
Part 2 of the 3-part High Availability Series
My recent blog on high availability (HA) for enterprises provided an overview of features in Cisco IOS XE Software that contribute to HA. On three continents, Cisco software engineers are working on IOS XE features that embed multiple processes for failover in bare metal, virtualized, and wireless infrastructure. They are engineering ways to maintain device state without interruption with real-time data synchronization, ensuring data is encrypted and decrypted seamlessly to guard against hacking, and reducing software upgrade times from hours to 30 seconds, all to further decrease downtime.
Here is an expanded view of some of those features that contribute mightily to HA in the enterprise.
Operational Data Manager
Processes in active switches update the database and the database maintains the device’s state. Since the standby doesn’t communicate with the outside world, it is updated by the active switch, and it uses Operational Data Manager (ODM) to update the database (Figure 1). ODM uses Replication Manager (REPM) to trigger all the data to sync from an active to a standby switch.
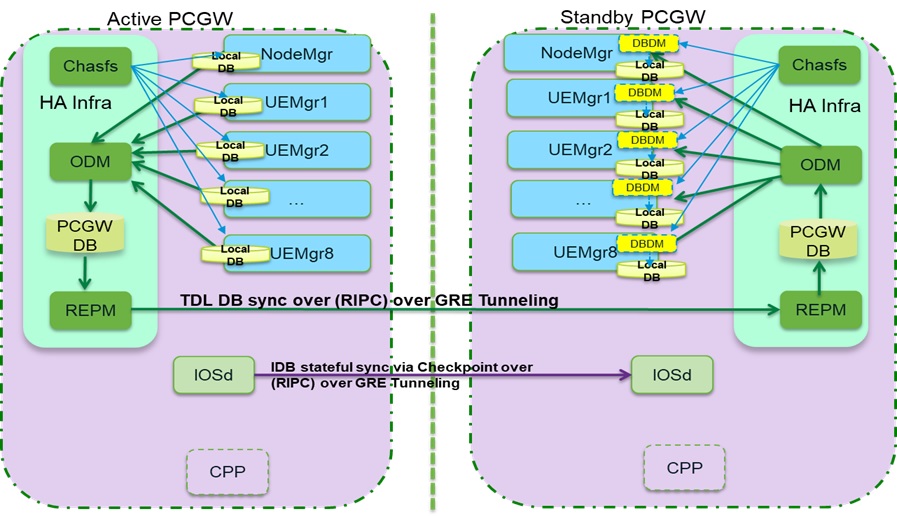
The REPM is a Basic Input/Output System (BINOS) process responsible for Crimson DB synchronization from an active switch to a standby switch. The REPM library is initialized as the HA service library where the active and standby role resolution is done. The REPM shim layer registers the databases and tables for monitoring and shadowing. All stateful data is synced by REPM without the direct involvement of the applications.
When the standby starts, the REPM on the standby requests the active REPM to start replication. It makes sure the replicated data goes to the intended target. The update first goes to the database and then updates the processes in the hot standby switch.
The ODM client drains all pending messages before it switches from write to read on the local database so that the subsequent local database write-by feature will not fail. The ODM server owns the consolidated database resources (e.g., tables, records, cursors) and the ODM client owns local operational database resources like cursors.
In wireless deployments and StackWise Virtual Link platforms, there are only two nodes: one active, and one standby. So, two protocols were created to enhance HA in these environments: Redundancy Management Interface (RMI) and Dual Active Detection (DAD).
Redundancy Management Interface
RMI was created as a second interface across the wireless controllers to ensure reachability. If the Redundancy Port (RP) link goes down, the RMI infrastructure on the standby and active controllers communicate via the RMI interface. Then, based on gateway reachability and node status, it moves one controller into recovery mode. It will ensure that one good controller is active at a time in this fault scenario.
There is a heartbeat mechanism between the active and standby controllers over the RP link. Previously, if the heartbeat failed, there was no mechanism to find out if the failure was limited to the link or if the other controller had failed. If the failure was on the link, the standby might assume that the active had failed. The standby would then become the new active node and claim the management interface IP. This happens by sending a gratuitous Address Resolution Protocol (ARP) response by the new active controller that maps the management interface IP to its own MAC address. The standby-turned-active controller starts processing access points and client messages and other traffic. Though the old active is up with the same IP, it will not receive any more traffic, leaving the system in an indeterminate state.
