Infrastructure matters. It’s the foundation on which everything else in IT is built. The purpose of data center infrastructure is to run applications, yet the relationship between infrastructure admins and application developers is often dismal.
Are you an infrastructure admin? When’s the last time you talked to an application developer? Did you need a secret decoder ring for the terms they used? I bet they felt the same way. Developers often know exactly what kind of infrastructure they want and infrastructure admins are typically tasked with finding out what kind they actually need. That can be a tough conversation even without the language barrier.

Do your developers talk about AppFog? Sounds like something you might use to obfuscate code. Or maybe an app that helps you navigate San Francisco in the summer.
How about Docker? That’s a brand of comfortable, business casual trousers, right? Have you seen the Harbaugh commercial?
Did they ask about the network? Probably not. The average developer may view the network as, a) the clippy plug that goes into the side of a laptop, b) a WiFi SSID, or c) is something that starts with an inscrutable code like “3G,” “GSM” or “LTE”. They just want their app to be connected.
Have you heard a developer say, “VMs are heavy?” I have and I love this one. VM templates can become bloated as our definition of a standard baseline continues to expand. It’s sort of the nature of all things tech.

Did they mention CI or CD? I thought it might have something to do with music… or a disease. However my colleagues assure me that Continuous Integration and Continuous Deployment aren’t dangerous or contagious. I’m still not sure. Better wear a helmet.
All this conversation leads to what some call enterprise platform-as-a-service (PaaS) and others call IaaS+. In talking with enterprise customers, two primary audiences have emerged: Developers and SysAdmins. These two audiences speak very different languages and come at the problem from very different perspectives. In truth, it’s a continuation of the divide between IT Infra/Ops and IT’s internal customers (application developers), but adapted to the new cloud world.
Starting with a top-down view from a developer’s perspective, there’s immense interest in anything that speeds up the development process. CI and CD remain popular topics but more recently the developer community has started discussing “lighter-than-VM” containers such as OpenShift, Docker, Cloud Foundry (and derivatives like Pivotal, AppFog, and Stackato). The value can be crudely summed up as Use-Any-Language and Write-Once-Run-Anywhere using a “container” as an abstraction mechanism. To further oversimplify, I like to think about these containers as beefed up Java virtual machines (JVMs). Docker uses a shipping container analogy.

In most containers you can write in many different languages, you can move your app from container to container across machines, and you can deploy your app multiple times into one or multiple containers; even on the same machine and at the same time for horizontal scale and resilience. Generally no data is stored in there so you have to use something like external block storage accessed from your app via URIs, and that’s how you ensure data persistence and consistency across app instances. Of course we’re just scratching the surface, as there is a lot of other management and instrumentation options such package plug-ins (like a message bus for example).
Starting at the bottom with the infrastructure, SysAdmins from IT infrastructure & operations teams often don’t worry about app development. App development is something that occurs on a laptop or desktop, using Eclipse or Visual Studio (Emacs, anyone?). Eventually code is compiled and built and pushed to a server somewhere. But which server, where and what kind?
The SysAdmin helps ensure that the machine is there to run the app. Over the past several years, Infrastructure-as-a-Service (IaaS) has emerged as a mode for delivering those machines on-demand, automatically – whether through a public cloud or in a private cloud environment, and increasingly in a hybrid approach. (And despite all the debate it seems that nobody understands the cloud.)
However, there’s a gap between the Developer’s application and the SysAdmin’s infrastructure. Enter PaaS, including containers, to provide all the application prerequisites beyond the base OS and server. Now that these container systems provide the layer between apps and infrastructure, VMs can stay skinny and we have a more modular architecture. Everything below the container doesn’t really matter to the developer so they might start to ask the question, “Why do I need IaaS?”
This is confusing to the SysAdmin as everything needs infrastructure. But now they need to understand this new container layer: “What is OpenShift/AppFog/Docker? And why do the developers say that they don’t need a VM or a physical server or the network?”
There is a great slide in one of the Docker intro decks that talks about separation of duties. Reading between the lines, it shows the divide that I’ve been writing about (see the slide below):
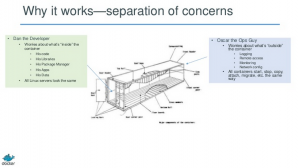
In this example, Dan the Developer worries about code, libraries, dependencies, and so on. Oscar the Ops Guy (aka SysAdmin) cares about things outside the container. It’s the same as it’s always been in that everything matters, but the container helps clarify who is responsible for what.
Network configuration is one example of something outside the container that demands true IT service delivery management. Stand up a container without proper network config and Oscar will quickly get a call from Dan complaining “the internets are down!” Imagine requesting a container you can’t reach, or one that doesn’t have the right firewall rules in place. The Write-Once-Run-Anywhere promise of Docker is a promise made to the Developer. The “Anywhere” on which it runs must still have the right processor architecture, host operating system, surrounding network, policy, governance, chargeback, and all the other requirements of running an actual service. This is not meant to be a ding on Docker, or AppFog, or any of them. It just highlights the two populations, and the need for a comprehensive solution. There are very few solutions out there (if any) that can effectively speak to both groups in their native languages.
