
Part 1 of the 2-part AI Spoofing Detection Series
The network faces new security threats every day. Adversaries are constantly evolving and using increasingly novel mechanisms to breach corporate networks and hold intellectual property hostage. Breaches and security incidents that make the headlines are usually preceded by considerable recceing by the perpetrators. During this phase, typically one or several compromised endpoints in the network are used to observe traffic patterns, discover services, determine connectivity, and gather information for further exploit.
Compromised endpoints are legitimately part of the network but are typically devices that do not have a healthy cycle of security patches, such as IoT controllers, printers, or custom-built hardware running custom firmware or an off-the-shelf operating system that has been stripped down to run on minimal hardware resources. From a security perspective, the challenge is to detect when a compromise of these devices has taken place, even if no malicious activity is in progress.
In the first part of this two-part blog series, we discuss some of the methods by which compromised endpoints can get access to restricted segments of the network and how Cisco AI Spoofing Detection is designed used to detect such endpoints by modeling and monitoring their behavior.
Part 1: From Device to Behavioral Model
One of the ways modern network access control systems allow endpoints into the network is by analyzing identity signatures generated by the endpoints. Unfortunately, a well-crafted identity signature generated from a compromised endpoint can effectively spoof the endpoint to elevate its privileges, allowing it access to previously unauthorized segments of the network and sensitive resources. This behavior can easily slip detection as it’s within the normal operating parameters of Network Access Control (NAC) systems and endpoint behavior. Generally, these identity signatures are captured through declarative probes that contain endpoint-specific parameters (e.g., OUI, CDP, HTTP, User-Agent). A combination of these probes is then used to associate an identity with endpoints.
Any probe that can be controlled (i.e., declared) by an endpoint is subject to being spoofed. Since, in some environments, the endpoint type is used to assign access rights and privileges, this type of spoofing attempt can lead to critical security risks. For example, if a compromised endpoint can be made to look like a printer by crafting the probes it generates, then it can get access to the printer network/VLAN with access to print servers that in turn could open the network to the endpoint via lateral movements.
There are three common ways in which an endpoint on the network can get privileged access to restricted segments of network:
- MAC spoofing: an attacker impersonates a specific endpoint to obtain the same privileges.
- Probe spoofing: an attacker forges specific packets to impersonate a given endpoint type.
- Malware: a legitimate endpoint is infected with a virus, trojan, or other types of malware that allows an attacker to leverage the permissions of the endpoint to access restricted systems.
Cisco AI Spoofing Detection (AISD) focuses primarily on the detection of endpoints employing probe spoofing, most instances of MAC spoofing, and some cases of Malware infection. Contrary to the traditional rule-based systems for spoofing detection, Cisco AISD relies on behavioral models to detect endpoints that do not behave as the type of device they claim to be. These behavioral models are built and trained on anonymized data from hundreds of thousands of endpoints deployed in multiple customer networks. This Machine Learning-based, data-driven approach enables Cisco AISD to build models that capture the full gamut of behavior of many device types in various environments.

Creating Benchmark Datasets
As with any AI-based approach, Cisco AISD relies on large volumes of data for a benchmark dataset to train behavioral models. Of course, as networks add endpoints, the benchmark dataset changes over time. New models are built iteratively using the latest datasets. Cisco AISD datasets for models come from two sources.
- Cisco AI Endpoint Analytics (AIEA) data lake. This data is sourced from Cisco DNA Center with Cisco AI Endpoint Analytics and Cisco Identity Services Engine (ISE) and stored in a cloud database. The AIEA data lake consists of a multitude of endpoint information from each customer network. Any personally identifiable information (PII) or other identifiers such as IP and MAC addresses—are encrypted at the source before it is sent to the cloud. This is a novel mechanism used by Cisco in a hybrid cloud tethered controller architecture, where the encryption keys are stored at each customer’s controller.
- Cisco AISD Attack data lake contains Cisco-generated data consisting of probe and MAC spoofing attack scenarios.
To create a benchmark dataset that captures endpoint behaviors under both normal and attack scenarios, data from both data lakes are mixed, combining NetFlow records and endpoint classifications (EPCL). We use the EPCL data lake to categorize the NetFlow records into flows per logical class. A logical class encompasses device types in terms of functionality, e.g., IP Phones, Printers, IP Cameras, etc. Data for each logical class are split into train, validation, and test sets. We use the train split for model training and the validation split for parameter tuning and model selection. We use test splits to evaluate the trained models and estimate their generalization capabilities to previously unseen data.
