
Welcome back! Thanks for your interest in our journey from that painful “you wasted our engineering” moment to the product we announced on Sep 4th – UCS M-series Modular Servers.
There’s good pain and there’s bad pain. This pain was the muscle ache after a hard game of flag football. We had wasted some energy but were winning. Our customers were our coaches; they were precise about which parts of our game they loved and which parts they didn’t care for. They loved the management policy engine within UCS Manager but *did not* need the levels of redundancy and resilience in the hardware. And they really … really wished that we added some aspects to our game, specifically improvements to power and space efficiencies. Our customers were either trying to eke out more from their existing data centers or trying to reduce their co-location costs.
So our cloud scale customers,
i) loved our management policy engine
ii) didn’t rely on hardware redundancy/resilience
iii) needed better power and space efficiencies
I’ll note here that during this time we gained incredible respect for our cloud scale customers. These customers are either disrupting traditional industries or are innovators who are reinventing themselves to take advantage of the “internet everywhere” age. That’s a tough business, and whoa is competition fierce! ……. being 2nd best on the internet often means you are a distant loser.
We were determined to use the pain we felt and the empathy we had gained to help our customers. Our great success with our blades and rack server also gave us the luxury of being absolutely pure about the problem we would tackle.
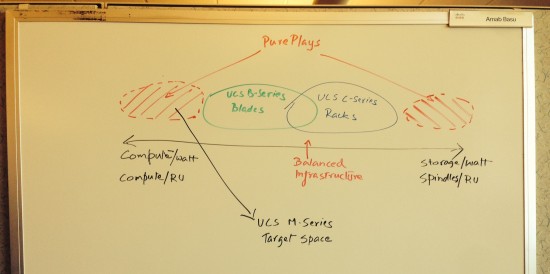
We were determined to build an architecture that was unadulterated with requirements of general purpose computing. We would optimize for compute/watt and compute/RU. We would look every which way we could improve those parameters. There would be no holy cows. Why do you need these controllers? Why do you need a hard drive? Do you really need any redundancies? We would learn from our pain and build a lean product that minimized wastages and yet, was absolutely useable and did not impose any change in our customer’s operational model…. we were going to build a product that would be “As little as possible but absolutely NO LESS”.
Next in this series will be a blog from my colleagues Steve McQuerry (lead TME for M-series) and Mahesh Natarajan (PM for M-series). They will get deeper into the M-series architecture that allows us to strengthen the goodness of UCS Manager and improve on the vectors demanded by our Cloud scale customers.
This week I want to thank our untiring engineering team. They were partners during the market discovery phase, challenged me to define what “As little as possible” meant and yet dared me to ask for more of the “NO LESS”. I am a lucky man!




Some folks have reached out to me to ask about the red area to the right in the picture above. We are targeting that space, lots of storage/spindles per RU and per Watt with our UCS C3160 product that was also announced on the 4th.
Check out http://www.cisco.com/c/en/us/products/servers-unified-computing/ucs-c3160-rack-server/index.html
Thanks for your comment. We are excited about the product. Steve McQuerry has written a couple of blogs and a white paper on the details of the product. You can read the blog at https://blogs.cisco.com/datacenter/ucs-m-series-design-principles-why-bigger-is-not-necessarily-better/ and the white paper at http://www.cisco.com/c/en/us/solutions/collateral/data-center-virtualization/unified-computing/whitepaper_c11-732876.html