
“If you can not measure it, you can not improve it” — Lord Kelvin
The field of machine learning is progressing at a break-neck speed and new algorithms and techniques as well as performance improvements are being published at such a high frequency that it is impractical to keep pace. As expected, the research community, which in this field includes several corporate entities in addition to academic establishments, is open about its research findings, but the real hurdle in democratizing machine learning are the engineering issues that one is likely to face in moving ML from the lab to production.
The only open-source project that is making a serious attempt at solving the engineering issues of reliably scaling and deploying ML workloads is Kubeflow.
Kubeflow is dedicated to making deployments of machine learning workflows on Kubernetes simple, portable and scalable.
However, till very recently, the Kubeflow project did not have any benchmarking components thus making it impossible to evaluate the performance of the system when deployed on any underlying Kubernetes cluster. We at Cisco took the lead in working with the open source community to come up with a solution to this. We realized that whenever there is talk of performance, any enterprise needs to get clarity on at least the following issues:
- Which ML toolkit to use? There are quite a few of them available and there will probably be more in the future. Should it be TensorFlow, PyTorch, Caffe, or something else? The choice really depends on the performance of these toolkits in the specific problems that are relevant to the enterprise.
- How does the underlying infrastructure impact the performance? What is the performance of say, a Cisco UCS 480 ML M5? Does adding more containers or VMs improve the performance? Does adding GPUs improve the performance enough to justify the cost of purchasing GPUs?
Requirements
Based on the above mentioned issues, we came up with some requirements that an ML benchmarking platform should have. These requirements are generic and are not dependent on Kubeflow or any other specific system for implementing ML workloads. The picture below shows a schematic of the proposed benchmarking platform.
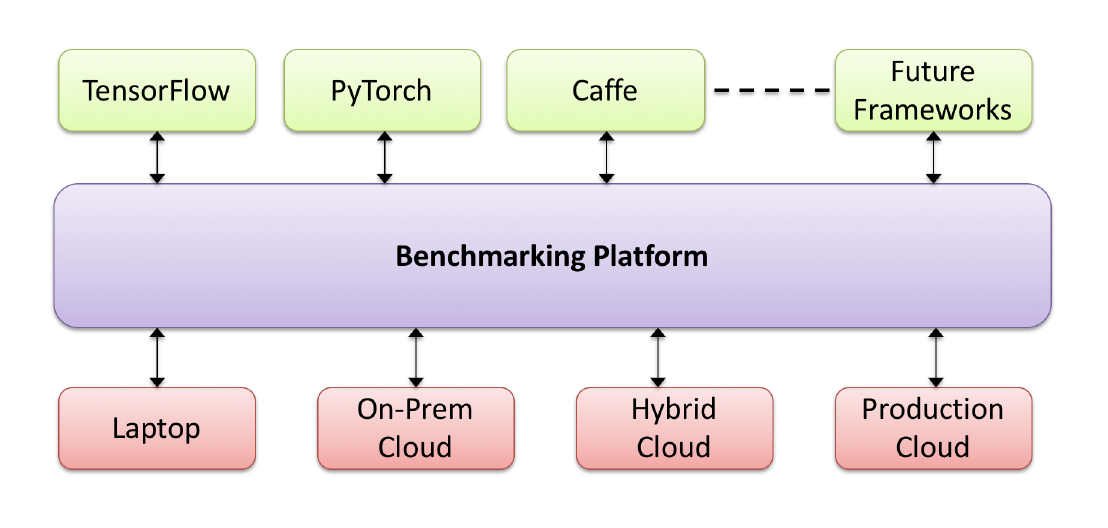
A benchmarking platform for ML workloads should satisfy, at least, the following requirements:
- It should support multiple ML frameworks. Since there are multiple frameworks such as TensorFlow and PyTorch available, the framework should support as many of them as possible and should be flexible enough to allow the addition of future toolkits.
- It should be portable. A key requirement is for the workloads to be able to easily move from one infrastructure to another so that any combination of CPUs, GPUs, and other custom processors, such as TPUs, can be handled.
- It should support extreme scalability. Realistic ML workloads are large and hence the benchmarking platform should also have the ability to scale to extreme sizes.
- And, it should be based on Open Source. At Cisco we take open source very seriously and we believe that even for this benchmarking effort, the design and implementation should be done in the open source community.
