
In the movie Top Gun, Tom Cruise had a famous line: “I feel the need–the need for speed!” When I talk to data scientists, they often express the same sentiment. Charged with the responsibility of mining value out of numerous data sources, they often feel that they need ever more speed to do their jobs quickly. To support the data scientists, IT teams are always looking for performance, scale, and flexibility. In fact, a recent Harvard Business Review article was titled Why Companies That Wait to Adopt AI May Never Catch Up. Clearly, the need for accelerating artificial intelligence and machine learning performance is critical to enterprise’s success.
Performance
In anticipation of Cisco Live Barcelona, I am excited to share some of the recent development on the UCS team to help customers to accelerate AI/ML deployment.
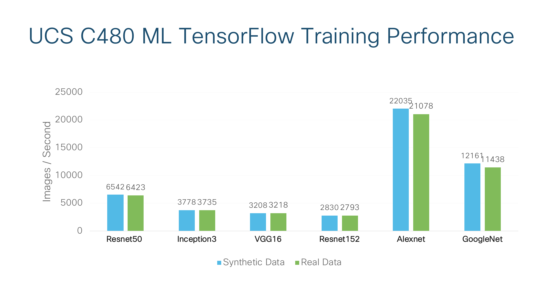
First, Cisco has published the performance characteristics of the UCS C480 ML. With 8 x NVIDIA V100 Tesla GPUs, this server is optimized for deep learning workloads as demonstrated with the various popular convolutional neural networks for image classification.
Scale
While the performance of a single server is important, customers are demanding that a cluster of servers to scale to increasing demands. At Cisco Live Barcelona, we are looking forward to show 2 demos.
NGC on Hortonworks 3
Many customers already have a big data lake, and almost everyone is looking to mine additional value out of the data. With Hortonworks 3, the Hadoop cluster is able to support containers running on CPUs and GPUs. This unified cluster architecture enables customers to do traditional data extract, transform, and load (ETL) before feeding the data to a deep learning algorithm. Since Cisco announced intent to support NVIDIA NGC-Ready program, which provides GPU enabled software containers, Cisco Live Barcelona will be the first time where Cisco demonstrate NGC containers running on UCS, in this case, as part of the Hortonworks cluster. In short, the Hortonworks Hadoop cluster is able to support the complete data pipeline.

NGC on Red Hat OpenShift
While some customers prefer Hadoop as the clustering tool, others are choosing Red Hat OpenShift as the Kubernetes container orchestrator with enterprise support. In Barcelona, we will also show NGC running on OpenShift enabling support for multiple data scientists with both interactive and batch workloads.

Flexibility
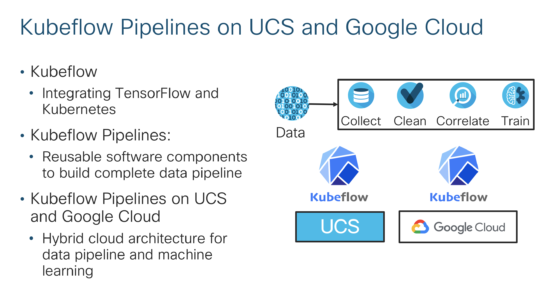
Kubeflow Pipelines
While many customers have the bulk of their data on-premise, some data scientists would like to do machine learning experiments in the cloud. In November, 2018, Google announced Kubeflow Pipelines. At Cisco Live Barcelona, in partnership with Google, Cisco will demonstrate Kubeflow Pipelines running on both Google Cloud and UCS enabling a true hybrid cloud experience.
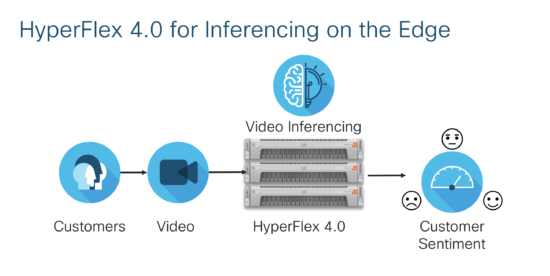
Inferencing on Hyperflex 4.0
Inferencing is also a critical part of machine learning. At Barcelona, we are also showcasing HyperFlex 4.0 as a edge computing system in a retail environment where video streams can be used for customer sentiment analysis.
Cisco Live Barcelona 2019
I can’t wait to share with all of you the UCS solutions that can accelerate artificial intelligence and machine learning adoption. With the raw performance of the UCS C480 ML, scale with Hortonworks 3 and Red Hat OpenShift, and flexibility with Kubeflow and inferencing on HyperFlex 4.0, I am looking forward to help our customers to make a genuine difference with the business problems.
Please stop by the following areas in the World of Solutions.
- Data Center
- Unlock the Power of Your Data
In addition, there are some other sessions that may be of interest.
- Accelerating Big Data and AI/ML with UCS and HyperFlex, PSODCN-2877 on January 28, 2019 at 2:45PM
- Living on the Edge Computing with New Cisco HyperFlex 4.0 & Intersight, PSODCN-2434 on January 29 at1:15 PM
- Consistent AI in the Hybrid Cloud, DEVNET-1649 on January 29, 2019 at 3:00 PM
- Google Cloud – Machine Learning in a Hybrid Cloud Environment with Kubeflow, BRKPAR-2400 on January 31, 2019 at 11:05 AM
- Towards #ConsistentAI with Cisco, Google, and NVIDIA, BRKCLD-2163, on January 31, 2019 at 2:30 PM
See you in Barcelona (#CLEUR).
@hanyang1234





