
Lately I’ve been giving a lot of presentations about storage basics. I actually really enjoy it, because it makes me rethink some of the things that I took for granted, and it helps me understand some of the gaps in my own knowledge when questions arise.
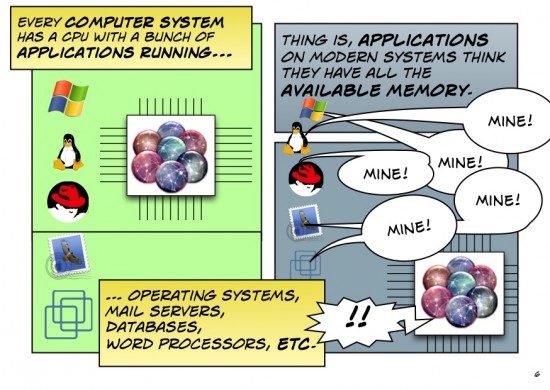
When you think of how we do certain things for storage, such as choosing block-based (e.g., FC, FCoE, iSCSI), file-based (e.g., NFS, SMB), or object (e.g., Ceph, Swift, CDMI) storage platforms and protocols, it’s easy to ignore the why these types of storage affect our Data Center architectures and performance.
It dawned on me that I only knew a relatively small piece of the puzzle (this is never a fun realization to grok the depth of your ignorance!), because while I spoke emphatically of knowing storage end-to-end, I actually had a less-than-stellar understanding of certain bits (pun intended).
After all, if I’m going to explain more about NVMe beyond the basics, I better have a water-tight understanding of the broader storage consequences, right?
So, I went asking (trust me, it’s a lot easier to admit you don’t know everything than to actually go out and rectify the situation). Notably, I went to speak to some of Cisco’s finest, such as Joe Pelissier (Distinguished Engineer and contributor to several networking protocols, including Ethernet, Fibre Channel, and InfiniBand). After he patiently sat me down and white-boarded things out, I managed to visualize a way of understanding the relationships between parts of the whole.
To that end, allow me to work through another Napkins Dialogue on how applications communicate with their storage. The road is longer than just one Dialogue, of course, so I’m breaking it down into parts for easier digestion.
Before I begin, though, allow me to thank Joe one more time for his patience and clear explanation of most of the content that follows. (Also, in case you’re wondering why I chose a familiar-looking avatar as the narrator, it’s because I can’t draw to save my life, and this was much easier) 🙂




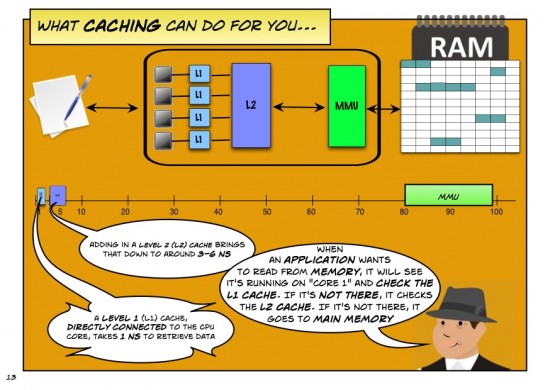
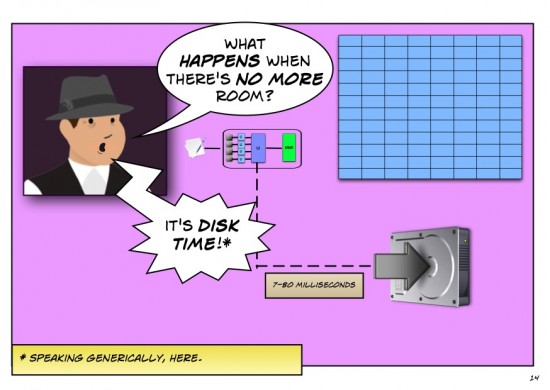


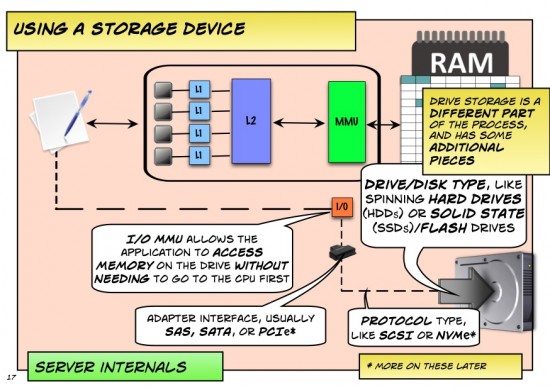
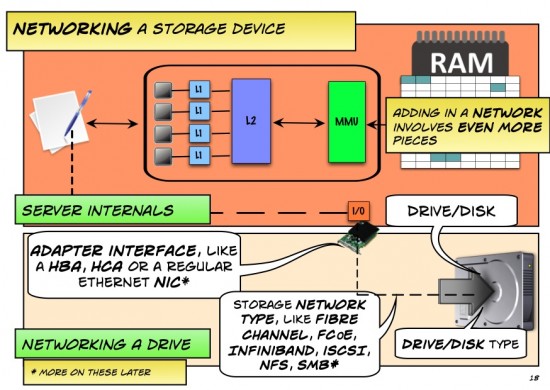
A pdf version of this dialogue can be found here.






