
The noisy neighbor syndrome on cloud computing infrastructures
The noisy neighbor syndrome (NNS) represents a problematic situation often found in multi-tenant infrastructures. IT professionals associate this figurative expression with cloud computing. It comes manifest when a co-tenant virtual machine monopolizes resources such as network bandwidth, disk I/O or CPU and memory. Ultimately, it will negatively affect performance of other VMs and applications. Without implementing proper safeguards, appropriate and predictable application performance is difficult to achieve, resulting into ensuing end user dissatisfaction.
The noisy neighbor syndrome originates from the sharing of common resources in some unfair way. In fact, in a world of finite resources, if someone takes more than licit, others will only get leftovers. To some extent, it is acceptable that some VMs utilize more resources than others. However, this should not come with a reduction in performance for the less pretentious VMs. This is arguably one of the main reasons for which many organizations prefer to avoid virtualizing their business-critical applications. This way they try to reduce the risk of exposing business critical systems to noisy neighbor conditions.
To tackle the noisy neighbor syndrome on hosts, different solutions have been considered. One possibility comes from reserving resources to applications. The downside is a reduction in the average infrastructure utilization. Moreover, it will increase cost and impose artificial limits to vertical scale of some workloads. Another possibility comes from rebalancing and optimizing workloads on hosts in a cluster. Tools like Cisco Intersight Workload Optimizer exist to resize or reallocate VMs to hosts for better performance. All this happens at the expense of an additional level of complexity.
In other cases, greedy workloads might be best served on a bare metal server rather than virtualized. Using bare metal instead of virtualized applications can address the noisy neighbor challenge at the host level. This is because bare metal servers are single tenant, with dedicated CPU and RAM resources. However, the network and the centralized storage system remain shared resources and so multi-tenant. Infrastructure over-commitment due to greedy workloads remains a possibility and that would limit overall performance.
The noisy neighbor syndrome on storage area networks
Generalizing the concept, the noisy neighbor syndrome can also be associated with storage area networks (SANs). In this case, it is more typically described in terms of congestion. There are four well-categorized situations determining congestion at the network level. They are poor link quality, lost or insufficient buffer credits, slow drain devices and link overutilization.
The noisy neighbor syndrome does not manifest in the presence of poor link quality or lost and insufficient buffer credits, nor with slow drain devices. That’s because they are essentially underperforming links or devices. The noisy neighbor syndrome is instead primarily associated to link overutilization. At the same time, the noisy neighbor terminology would refer to a server, not a disk. That’s because communication, either reads or writes, originates from initiators, not targets.
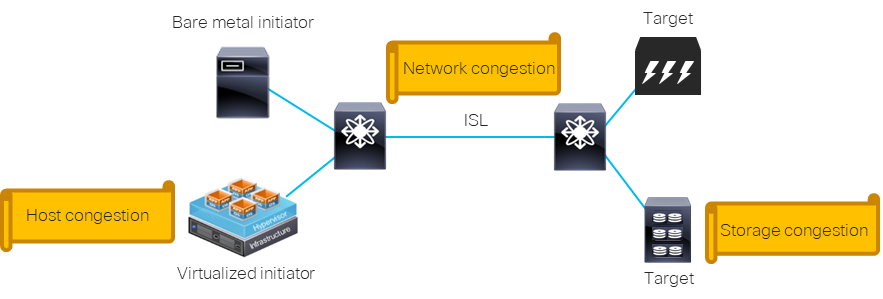
The SAN is a multi-tenant environment, hosting multiple applications and providing connectivity and data access to multiple servers. The noisy neighbor effect occurs when a rogue server or virtual machine uses a disproportionate quantity of the available network resources, such as bandwidth. This leaves insufficient resources for other end points on the same shared infrastructure, causing network performance issues.
The treatment for the noisy neighbor syndrome may happen at one or multiple levels, such as host, network, and storage level, depending on the specific circumstances. A common situational challenge presents when a backup application monopolizes bandwidth on ISLs for a long period of time. This may come to the performance detriment of other systems in the environment. In fact, other applications will be forced to reduce throughput or increase their wait time. This challenge is best solved at the network level. Another example is when a virtualized application is monopolizing the shared host connection. In this case, the solution might involve remediation at both the host and network level. Intuitively, this phenomenon becomes more pervasive as the number of hosts and applications increases in data center environments.