The RMI helps avoid this kind of indeterminate state and failover based on a momentary glitch, which can occur in wireless, especially with outdoor products. This interface is used as a secondary link between the active and the standby controllers and enables both to be active momentarily. The IP address on this interface should be configured in the same subnet as the management interface. The status of the RP link along with the status of the peer as determined by the RMI link determine if a switchover should be triggered.
Dual Active Detection
For StackWise Virtual Link-based platforms, which provide the ability to visualize two connected switches into a single switch, if the connection between the active and standby switches is lost and one switch fails over to the second, the Dual Active Detection (DAD) process is activated. It queries the node manager for the existence of the lost peer. If it is available, it sends a recovery handshake. Once the handshake is completed, if the lost connection was due to a momentary glitch, the standby switch goes into recovery mode. If the switch is experiencing a failure, the other switch goes into recovery mode and assumes the active role.
DAD provides another connection in a switching topology for confirmation. Before failing over to the second switch, it verifies that the first switch is down versus experiencing a slight and momentary glitch.
Symmetric Early Stacking Authentication
Symmetric Early Stacking Authentication (SESA) is a security mechanism for BIPC and Remote Sync (RSYNC) traffic in Catalyst 9000 series switches. It encrypts and decrypts all the remote inter-process communication in Cisco Catalyst 9000 products to guard against any hacking attempts. SESA works with Stack Manager, StackWise Virtual Link, and wireless and is Federal Information Processing Standards (FIPS) compliant.
When one Catalyst 9000 series switch interacts with another, SESA authenticates the second switch before linking to it as a standby. SESA keys need to be present on the new switch to enable valid authentication. The keys are periodically changed (e.g., every 10 minutes) and the information is sent to all connected nodes.
Extended Fast Software Upgrade
It used to take 6 to 7 minutes to reload software on Cisco switches. With Extended Fast Software Upgrade (xFSU), Cisco engineers have gotten the process down to 30 seconds or less. The traffic keeps flowing as the fast reload is in process. The hardware is never powered off and the control plane is maintained in an operational state.
When the system comes back up, it contacts the hardware and requires only 30 seconds to reprogram it. The timeframe increases with additional hardware, but it still is much faster than before xFSU was available.
Graceful Insertion and Removal
To perform troubleshooting or upgrades, network administrators sometimes need to manually remove one active switch or router and replace it with a standby. To do so, the Graceful Insertion and Removal (GIR) function was created. GIR notifies the protocols of both devices that they should be in maintenance mode but not shut off or disconnect from the network. Traffic is diverted during the maintenance window.
When the active node goes back into production, it doesn’t have to recreate the sessions it missed. The objective is to minimize traffic disruption both when it is removed from and re-inserted back into the network, another feature that contributes to HA.
In-Service Software Upgrade
With the in-service software upgrade (ISSU) feature, Cisco customers using platforms offering redundancy can avoid disruptions from image upgrades. ISSU orchestrates the upgrade on standby and active processors one after the other and switches between them so that there is zero effective downtime and zero traffic loss. The active switch’s control plane is always up.
The IOS XE software stack has the capability to do ISSU between any–to–any releases and the development team has an elaborate feature development testing and governance process to ensure this happens without failures. Cisco defines policies for a smooth ISSU experience based on platform and releases combinations. Customers using the Cisco DNA center can use these policies for a smooth and non-disruptive ISSU experience.
Hot Patching
To speed up the process and lower the complexity, Cisco issues small micro images containing only the code necessary for a critical bug or security fix. Customers can install it on devices in a fraction of a second using hot patching without any network disruption. Hot patching doesn’t result in a device reload and the fix takes effect immediately. Because of the small size of the patches, they are easy to distribute. Because of their limited content, customers can have much higher confidence in installing these micro patches in their production network without going through the complete validation process.
The hot patching feature is a toolchain of integrated technology and is expected to provide a default hitless defect fix.
Stay tuned for coming Cisco IOS XE features that enable HA across clusters of devices in different geographies!
Additional Resources:
Cisco IOS XE – Past, Present, and Future
How IOS XE Developers at Cisco Work Remotely and Cohesively on a 190-million-line Code Base
Native or Open-source Data Models? Use both for Software-defined Enterprise Networks