J
I like it, looking forward to part II
John
Great post, J!
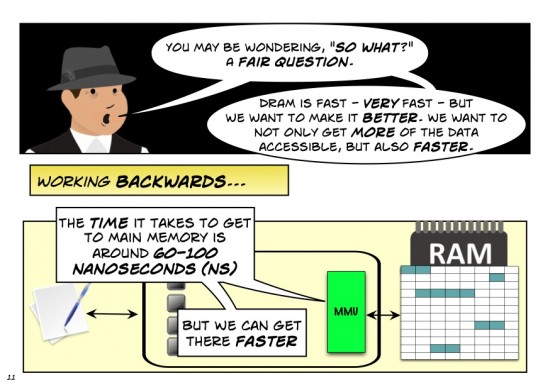
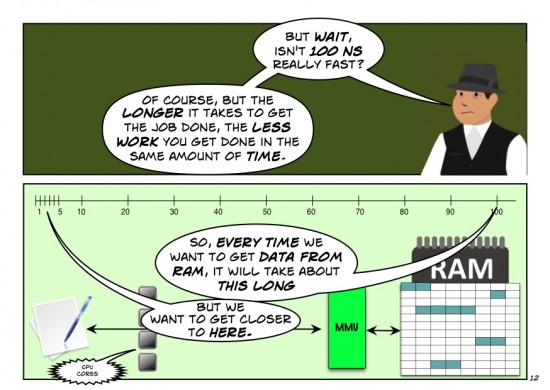
I really like the analogy about pizza and distance/time. It did two things for me: 1) helped me remember how applications can get slowed up by storage, not just memory and 2) made me hungry
This was so entertaining. Absolutely brilliant way to present.
Absolutely brilliant. Very entertaining. Thnx!
Love this blog format, the style of storytelling. Well done.
(Note although speaking for myself only I work in Hewlett Packard’s network business, and before that in storage, and before that in servers.)