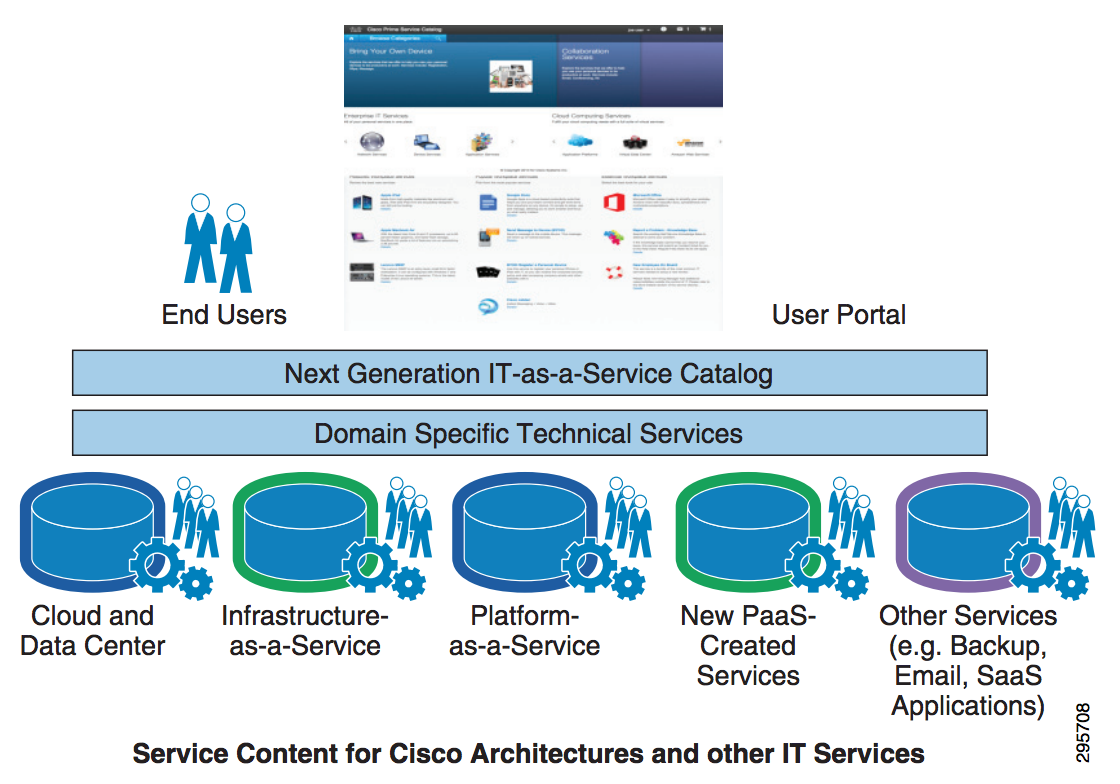
The need for rapid deployment, whether it be continuous delivery or self-service, is bringing these two audiences closer to one another. This alignment will serve everyone well in the future as applications expand in complexity and capability under continuous pressure to reduce cost.
However, we still have a ways to go and at least part of problem comes from the different context/view-points of the various groups involved. Most infrastructure & operations teams do not readily understand the AppFog, lighter-than-VM, container concept. Developers, on the other hand, get AppFog right off the bat and fail to understand why they would still need virtual machines, physical infrastructure, network configuration, or tools like Cisco Prime Service Catalog.
Containers need to go somewhere and run on something (just like JVM runs in an OS), and this somewhere/something is the infrastructure (virtual or physical). Container systems are only going to be as stable as the underlying infrastructure, and both the container layer and the infrastructure layer need to be managed (and automated and governed by policy, etc.). And while containers are currently the latest hot topic, there’s likely to be mixed adoption with more traditional IaaS for some time.
Deciding which deployment mechanism to use isn’t easy. But it can be aided by a service broker solution that combines a healthy dose of policy to automation/orchestration. Cisco Prime Service Catalog, often in conjunction with Cisco UCS Director for infrastructure automation, can act as the service broker layer in a hybrid cloud model. The decision to deploy apps via container or traditional IaaS, in a private or hosted cloud should be governed by a number of policies based on cost, security, compliance, corporate policy, etc.
In most cases today, these policies are in the form of a cumbersome manual process which is often bypassed, which in turn can lead to some very risky behavior. Maybe not so bad if you’re a small start-up, but potentially catastrophic if you’re handling financial records or medical data.
