
Posting this blog on behalf of Babi Seal, Senior Manager, Product Management, INSBU and Lukas Krattiger, Principal Engineer, INSBU
Virtual Extensible LAN or VXLAN for short has been around since 2011 as an enabling technology for scaling and securing large cloud data centers. Cisco was one of VXLAN’s lead innovators and proponents and have demonstrated it with a continual stream of new features and functionality. This momentum continues with our announcement of the newest Nexus OS release NX-OS 7.0(3)I7(1), also known as the “Greensboro” release; available for the Nexus 3000 and 9000 family of switches. This release is jam-packed with NX-OS innovations in the areas of security, routing and network management, only to name a few.
The series of blogs will highlight some exciting new VXLAN-related features shipping as part of the Greensboro release. In this blog, we’ll look closely at three individual features: Tenant Routed Multicast, Centralized Route Leaking support, and Policy-Based Routing with VXLAN. In the next blog we give a closer look on VXLAN Ethernet VPN (EVPN) Multi-Site support.
Tenant Routed Multicast (TRM)
This feature brings the efficiency of multicast delivery to VXLAN overlays. It is based on standards-based next-gen control plane (ngMVPN) described in IETF RFC 6513, 6514. TRM enables the delivery of customer Layer-3 multicast traffic in a multi-tenant fabric, and this in an efficient and resilient manner. The delivery of TRM fulfills on a promise we made years ago to improve Layer-3 overlay multicast functionality in our networks. The availability of TRM leapfrogs multicast forwarding in standards-based data center fabrics using VXLAN BGP EVPN.
While BGP EVPN provides control plane for unicast routing ngMVPN provides scalable multicast routing functionality. It follows an “always route” approach where every edge device (VTEP) with distributed IP Anycast Gateway for unicast becomes a Designated Router for Multicast. Bridged multicast forwarding is only present on the edge-devices (VTEP) where IGMP snooping optimizes the multicast forwarding to interested receivers. Every other multicast traffic beyond local delivery is efficiently routed.
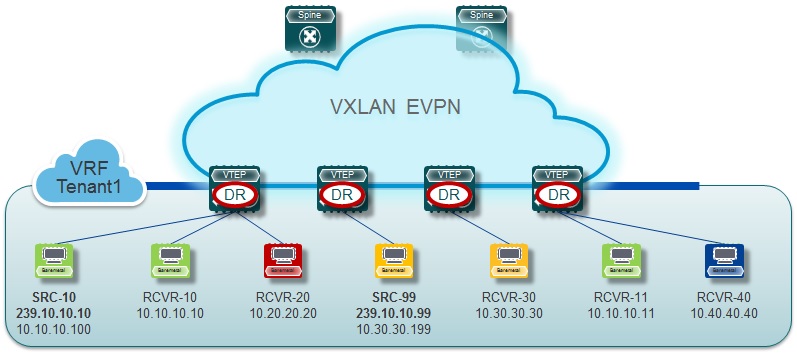
With TRM enabled, multicast forwarding in the underlay is leveraged to replicate VXLAN encapsulated routed multicast traffic. A Default Multicast Distribution Tree (Default-MDT) is built per-VRF. This is an addition to the existing multicast groups for Layer-2 VNI Broadcast, Unknown Unicast and Layer-2 multicast replication group. The individual multicast Group addresses in the overlay are mapped to the respective underlay multicast address for replication and transport. The advantage of using a BGP-based approach allows TRM to operate as fully distributed Overlay Rendezvous-Point (RP), with the RP presence on every edge-device (VTEP).
A multicast-enabled data center fabric is typically part of an overall multicast network. Multicast sources, receivers and even the multicast Rendezvous-Point might reside inside the data center but might also be inside the Campus or externally reachable via WAN. TRM allows seamless integration with existing multicast networks. It can leverage multicast Rendevous-Points external to the fabric. Furthermore, TRM allows for tenant-aware external connectivity using Layer-3 physical interfaces or sub-interfaces.
TRM builds on the Cisco Cloud Scale ASIC enabled Nexus-9000-EX/FX Series switches which are capable of VXLAN encapsulated multicast routing. Nevertheless the solution is backwards compatible with earlier generations of Nexus 9000-series of switches. It provides Distributed Anchor Designated Router (Anchor-DR) functionality to translate between TRM capable and non-TRM capable edge-devices (VTEPs). In this co-existence mode, multicast traffic is partially routed (on the TRM capable devices), but primarily bridged. One or more of these TRM capable edge-devices will perform the necessary gateway function between the “two worlds”. Not to forget, the co-existence can also extend to the Nexus 7000 family of switches.