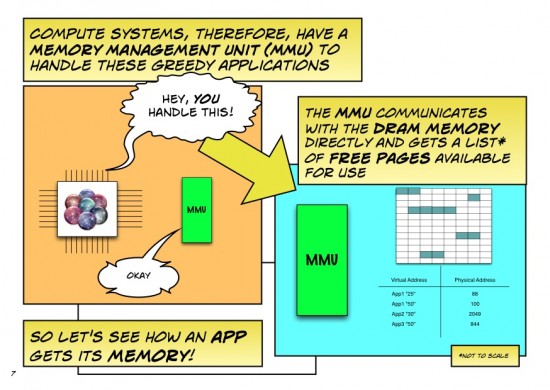
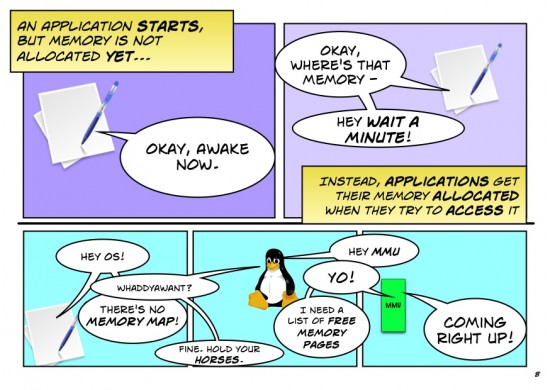
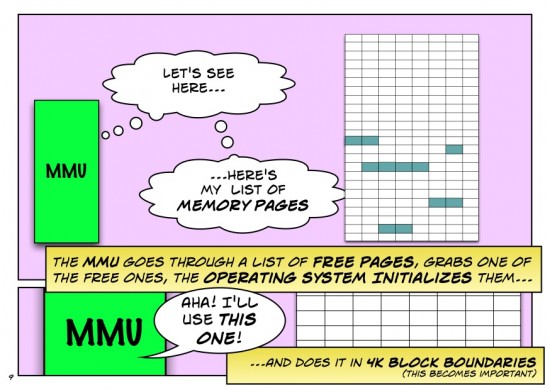
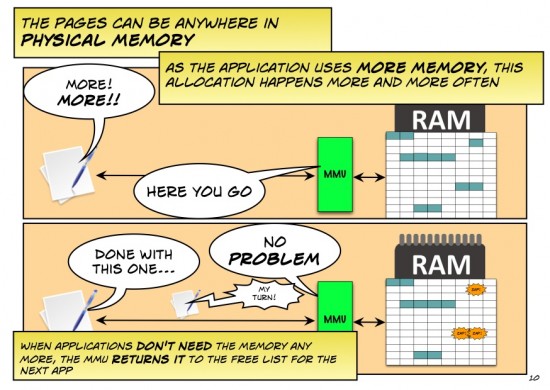
One nuance I’d encourage you to rework: the MMU itself is a very fast but very focused chunk of silicon in what now as a network person I’d call the data plane. Keeping track of free pages, making decisions on what hasn’t been used recently so can be moved to disk to free up space, is done in the operating system by the memory manager, or in networking terms it is done by the control plane. This is not unlike software learning of MAC addresses.
The primary role of the MMU is multitenancy: memory owned by this process (especially the kernel) can’t be read or written by any other process. A secondary role is translating the CPU’s “physical address” into a particular DRAM or row of DRAMs on a particular DIMM. Different processor designs may partition these functions and use various names for parts, but I think you correctly abstracted the data plane functions as “MMU”.
The primary role of the IO MMU is making memory access default-deny to I/O cards. It creates not just address mappings, but also opens up specific memory windows for a specific I/O cards to read or write.
So my nerd recommendation as a 30 years ago CPU designer is to rework slides 7-9 and 17, either separating the CPU’s hardware MMU from the operating system’s “memory manager” in the discussion, or inventing a generic term to include both.
@FStevenChalmers
Hi Steve,
Thanks for the comments, and you are absolutely right. To be fair, if I were giving a 400-level course instead of a napkins dialogue, I’d be paying closer attention to some of the nuances as you suggest. As I’m trying to bridge the gap of understanding from people in (admittedly extremely) broad strokes, As you can imagine it’s hard to capture the HW/SW divide as it varies between architectures. While the NS talks about MMU, in many architectures there is something else called a IOMMU. I had to draw the line somewhere between what is signal and what is noise.
I am reconsidering your points, however. If I want to add a little more detail, I could do that along with the disclaimer that your mileage may vary with respect to HW/SW partitioning. I just don’t want to get so mired in the minutiae that I lose sight of the forest through the trees and wind up making the ND a burden for people to read.
Besides, if you think this one glosses over some details, just wait until we talk about how data is written to disks…
*sigh*
🙂
Thanks again for the comment!
Outstanding. Even my kids enjoyed it and understood it.
Great! That’s the kind of feedback I love to hear! 🙂
Very nice! Looking forward to the next segments.. Thanks!
Great stuff!
Love the “comics” style
Nice post, the comics are good