an end operator. Configuration changes, different packets, different connecting systems, topologies, and other elements are tested using automated tests that try to ensure that the software works as intended. These tests do a good job of ensuring that what has been tested works, but the runtime and the resources involved can be staggering. It is not uncommon to have to book test runs six months in advance and a run can take a week or two to complete.
Code Analysis
Another aspect of software quality is the software itself. From the bottom up, the code needs to be well written to reduce software defects. Beginning with the assumption that the developer knows what they are doing, the code is inspected by both other developers in code reviews and by automated tools via static analysis. Both are important, but they often suffer from a lack of context. The static analysis tools can only identify an objective problem with the code. It raises the bar to eliminate language and coding errors, but semantic and contextual details are required to ensure quality.
Code reviews by other developers are invaluable and catch lots of issues. But of all the quality review techniques that are used, they vary the most in efficiency. A good reviewer can dig through issues, interactions, and problems that automated tools and testing don’t find. But a reviewer who is unfamiliar with the code can do little more than check the style guidelines
Designing for Quality Software
Creating quality code is sometimes not just about translating functional ideas into code. Some quality defects, though avoidable in perfectly written code, are common enough to be a recognized fact in certain environments. For example, when writing in C, there is no memory management, so memory leaks are prevalent in the code. Other programming languages have automatic garbage collection where leaks that show up as memory exhaustion are not an issue.
There are two general approaches to designing quality into software.
The first approach is the more traditional route where explicit software constructs are introduced, and the software is migrated to use them. Introducing standard libraries for common functionality is an obvious approach, but this can be very extensive with entire frameworks being developed to corral the application code to only focus on what is core to its functionality. Another twist on this is using code rewrite tools that will migrate existing applications to new infrastructure.
The second approach is something that the Cisco IOS XE development team has been experimenting with for the past five years and that is to insert structural changes underneath the application code without any changes to the code. This means instrumenting the common point that the code needs to use the compiler, to add the infrastructure changes across the entire code base. The benefit here is that a large amount of code can be changed to a different runtime. The downside is that often the application code has no awareness of a runtime underneath it, which can lead to some surprising behaviors. Since these are compiler instrumented changes, the surprises generally involve the Assembler code not matching the C code.
Quality Framework
All these different quality measures amount to a process that is somewhat like the Swiss cheese model of quality (Figure 1). Only when all layers have failed does an issue get through to the field.
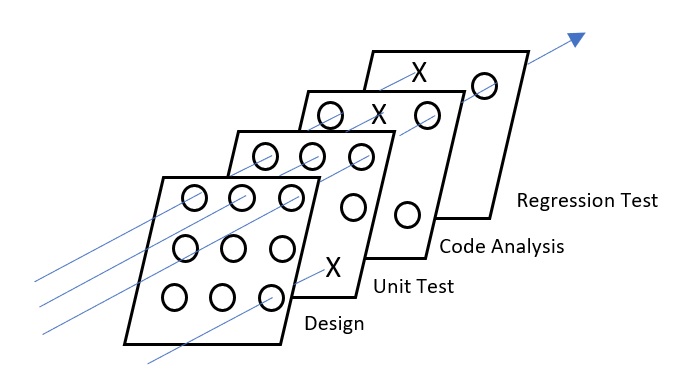
The process has accidently evolved into this and there are continual improvements to be made to the system. Additional layers need to be added that ensure quality from different perspectives. Efficiency between the test layers also needs to be improved so that the same tests are not being run in multiple layers. Finally, engineers need to be aware of the interplay between the layers so that they can accurately diagnose and fix issues.
The process by which quality software is delivered to the market continues to evolve. By structuring the process to cover a diverse range of activities—from unit, feature, and solution testing to code reviews by humans, static analysis tools, and quality design frameworks —Cisco IOS XE developers can deliver software that can reliably run enterprise networks around the world.
Don’t miss other current blogs from the Cisco IOS XE developer team:
Solving Multi-vendor Network Management Complexity with OpenConfig – Cisco Blogs
The Cisco Catalyst 9000 Software Quality Mindset – Cisco Blogs
Welcome to Enhanced Programmatic Management of Enterprise Devices – Cisco Blogs