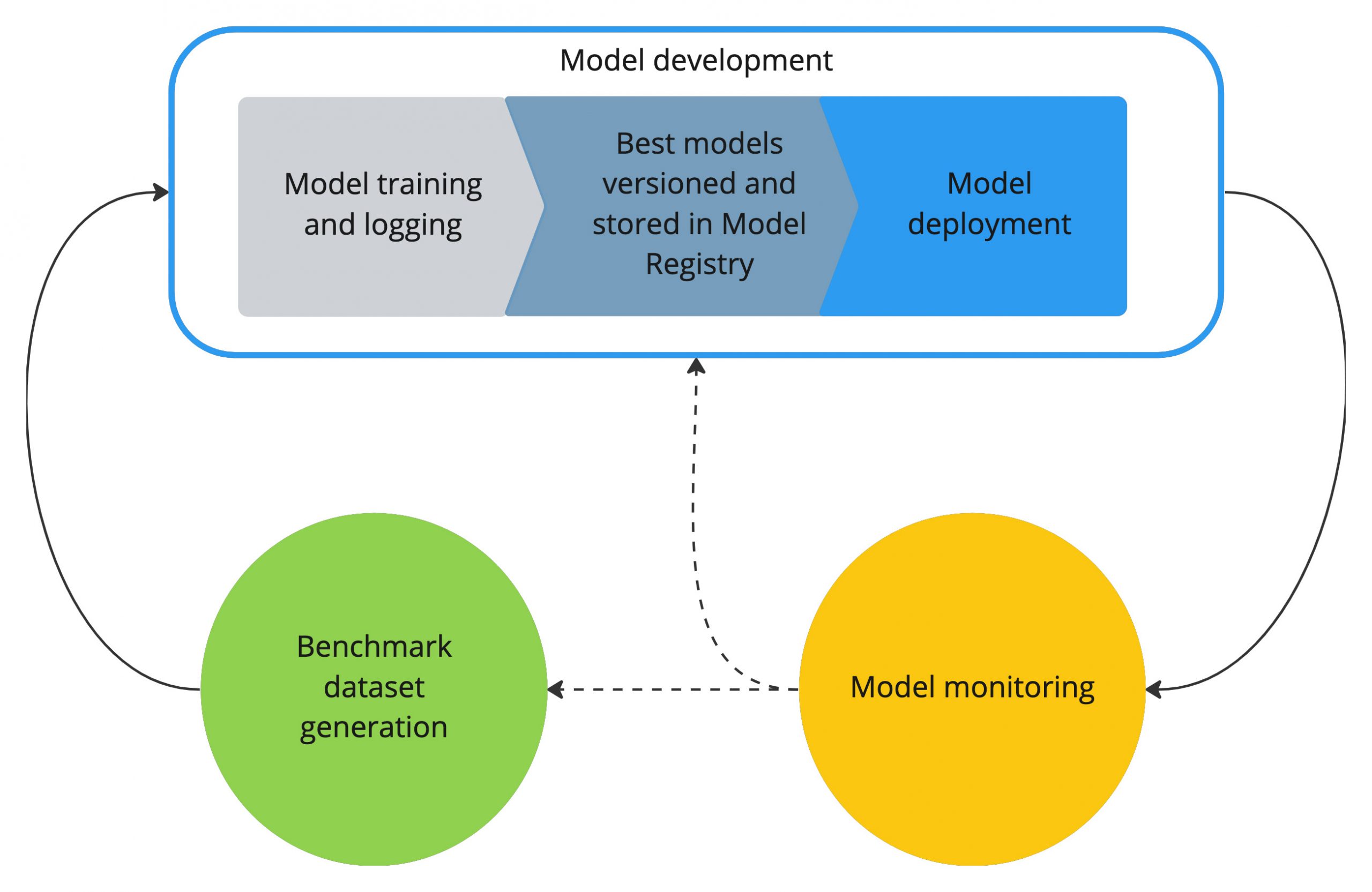
Benchmark datasets are versioned, tagged, and logged using Comet, a Machine Learning Operations (MLOps) and experiment tracking platform that Cisco development leverages for several AI/ML solutions. Benchmark Datasets are refreshed regularly to ensure that new models are trained and evaluated on the most recent variability in customers’ networks.

Model Development and Monitoring
In the model development phase, we use the latest benchmark dataset to build behavioral models for logical classes. Customer sites use the trained models. All training and evaluation experiments are logged in Comet along with the hyper-parameters and produced models. This ensures experiment reproducibility and model traceability and enables audit and eventual governance of model creation. During the development phase, multiple Machine Learning scientists work on different model architectures, producing a set of results that are collectively compared in order to choose the best model. Then, for each logical class, the best models are versioned and added to a Model Registry. With all the experiments and models gathered in one location, we can easily compare the performance of the different models and monitor the evolution of the performance of released models per development phase.
The Model Registry is an integral part of our model deployment process. Inside the Model Registry, models are organized per logical class of devices and versioned, enabling us to keep track of the complete development cycle—from benchmark dataset used, hyper-parameters chosen, trained parameters, obtained results, and code used for training. The models are deployed in AWS (Amazon Web Services) where the inferencing takes place. We will discuss this process in our next blog post, so stay tuned.
Production models are closely monitored. If the performance of the models starts degrading—for example, they start generating too many false alerts—a new development phase is triggered. That means that we construct a new benchmark dataset with the latest customer data and re-train and test the models. In parallel, we also revisit the investigation of different model architectures.
Next Up: Taking Behavioral Models to Production in Cisco AI Spoofing Detection
In this post, we’ve covered the initial design process for using AI to build device behavioral models using endpoint flow and classification data from customer networks. In part 2 “Taking Behavioral Models to Production in Cisco AI Spoofing Detection” we will describe the overall architecture and deployment of our models in the cloud for monitoring and detecting spoofing attempts.
Additional Resources:
AI and Machine Learning: A White Paper for Technical Decision Makers





