
Corporate IT is bombarded with requests that span every department – from lines of business to the board. In addition to their day-to-day responsibilities, IT teams need to ensure applications run smoothly and that users are happy, all while reducing the overall footprint and controlling costs both on-prem and in public clouds. In the uncertain economic climate, striking exactly the right balance between cost and performance is the name of the game when it comes to applications, and is key to creating business resiliency
Yet delivering applications that are performant and doing so at the lowest possible cost across on-prem and public cloud environments is no small task. It calls for the management of workloads in a way that considers many different resources – CPU, storage, memory available on bare metal servers, virtual machines (VMs), containers, public cloud instances, etc. – plus numerous control points for each device, and how devices and resources are used in relation to each other.
Modern workloads are too complex to manage manually
The challenge is made more complex because achieving optimal setup is effectively an ever-moving target due to:
- The increasing frequency of (application) workload updates and deriving a number of new deployments
- The growing number of placement options that an expanding multicloud environment affords
- Lack of end-to-end visibility of public cloud and on-premises changing costs, pre- and post-deployment
Such complexity means the implications and risk for each decision about where to place and how to size workloads increases exponentially. In such a dynamic environment, IT teams can find themselves struggling to meet the demands of their business as they end up spending their time chasing alerts and “fighting fires” instead of supporting a platform for innovation.
Besides the numbers challenge of manually optimizing dynamic workloads at scale, IT teams are also not usually designed and equipped with responsibilities, tools and expertise that can work across the infrastructure “stack.” There are teams of specialists responsible for different elements – i.e. servers, network, storage, virtualization, and public cloud. Each has their own view of the capacity and performance of their systems, but they work in silos using separate tools. They can design and implement actions to achieve local optimizations in their domain, but they the lack end-to-end visibility and thus risk introducing problems in other areas of the infrastructure.
A typical result can be unnecessary cost – and it is not minor. To avoid causing problems different teams would routinely choose public cloud instance sizes that are larger than necessary to ensure apps perform, which can result in excessive operational expenses. The same applies for on-premises environments when it comes to making selections on where to deploy workloads or making buying decisions to refresh data center physical infrastructure.
AIOps: letting machines manage machines
In order for operations teams to balance the pros and cons of every optimization action carefully, a holistic view of infrastructure and applications and their associated interdependencies is required. Given that no human can constantly optimize workloads effectively at “cloud scale and speed,” insights and automation powered by artificial intelligence become essential.
A potential solution to the challenges posed by disparate management tools, siloed IT teams, and a highly dynamic IT environment is based on these principles:
- Collecting and consolidating the information from all available sources in a single data lake
- Building a model that takes all the dependencies into account, instead of just showing data from different sources side-by-side
- Adopting a value-chain model that helps to analyze demand and availability of resources across the infrastructure stack, adopting standard market analysis patterns to choose the best among source for possible sourcing solutions
- Using what-if analysis to process possible scenarios and predict the outcome of possible optimization actions
- Applying intelligent analytics to match real-time workload resource demand to the underlying infrastructure supply
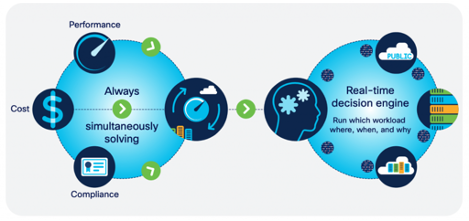
A consistent operating model and unified, full-stack view across the whole multicloud environment is a must for IT operations teams to have the visibility and insights required to make automated, real-time decisions on workload placement to assure application performance. AIOps, a term that has made its appearance in the industry three years ago, represents exactly that.
Overcoming complexity and scale with Cisco Intersight Workload Optimizer
Part of Cisco’s AIOps approach to helping customers tackle the above problem is based on Cisco Intersight Workload Optimizer, a real-time decision engine that was conceived on the list of principles above. It’s an agentless solution based on a virtual appliance and assures application performance by giving workloads the resources they need, when they need them.
To do this, it continuously analyzes workload consumption, costs, and compliance constraints, while automatically allocating resources in real-time, both on-premises and in public clouds. There are over 50 different sources of telemetry, including multiple public clouds, a variety of hypervisors, containers, applications, tools, and a broad range of infrastructure, referred to as “targets.”
Optimization Based on AI-assisted Analytics
Cisco Intersight Workload Optimizer is part of Cisco Intersight, a management platform that offers monitoring, policy management, hardware and software deployments, and IT operations automation in a single SaaS solution. As with all cloud-delivered solutions, it takes away the trouble of maintaining the software itself (setup, monitoring, upgrades, etc.) and provides full lifecycle management of the IT environment from anywhere – even from a mobile phone!
Intersight Workload Optimizer works with AppDynamics, Cisco’s application monitoring toolset, to further enhance and connect insights to the end-user experience and business outcomes. AppDynamics baselines application and business performance and identifies and flags changes in application performance that are the result of underlying resources constraints. This information is then shared with Workload Optimizer so that the software can make informed resourcing decisions and adjustments, enabling IT teams to:
- Avoid application performance issues with a unified view of infrastructure and applications and continuous, automated, analytics-powered infrastructure optimization that dynamically right-sizes resources to application demands, before IT staff and users experience a bottleneck
- Continuously optimize critical IT resources, resulting in more efficient use of existing infrastructure and lower operational costs for both on-premises and in public clouds
- Take the guesswork out of planning for the future with the ability to quickly model what-if scenarios – based on the real-time environment – to accurately forecast capacity needs.






Luca- this is well laid out, easy to understand and underlies the importance of helping our customers truly understand how to optimize cost and performance in these challenging times- DT