
It’s 2019! (nearly wrote 18 there!) and the definition between operations engineer and developer has been blurred for longer than we can remember. The early 20xx’s DevOps mentality – beautifully characterized in books such as Gene Kim’s “The Phoenix Project” – have shifted the onus to end-to-end responsibility for a project.
Years on, we now have tried and tested paradigms and methodologies for ensuring technical stakeholders – historically known as “ops” and “dev” – are involved from the outset of a software project, with heavy reliance on day-zero automation, metrics, and reproducible dev/test/prod deployments.
Automation Code
With this mode of operation, an app’s codebase wouldn’t be anywhere near “production” without a significant amount of automation code. While calling it “automation code” may be nails on a chalkboard for some, personally, I see configurations, templates and definitions, describing how the underlying infrastructure can be built for the project (or re-built) from nothing, without any manual human intervention. And all of these require testing, validation, source control, security and dependency tracking, just like the application code itself.
This “code” may define how a CI/CD pipeline takes changes to the application codebase, tests it and produces new production deployment. It may define the spin-up of virtual machines, database clusters and other cloud resources needed as dependencies, it may deploy the very CI/CD infrastructure itself, or all of the above and more.
Automation Choices
Teams have a a number of options with the above automation, with choices often made based on an individual team matrix of:
- Project requirements
- Team skills & experience
- Business policy
- Deadlines
- Politics & Budget
(To name just a few!) This automation will usually be unique due to this decision matrix; the number of variables pretty much guarantee uniqueness somewhere in the process. This causes a problem when we look at Hybrid or Multi-Cloud (and I use those terms interchangeably, you’ll see why as we read on)
Branching out from ‘one’
All projects usually start on one ‘provider’, be it on-premise (VMWare, Openstack, Bare Metal, etc) or Public Cloud (AWS, GCP, Azure, Packet, etc).
This provider may have multiple regions, availability zones and the like, but one provider it remains; for those who’ve experienced it, the occasional global S3 outage reminds us of that.
That said, this isn’t a fear-led article about multi and hybrid. The main public cloud provider’s up-time records are phenomenal. There are many better reasons to consider multi and hybrid cloud, such as dynamic cost/value tracking, ‘lock-in’-proofing your intellectual property, superior region coverage, GDPR and other data-geofencing requirements just to name a few.
Back to the point, It’s in this “branching out from one provider” task, where the first major hurdle to hybrid/multi lies, consider the following:
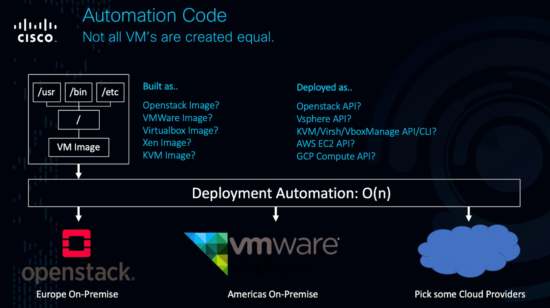
Your first provider is one of the three lower images, you want to also consume X of the others.
The problem, historically, is we’re talking virtual machine images with some configuration management, and each provider we want to support has a completely different API for automating this into reality.
Sure, there are great automation tools to make dealing with these API’s easier, like Terraform; but let’s compare simple terraform manifests for an AWS EC2 VM and a GCP Compute VM:

The same? Not at all. So while our multi-cloud automation can call the same tool for both deployments, the complexity of our “automation code” (those manifests, configs, etc) increases by 1 for each new environment we want to support, in BigO notation it’s a complexity of O(n) for n providers.
The mythical, universal API
Imagine instead, a world where VSphere spoke the Openstack API, and vice-versa, and AWS EC2, and GCP, and Azure, Packet.Net and whoever I’ve forgotten (sorry!)
Imagine they all spoke a single API, so asking for a specific VM with specific settings in all of those providers was one and the same thing. We’d suddenly have an O(1) scenario, where new environments would require minimal to zero extra automation code.
Enter Kubernetes
For the first time, Kubernetes’ popularity alone has achieved something nothing else has…It has caused every cloud provider – not wanting to miss out on revenue from customers wanting to consume Kubernetes – to offer “managed Kubernetes” or “Kubernetes as a service” at zero or very little cost above the usual compute cost for VM’s.
For the first time (that I can remember in this industry, at least, and the X86 and linux Kernel API’s don’t count!), we have a consistent API for defining our application deployments once, regardless of the number of providers we want to support.
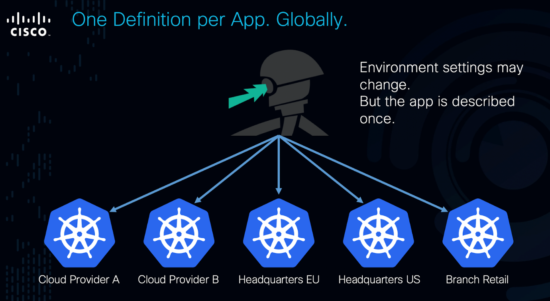
Does this magically solve all multi and hybrid cloud problems? Of course not. But consistent API’s and reducing complexity cost of supporting multiple environments sets us on the least friction path to embracing multiple providers when we are ready.
Interested to learn more?
There are a number of issues and considerations still to overcome though. From serverless to security, from (data)silos to servers, I’ll be writing more about how developers can take advantage of multi-cloud environments. I hope you’ll follow along, and send me any comments or questions you have.
In the mean time, DevNet has a number of multi-cloud developer resources you can access to learn more, including hybrid solutions for Kubernetes on AWS. Or catch up with more of the conversation by listening to our free webinar recording!
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Twitter @CiscoDevNet | Facebook | LinkedIn
Visit the new Developer Video Channel