Strategies to solve the noisy neighbor syndrome
The solution to the noxious noisy neighbor syndrome is not found by statically assigning resources to all applications, in a democratic way. In fact, not all applications need the same quantity of resources or have the same priority. Dividing available resources in equal parts and assigning them to applications would not do justice to the heaviest and often mission critical ones. Also, the need for resources might change over time and be hard to predict with a level of accuracy.
The true solution for silencing noisy neighbors comes from ensuring any application in a shared infrastructure receives the necessary resources when needed. This is possible by designing and properly sizing the data center infrastructure. It should be able to sustain the aggregate load at any time and include ways to dynamically allocate resources based on needs. In other words, instead of provisioning your datacenter to average load, you should design to deal with the peak load or close to that.
At the storage network level, the best way to solve the noisy neighbor challenge is by doing a proper design and adding bandwidth, as well as frame buffers, to your SAN. At the same time, try making sure storage devices can handle input/output operations per second (IOPS) above and beyond the typical demand. Multiport all flash storage arrays can reach IOPS levels in the range of millions. Their adoption has virtually eliminated any storage I/O contention issues on the controllers and media, shifting the focus onto storage networks.
Overprovisioning of resources is an expensive strategy and not often a possibility. Some companies prefer to avoid this and postpone investments. They strive to find a balance between the cost of infrastructure and an acceptable level of performance. When shared resources are insufficient to satisfy all needs simultaneously, a possible line of defense comes from prioritization. This way, mission-critical applications will be served appropriately, while accepting that less important ones may get impacted.
Features like network and storage quality of service (QoS) can control IOPS and throughput for applications, limiting the noisy neighbor effect. By setting IOPS limits, port rate limits and network priority, we can control the quantity of resources each application receives. Therefore, no single server or application instance monopolizes resources and hinders the performance of others. The drawback of the QoS approach is the accretive administrative burden. It takes time to determine priority of individual applications and to configure the network and storage devices accordingly. This explains the low adoption of this methodology.
Another consideration is that traffic profile of applications changes over time. The fast detection and identification of SAN congestion might not be sufficient. The traditional methods for fixing SAN congestion are manual and unable to react quickly to changing traffic conditions. Ideally, always prefer a dynamic solution for adjusting the allocation of resources to applications.
Cisco MDS 9000 to the rescue
Cisco MDS 9000 Series of switches provides a set of nifty capabilities and high-fidelity metrics that can help address the noisy neighbor syndrome at the storage network layer. First and foremost, the availability of 64G FC technology coupled with a generous allocation of port buffers proves helpful in eliminating bandwidth bottlenecks, even on long distances. In addition, a proper design can alleviate network contention. This includes the use of a low oversubscription ratio and making sure ISL aggregate bandwidth matches or exceeds overall storage bandwidth.
Several monitoring options, including Cisco Port-Monitor (PMON) feature, can provide a policy-based configuration to detect, notify, and take automatic port-guard actions to prevent any form of congestion. Application prioritization can result from configuring QoS at the zone level. Port rate limits can impose an upper bound to voracious workloads. Automatic buffer credit recovery mechanisms, link diagnostic features and preventive link quality assessment using advanced Forward Error Correction techniques can help to address congestion from poor link quality or lost and insufficient buffer credits. The list of remedies includes Fabric Performance Impact Notification and Congestion Signals (FPIN), when host drivers and HBAs will support that standard-based feature. But there is more.
Cisco MDS Dynamic Ingress Rate Limiting (DIRL) software prevents congestion at the storage network level with an exclusive approach, based on an innovative buffer to buffer credit pacing mechanism. Not only does Cisco MDS DIRL software immediately detect situations of slow drain and overutilization in any network topology, but it also takes proper action to remediate. The goal is to reduce or eliminate the congestion by providing the end device the amount of data it can accept, not more. The result will be a dynamic allocation of bandwidth to all applications. This will eventually eliminate congestion from the SAN. What is exceedingly interesting about DIRL is its being network-centric and not requiring any compatibility with end hosts.
