
DevOps principles are not exclusive to software development, and some of them can definitely be applied to infrastructure configuration. NetDevOps brings the culture, technical methods, strategies and best practices of DevOps to network management.
Sometimes you might find it referred to by different names, like DevNetOps, NetOps, or SuperNetOps. But in general it is related to the more generic term Network Reliability Engineer (also coming from the DevOps counterpart Site Reliability Engineering).
The challenge of network configuration today
Networks exist to provide connectivity for end-systems and applications, so obviously they have a critical role in any type of service. Everything needs connectivity, so the network is certainly a fundamental asset in any modern enterprise these days. Its functionality has become so critical that most business nowadays would not be able to survive without connectivity.
However, there is a very common perception that the network is actually fragile.
Key network engineers that have been working long enough on a certain network become gurus. They are the ones that know the why and how of multiple specific configurations: why that had to be done last year on those core routers, how many neighbors should be seen by a certain edge router, or what that propagated BGP community means. Every box has a unique configuration to accommodate whatever was required at a specific point in time: troubleshooting or debugging a certain issue, that small fix in the routing protocol weight to determine the right interface to use, or those interfaces that are down and nobody knows if they should actually be up or not. Sequential and manual provisioning leads into a situation where each network device becomes a snowflake, due to how its configuration has changed organically according to whatever was required along since it was installed.
Without these key engineers there is a fear that network changes will go wrong. So, operations teams tend to minimize the number and frequency of changes in their networks. Nobody wants to affect their precious business traffic and be pointed at by the CTO as the person responsible for that big failure. So, changes rarely happen. And when they happen, they are BIG, because there is a backlog of things to do. The bigger the change, the more possibilities that something will fail. Besides this, teams are not well practiced because changes do not happen often. Fixing an issue while operating a network live, or performing a rollback quickly, requires practice. So now any problem that happens during the maintenance window will lead to the perception that the network configuration change was a failure.
Furthermore, applying network-wide policies becomes a task proportionally tedious to how big the network is. For example, consider a possible Infosec recommendation to change SNMP strings every month. Doing it manually in a big network might require a number of engineers performing those changes simultaneously across the network, maybe during a maintenance window by night to make sure systems can be synchronized next morning. This manual process involves quite some manual interaction, which is definitely prone to errors.
This type of considerations is very similar to the ones they had in classic software development. With their monolith architectures and bi-annual software updates, they suffered from similar challenges. And then they started doing things different, with things like Agile, DevOps, CICD pipelines and automated unit testing.
Applying this same type of principles to network configuration is what we called NetDevOps, and it will provide similar benefits to the ones software developers obtained while implementing this practices in their own environment. But it will require big cultural changes, like:
- Embracing failure and learning from it for the future
- Understand that change is good
- Collaborate actively between network developers and operations teams
- Empower teams to take ownership and responsibility
- Provide feedback systems that are actually useful to iterate and improve processes
- End-to-end automation for the whole life-cycle of changes
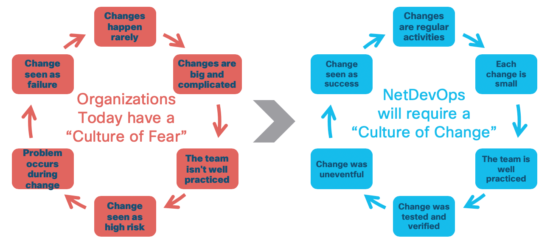
What if network engineers started working with network configurations the same way software developers work with their code?
What if we could create automated pipelines for those network configurations, that worked like CI/CD does for software development?
What if the network could be continuously monitored for health and improvement?
Now that would be a game changer. Not only in the way we manage our networks, but also in how we scale up, how we automate repetitive tasks, how different teams collaborate, and how we improve the reliability of our networks. Let’s explore it.
Network configuration as code
With the advent of Cloud computing we now have the capabilities to provision and manage ephemeral data center resources (compute and connectivity) via machine-readable definition files. These files can be treated as common code, utilizing the same version control systems and best practices we use for software development, with goals like providing automation, improving efficiency and reducing errors. This is called Infrastructure as Code, or IaC.
We could follow the same approach with network device configurations, and this is what we call Network as Code. It is based on the idea of storing all network configurations in a Version Control System (VCS) that manages and tracks changes in the network. This system, storing all configurations for the whole network, would be considered the Single Source of Truth for all-things network configuration.
In this new mode of operation, network configuration changes are proposed in code branches, like software code developers do. These branches are safe places where network developers will be able to work safely on their proposed configurations, without affecting the master branch, where master configurations reside. Once these new configurations are ready, developers will request their branch to be merged with the master configurations, and will go through an approval process to verify there are no issues when incorporating these changes.
Continuing with the emulation of DevOps automation capabilities, this will lead into using CICD (Continuous Integration and Delivery) Build Servers to automatically deploy and test the proposed configurations in testing, staging and production environments. Configurations that successfully pass the complete tests set, will be deployed into the production environment. In case of failure during that final deployment, the system itself will automatically rollback the proposed changes, leaving the production network in the previous state just before the change.
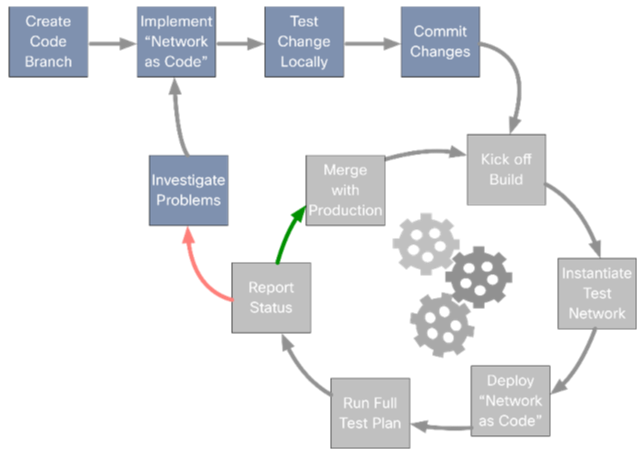
And considering that modern network devices support modern interfaces and APIs, let’s leverage those to deploy our configurations across the network in an optimal way, instead of using the classic, slow and error-prone command-line interface.
Following this strategy, we are now ready to start building a completely automated environment that can deploy and test configuration changes across the network. In my next posts we will start looking at some practical demonstrations of what can be done with NetDevOps tools.
See you next week, stay tuned!
Any questions or comments please let me know in the comments section below, Twitter or LinkedIn.
Join DevNet to access the learning labs, docs, and sandboxes you need for network automation. And check out the NetDevOpsLive! webinar series, and this expert-led, video course for learning network programmability basics.
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Twitter @CiscoDevNet | Facebook | LinkedIn
Visit the new Developer Video Channel