Design
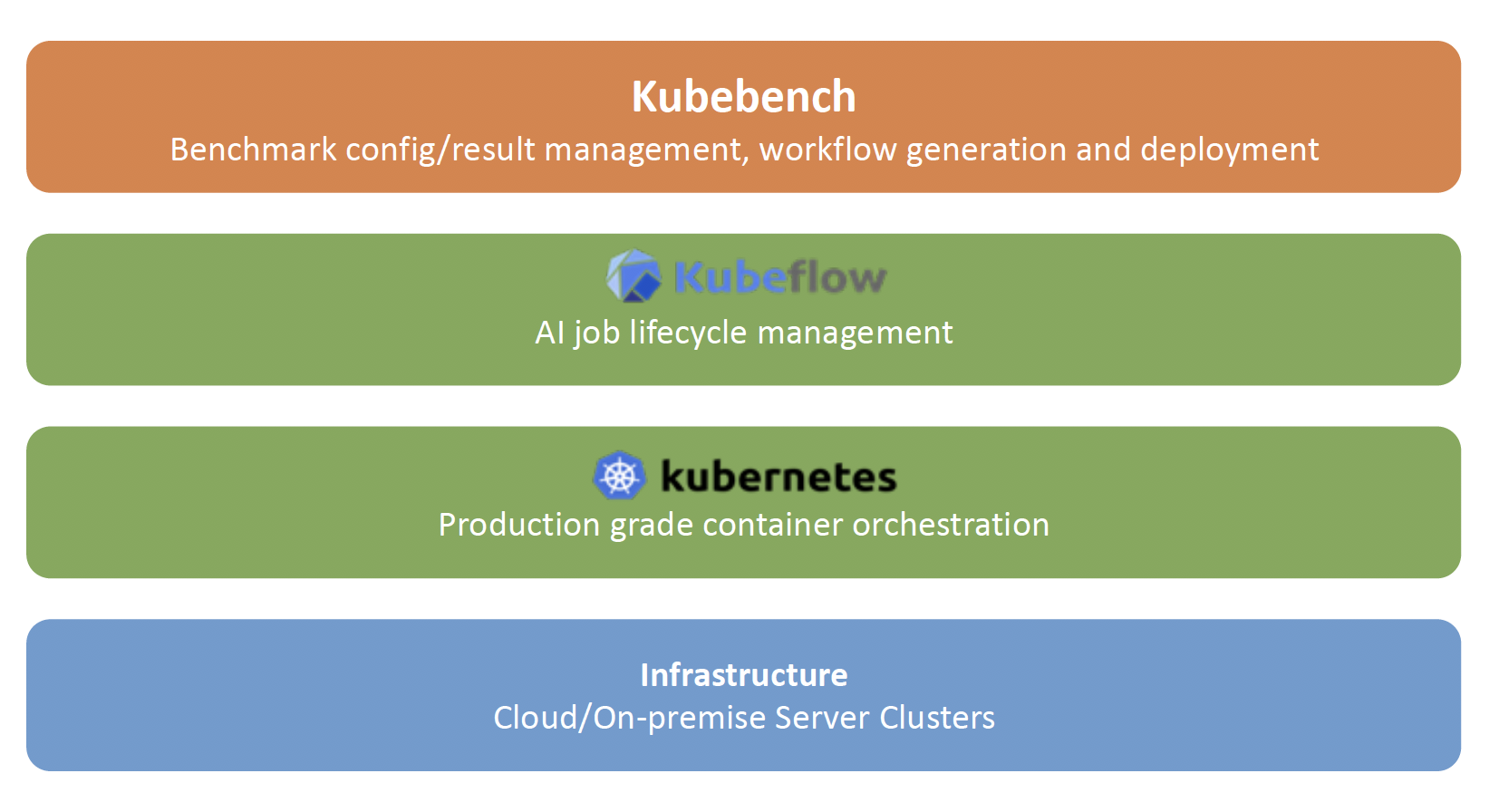
In order to satisfy the requirements, we came up with the design of Kubebench.
Kubebench is a harness for benchmarking and analyzing ML workloads on Kubernetes.
As shown in the figure, it runs on top of Kubeflow and is hence not directly dependent on the underlying infrastructure. Since it works on Kubeflow and Kubeflow works on Kubernetes (only), Kubebench also works on Kubernetes. This makes the benchmark platform immediately compatible with running benchmarking runs on any Kubernetes platform, allowing the benchmarking of workloads running at massive scale.