The diagram below shows a noisy neighbor host becoming active and monopolizing network resources, determining throughput degradation for two innocent hosts. Let’s now enable DIRL on the Cisco MDS switches. When repeating the same scenario, DIRL will prevent the same rogue host from monopolizing network resources and gradually adjust it to the performance level where innocent host will see no impact. With DIRL, the storage network will self-tune and reach a state where all the neighbors happily coexist.
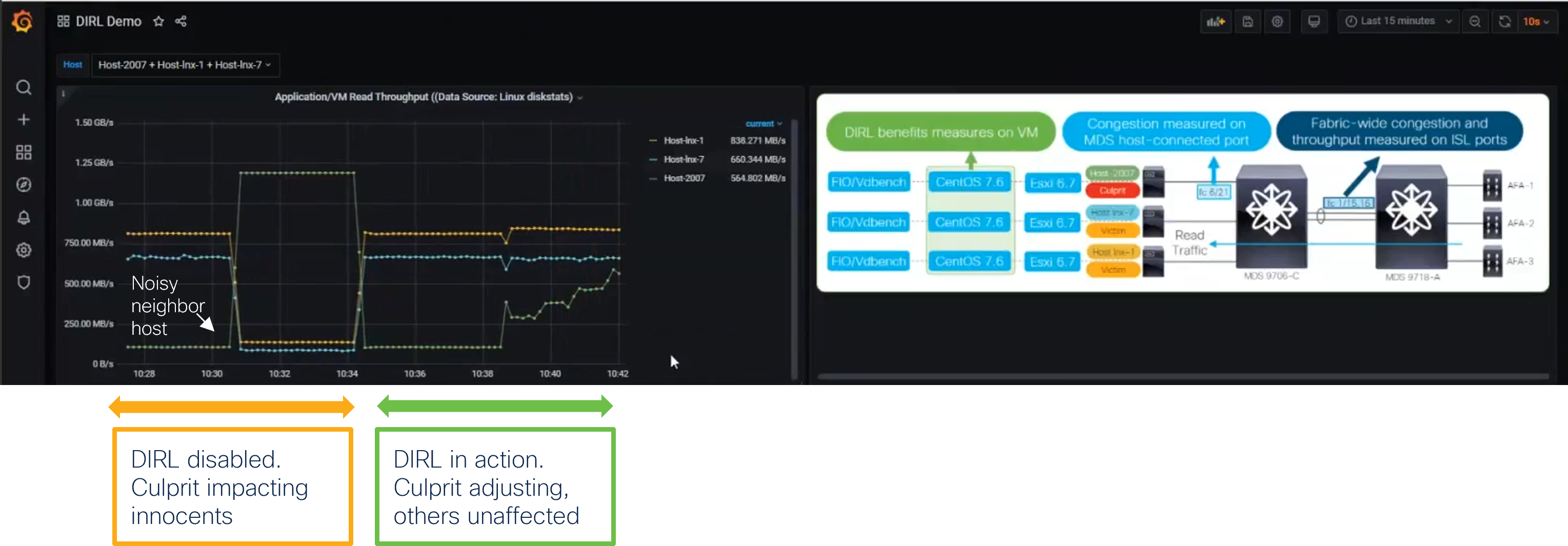
The trouble-free operation of the network can be verified by using the Nexus Dashboard Fabric Controller, the graphical management tool for Cisco SANs. Its slow drain analysis menu can report about situations of congestion at the port level and facilitate administrators with an easy to interpret color coding display. Similarly deep traffic visibility offered by SAN Insights feature can expose metrics at the FC flow level and in real time. This will further validate optimal network performance or help to evaluate possible design improvements.
Final note
In conclusion, Cisco MDS 9000 Series provides all necessary capabilities to contrast and eliminate the noisy neighbor syndrome at the storage network level. By combining proper network design with high-speed links, congestion avoidance techniques such as DIRL, slow drain analysis and SAN Insights, IT administrators can deliver an optimal data access solution on a shared network infrastructure. And don’t regret if your network and storage utilization is not coming close to 100%. In a way, that would be your safeguard against the noisy neighbor syndrome.
Resources
Miercom on-demand webinar on how to prevent SAN congestion
Miercom report: performance validation of Cisco MDS DIRL software
Slow-Drain Device Detection and SAN Congestion Prevention FAQ