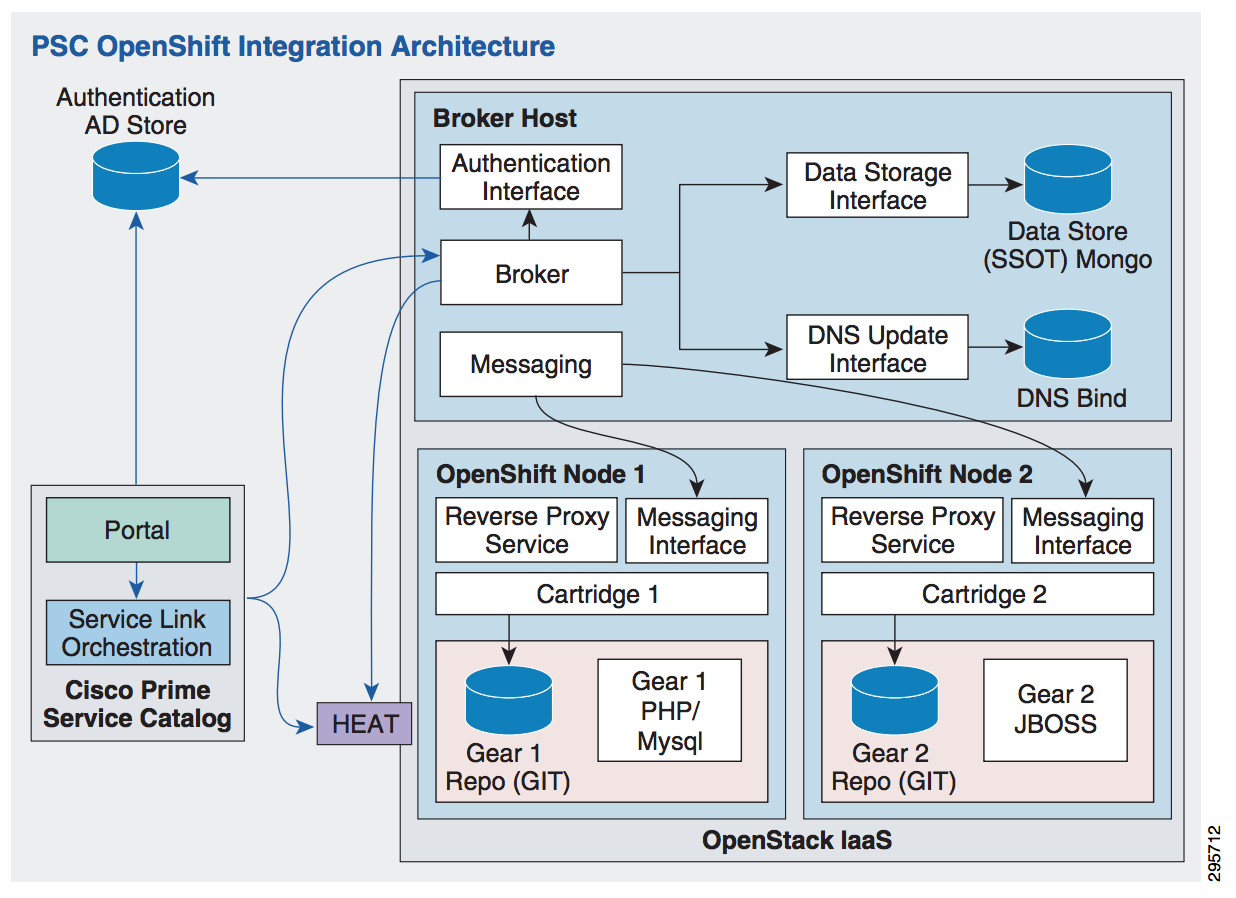
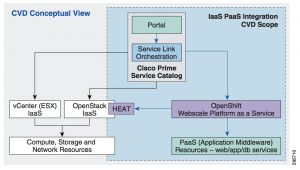
Many of the customers that I speak with want to put governance around this, but don’t know where to start. There are solutions that can help, like using Cisco Prime Service Catalog together with OpenShift for PaaS (as illustrated to the left), but technology is only part of the challenge. In fact, sometimes technology can be part of the problem – like when products are blindly adopted before a strategy is defined. Always good to know where you’re going before you start driving.
The bigger part of the challenge is actually cultural and organizational, sparked by this new technology (cloud, PaaS containers, etc.). I typically encourage customers to figure out how they want their culture to evolve first: “How should Developers and SysAdmins work together to improve the application development process?” Then incorporate policies, identifying those that are rigid and others that are more flexible. And then evaluate technology solutions like OpenShift, Docker, and Cisco’s management software. Implemented correctly, the expected cost savings from virtualization, automation and policy-based self-service can really add up. There are also time savings and “soft” savings from improved agility/flexibility, fungible resource management, etc.
The next step is a big one: What are you going to do with those savings?
Applying cost-savings to the bottom line is good, and sometimes necessary, but it can also be short sighted. The rate of tech innovation isn’t slowing down and neither are the demands placed on IT, so I encourage customers to apply those savings elsewhere to fund new, innovative projects that can help drive the business. Look for ways that new technology can solve problems or improve the status quo, and do it in an application-centric way, in the context of the core business and not just “IT tech projects.”
On the IT maturity curve, this is how to stop being reactive and transition from proactive to strategic. This is how IT infrastructure and operations teams can transition from being a cost-center to a valued partner for their application development counterparts and business constituents. Remember, infrastructure matters – but it’s all about the applications.




Hi
There is no denying the fact that data center Infrastructure plays a vital role in running various applications.
Docker-A grand brand name.;)
ccie data center rack rental