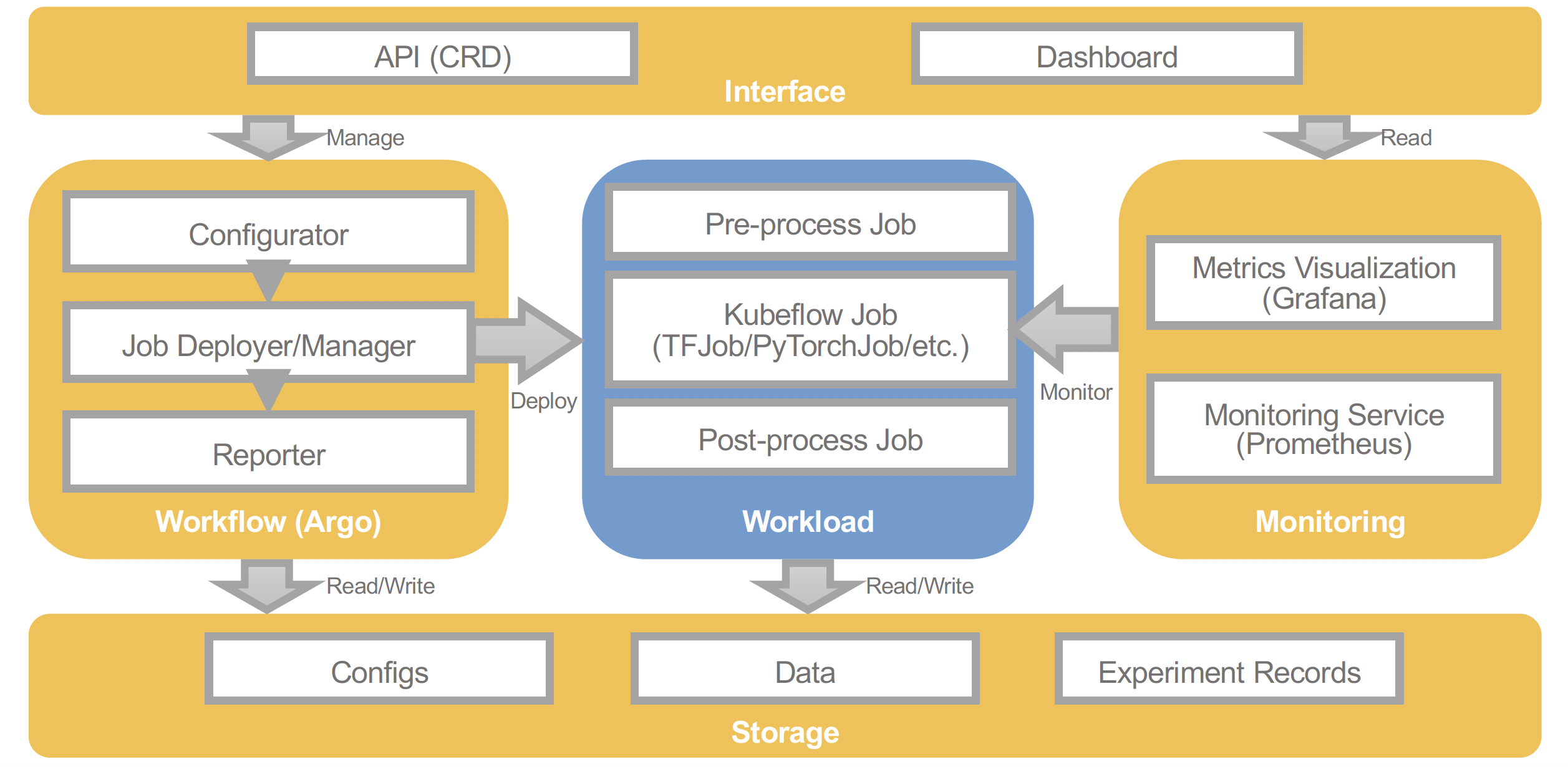
The picture below shows the overall architecture of Kubebench. The parts in yellow are what comes prepackaged in Kubebench and includes:
- an Interface that has an API to configure a workflow and a dashboard on which the user can view the results of running the benchmarks.
- The underlying storage stores the config of the benchmark job and the data generated by running the benchmark job.
- The monitoring and metric visualization service that monitors the workload and collects data that is used by the dashboard.
- There are also user defined components, marked in blue in the middle. These include the actual TensorFlow or PyTorch code related to the ML job that is to be benchmarled (currently Kubeflow officially supports TensorFlow and PyTorch only), a pre-processing job, and a post-processsing job.
For more details about Kubebench, interested readers are referred to our KubeCon + CloudNativeCon Talk and Slides.
Summary
In the current cacophony over Machine Learning (ML), one thing that is often forgotten, or at least not reported often enough, is the benchmarking of ML workloads. Kubebench has been a Cisco led open-source effort to develop an ML benchmarking platform for ML workloads on Kubernetes. We would like to express our deep gratitude to the numerous reviewers and contributors from the Kubeflow project.
References
- Kubebench: A Benchmarking Platform for ML Workloads – IEEE ai4i 2018 – Xinyuan Huang (Cisco), Amit Kumar Saha (Cisco), Debojyoti Dutta (Cisco), and Ce Gao (Caicloud)https://blogs.cisco.com/gcs/ciscoblogs/1/5c0fda3a560b9.pdf
- Presentation at KubeCon + CloudNativeCon, Shanghai, Nov, 2018. https://www.youtube.com/watch?v=9sLRIBYYUlQ – Xinyuan Huang (Cisco) and Ce Gao (Caicloud)
- The Kubebench repo on Github: https://github.com/kubeflow/kubebench
- The Kubeflow project: https://www.kubeflow.org/





