
What an event! Special thanks to all of our customers, partners and the amazing Cisco team for a great week at MPLS+SDN+NFV World Congress in Paris. We were able to engage with many Service Providers, hyper-scale Web 2.0 companies and the largest Enterprises, presenting Cisco’s vision of a fundamentally new way to think about the network. Watch the recording of my keynote session to hear more about the opportunity to reimagine the network.
Let me recap some of the main points that were part of my keynote, as well as many customer and partner conversations:
Network scalability

When it comes to upgrading mass-scale networks, operators have usually looked to bigger networking devices. This “scale up” approach has been driven by large, modular chassis device designs, where the scale-up is driven by ever-denser line cards. As an example, a single line card on an NCS 5500 router delivers up to 36 100GE ports and the larger NCS 5500 system, the NCS 5516, can have up to 16 of these. As the maximum limit of the chassis and line card is reached, the next step in scale-up is to tightly couple several chassis together to form a single larger router.
Despite some power and cooling benefits, the scale-up approach has historically come with a set of limitations:
- The absolute scale is limited by the maximum scale of the vendor’s device, multiplied by a small number as coupling breakdowns once the node count rises;
- Coupled systems also came with hidden complexity and required operators to customize daily operational tasks for these unique systems, compared to the more normalized single-chassis routers for which operational procedures were designed.
Network availability
 Service Providers and other mass-scale network operators have usually approached availability and resiliency with the assumption that large WAN network devices should fail very rarely. As such, vendors have been asked to make these systems resilient and reliable with a target between “five 9s” and “six 9s”. As one can imagine, it takes a significant effort in design, development and testing to engineering a multi-terabit router with annual downtime of approximately one minute.
Service Providers and other mass-scale network operators have usually approached availability and resiliency with the assumption that large WAN network devices should fail very rarely. As such, vendors have been asked to make these systems resilient and reliable with a target between “five 9s” and “six 9s”. As one can imagine, it takes a significant effort in design, development and testing to engineering a multi-terabit router with annual downtime of approximately one minute.
In addition to systems engineering, the industry has also designed and implemented complex software mechanisms and protocols to ensure ever higher levels of network resiliency and reliability, including:
- Nonstop forwarding and nonstop routing – when a route processor fails, the router keeps forwarding traffic during the switch-over to the redundant route processor;
- In-service software upgrade – allowing the application of bug fixes and the deployment of new features and services through an in-service upgrade of the on-box network operating system.
All of that has led to increasingly complex networking devices, from both an engineering and design perspective and from an operational perspective.
Enter fabric architectures
“Fabric” is a familiar concept in networking: think of the crossbar fabric inside a switch or the dedicated fabric modules in large routers – or even the fabric chassis in multi-chassis systems. Fabric architectures take that same idea into the wider network design, creating an interconnected mesh out of discrete devices.
Fabrics power a simple and cost-effective way to scale out network infrastructures. When operators need more bandwidth, they simply add more standardized elements to the fabric and do not face any absolute scale limitation. Moreover, fabrics do not come with any “hidden” complexity. The nodes in the fabric are loosely coupled with well-known, standard protocols that are easier to operationalize. The network can be scaled while maintaining a familiar network topology. Daily operations are simplified. Because a scaled-out fabric is built of many smaller nodes (instead of a few large ones), individual nodes can be costed out, upgraded and costed in without any service disruption. That also means new services can be introduced without impacting old ones.
Fabric architectures also bring noteworthy benefits to resiliency as they deliver many equal paths between network nodes, thus making the whole fabric highly resilient as the network can survive multiple network failures. Indeed, embedded in the fabric design is the assumption that “everything fails all the time.” Fabrics can absorb failure without impacting the entire system.
Automation and fabrics
Fabrics deliver better scalability and resiliency but add more devices that must be managed. Automation, combined with a fabric approach, facilitates a significant overall reduction in operational overhead and costs, even as the node count in the network rises significantly. 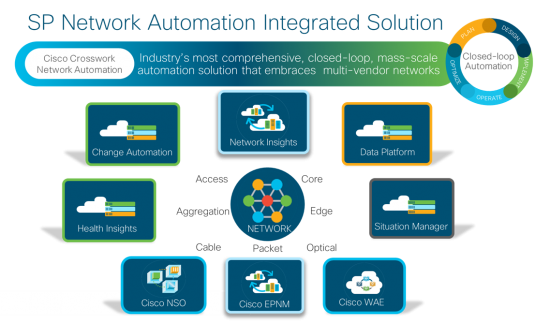
Our recently-announced Cisco Crosswork Network Automation portfolio is a perfect complement and enabler for the deployment of mass-scale fabric approaches for carrier WAN networks. With this automation suite, networks become easier to operate and can scale by device and node count without an operational impact. Read my blog for an overview of the new portfolio.
Beyond the physical topology
To get the most out of a fabric architecture, you need to extend the principles of simplicity, programmability and scalability beyond the physical topology. That’s why Segment Routing (SR) and Ethernet VPN (EVPN) are so important:
- SR delivers a unified data plane across aggregation, edge, core and data center network domains with unmatched simplicity. SR removes the need for a signalling protocol such as LDP. It adds resiliency, providing mechanisms to easily achieve 50ms protections covering 100 percent of possible network topologies. It enables the next level of scalability, as there is no longer a need to maintain state in the network. It also enables a comprehensive Traffic Engineering solution;
- EVPN provides a unified control plane capable of delivering Layer 2 and Layer 3 VPN services, helping Service Providers to fast-track their provisioning and delivery.
We are already seeing customers deploy both SR and EVPN, as recently announced with COLT.
Multi-vendor interoperability is another important aspect, as Service Providers do not want to be locked into a single solution. At the MPLS+SDN+NFV World Congress, the European Advanced Networking Test Center (EANTC) disclosed some notable interoperability test results on Segment Routing and Ethernet VPN. To learn more about the test results that involved Cisco, please read this blog from Sumeet Arora, Senior Vice President, Service Provider Network Systems at Cisco.
Last but not least, at the show we also announced some noteworthy additions to our routing portfolio to help Service Providers successfully navigate their Mass-Scale Networking journey.
We showcased some amazing technologies at the MPLS+SDN+NFV World Congress that are helping SPs transform their networks and evolve their operations. I look forward to continuing the conversation with everyone at next year’s event.




