
If data is the new oil, then more refining capacity is needed. Many customers are leveraging the data to be part of the core competitive advantage. However, refining that data to become valuable, actionable information is difficult. Data collection and preparation take an inordinate amount of manual labor (80% of data scientist’s time). Difficult to guarantee success before the analysis is actually done. Internet of things is adding fuel to the fire with even more data than ever before. According to the Cisco Global Cloud Index, by 2021, 847 Zettabytes of data will be generated. In case you didn’t know, a zettabyte is a sextillion bytes (1021 or 270 bytes). While the exponents make sense to me mathematically, it is difficult to comprehend the magnitude of the data explosion coming in the next few years. While only 1.3 zettabytes will make it back to the data center, the amount of information will clearly easily overwhelm the best of efforts to make sense of the data glut.

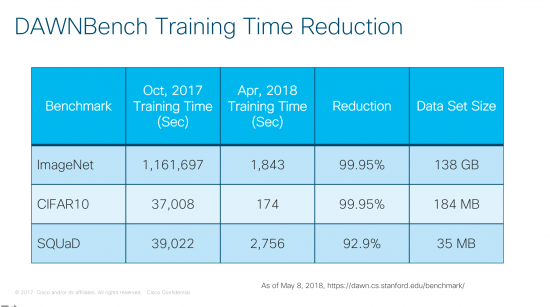
Artificial intelligence / machine learning / deep learning is viewed as an innovative way to absorb large amount of data. Clearly, this field has enjoyed breakthroughs in the past several years. McKinsey has even published article around the value of deep learning. In fact, even within the last few months, numerous organizations have submitted results to Stanford DAWNBench, a recent proposal for deep learning benchmark, where the deep learning training time has been reduced by several orders of magnitude. Much of the improvement has come from applying more hardware to the benchmark. In the case of the ImageNet benchmark, Google has used half of TPUv2 Pod (32 TPUs) to the problem to reduce the training time from over 13 days to just over 30 minutes. Unfortunately, the size data set for these benchmarks are simply tiny, especially when compared with the anticipated data glut as indicated in the Cisco Global Cloud Index.
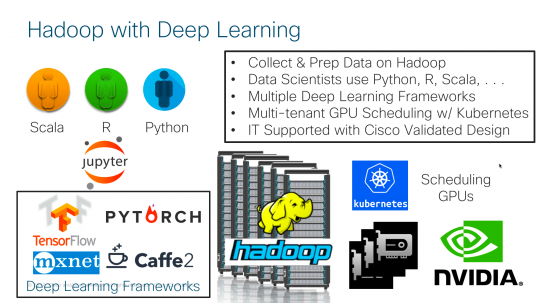
Here at Cisco, we love addressing customer challenges. As a first step, at the GPU Technology Conference here in San Jose back in March, we have already demonstrated the integration of Big Data cluster with TensorFlow running on GPUs, because 30% of the data stored in the datacenter by 2021 will be in big data clusters with 51% CAGR from 2016-2021. In addition, we are working to add KubeFlow to UCS enabling customers to have the flexibility to do the analytics in the cloud or on-premise. The journey to accommodate all this data won’t be easy, but I sure look forward to the challenge!
As part of the process to meet the challenge, we are continuing to work with software partners to improve performance and scale to help our customers to address the on-coming data glut. Please join us at Strata Data Conference in London next week at the session titled Incorporating Data Sources Inside and Outside the Data Center, Wednesday, May 23, 2018 at 2:55 PM to 3:35 PM to continue the conversation.






An interesting article on how refining data can be accelerated, Thank you
I love such data-based examples to demonstrate a point! Keep them coming!
Thank you for the article Han, I do appreciate this "knowledge pills" on what is coming, even if it does scare me a bit as a "network guy". Will have to adapt!
Thank you for the blog, that's all so true and allow me to add 3 statements from the market:
“Data is to AI what food is to humans” – Berry Smyth, Prof of Computer Science at University College Dublin
“Big Data is a Prerequisite for Deep Learning” – that’s from you Han….
“Analytics drives technology, AI = Analytics, if you want to lead in digital you must lead in analytics…” – Dr. Goodnight at SAS Global Forum