
What doesn’t kill us makes us stronger. We resist gravity, and our muscles become stronger. We negotiate conflicts, and our emotional intelligence increases. But what if this also applied to IT systems? The next generation of networked systems could autonomously improve themselves as outside forces threaten them.
I and the rest of the Cisco Innovation team already believe blockchain is going to play an important role in securing data, but blockchain could also help entire networks learn to better protect themselves and intervene more quickly. I’ve been thinking a lot about this lately, inspired by Nassim Nicholas Taleb’s book Antifragile: Things That Gain from Disorder. He writes:
“Antifragility is beyond resilience or robustness. The resilient resists shocks and stays the same; the antifragile gets better. … The antifragile loves randomness and uncertainty, which also means — crucially — a love of errors, a certain class of errors. Antifragility has a singular property of allowing us to deal with the unknown, to do things without understanding them — and do them well. Let me be more aggressive: We are largely better at doing than we are at thinking, thanks to antifragility. I’d rather be dumb and antifragile than extremely smart and fragile, any time.”
We could take a lesson from this idea to design decentralized antifragile systems — whether they are business networks, applications or infrastructure — that become stronger the more people or machines try to break them. Blockchain technology offers specific advantages that all enterprise networks require — one single version of the truth, data immutability and automated processes among them. Combining blockchain technology with machine learning algorithms would allow multi-stakeholder systems to continually improve themselves, better react to challenges in the future and perhaps even anticipate potential problems.
I wrote an article last year about FCAPS, blockchain and trust that is relevant here. Anyone who works in telecommunications is at least tangentially familiar with the ISO/OSI and ITU network management models that shape our processes for fault, configuration, account, performance and security management — FCAPS.
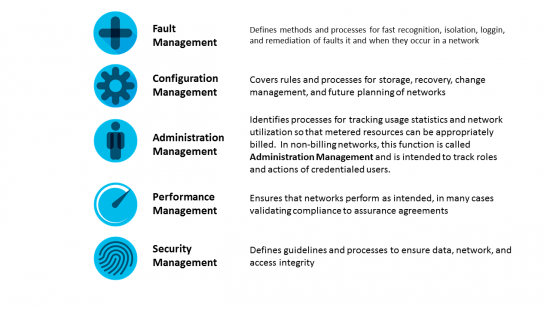
My theory is that setting up machine learning algorithms to constantly measure specific parameters and adjust themselves accordingly could allow those systems to learn new solutions to preserve their operation levels. You would break systems of trust down into key components and use tight feedback loops to record and respond to specific parameters. Those tightly defined parameters could evolve over time. In a multi-stakeholder ecosystem, each stakeholder would extend insights to the collective. So in essence, there is no one system of trust but a series of trusted domains, each independently serving a specific, special function.
Let’s say your system is designed to move data from one point to another point with some certain level of efficiency. Then a configuration change happens — perhaps it’s a simple user error or a malicious configuration change. The system could learn from that instance so that the next time such a change happens, the system can automatically correct it or alert an admin to the issue that would cause it to move out of spec. Now imagine these changes as a collection of events across multiple enterprise domains.
Extremely few environments today have only one vendor as the source of their technology. Just one data center will have multiple vendors involved, and you have to be sure that this heterogeneous system runs efficiently across all providers. Let’s say your business application spans multiple clouds — how do you ensure your product delivers the quality your customers expect if something happens to one of your service providers?
Some of these issues can be learned and prevented in the future to create more robust, responsive systems. This article proposing a manifesto for antifragile software from the University of Bologna is also interesting. Inspired by the Agile Manifesto, the researchers have laid out a common framework for making software that is antifragile; the principles could also be applied to making antifragile networks. The Antifragile Software Manifesto is all about building networks of trust and continuous improvement. Here are some highlights:
- Our highest priority is to satisfy the customer by building a non-linear, proactive, and self-adaptive system.
- All stakeholders, and the broader environment, lead the antifragile organization.
- Continuous exposure to faults and automatic fixing is the primary measure.
- An antifragile organization promotes a context aware environment. The stakeholders should be able to maintain a system indefinitely.
Sounds like enterprise blockchain, right? We are striving to create networks that are decentralized and self-adapting, with many stakeholders and built-in redundancy, where all participants have skin in the game but no one actor can sabotage it. Adding machine-learning algorithms that constantly improve these enterprise blockchain networks will even better protect the data and stakeholders involved.
For our enterprise clients, confidence and privacy of data are understandably very important matters. Sustaining these states can be accomplished using selective disclosure. You define who gets to see what information as you write data to a blockchain network. Policies should be set up in the network so data being posted is always compliant with the governance models all parties have agreed upon. Your users’ roles and responsibilities within the network will grant them the according degrees of access to information. So an auditor could be granted access to all information, but a data entry specialist would have only access to certain areas.
The next level would be creating a data overlay specifically for the purpose of providing algorithms access to ecosystem-attested data — data that is compliant, shared correctly and of high value. In theory, machine-learning algorithms may produce higher quality insights for antifragility as ecosystem-wide observations are shared. Infrastructure is a perfect example of a complicated system with many stakeholders and massive amounts of high-quality data for a machine-learning algorithm to munch on. Putting the blockchain in between infrastructure and machine learning would potentially give us the ability to increase quality for all users while maintaining control of data access and preventing tampering.
If you’d like to read more about Cisco’s take on blockchain, you will enjoy our whitepaper. And feel free to leave a comment if you have any thoughts to add on how blockchain could be integrated with machine learning to create smarter systems.