Centralized Route Leaking
While segmentation is a prime use case for VXLAN based data center fabrics, there are also requirements for common Internet access and shared services. Multi-Protocol BGP supports safe route-leaking between Virtual Routing and Forwarding (VRF) instances by defining Route-Target policies for import and/or export respectively. Now Centralized Route Leaking enables VXLAN BGP EVPN with this well-known functionality and the related use cases.
Centralized Route Leaking enables customers to leak routes at one centralized point in the fabric, typically at the border leaf, which reduces the potential for introducing routing loops. Route leaking leverages the use of route-targets to control the import and export of routes. To attract the traffic traversing VRFs to the centralized location, we need to introduce default routes or less-specific subnet-routes/aggregates on the leaf-switches.
For the “Shared Internet Access” or “Shared Services VRF” use case, we allow the exchange of the BGP routing information from many VRF to a single shared VRF. In this case, the shared VRF can either be a named VRF or the already pre-defined “default” VRF. While the pre-defined “default” VRF has an absence of route-targets, Centralized Route Leaking incorporates the ability to leak route from and to the “default” VRF. While we highlighted the one-to-many or many-to-one possibility, Centralized Route Leaking also provides the same function in a one-to-one manner, where one VRF must communicate to another VRF.
All the various use cases have some commonalities, the exchanging of information between VRFs. As routing table can grow, Centralized Route Leaking uses a limit of prefix count as well as import- and export-filters. Not to forget, Centralized Route Leaking is a drop-in or on-a-stick feature; while all your VTEPs can reside on the existing Hardware and Software level, only the leaking point must support the software feature of Centralized Route Leaking.
Policy-Based Routing with VXLAN
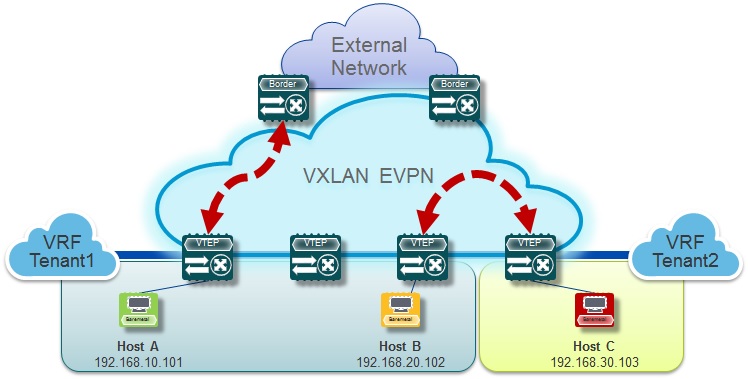
Cisco leap-frogged VXLAN routing years ago and extended its capability with a BGP EVPN control-plane. Beyond the traditional routing, there were always use cases that required additional classification for forwarding decisions. While in routing the destination IP network and longest-prefix match is till today the main criteria to forward, more sophisticated routing decisions are sometimes necessary. Policy-Based Routing is an approach to manipulate forwarding decisions by overruling the IP routing table decision. It does a 5-tuple match and uses a connected next-hop for its forwarding decision.
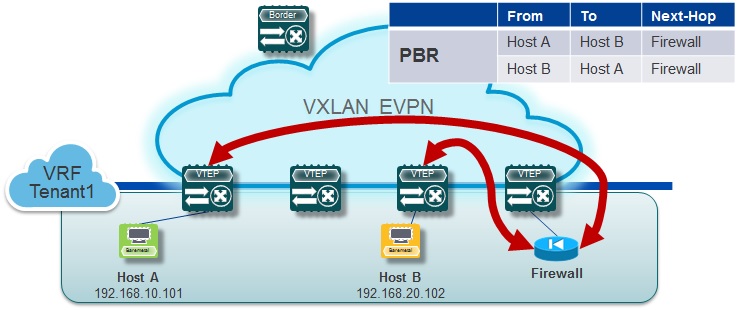
VXLAN enabled Policy-Based Routing (PBR) allows the user to leverage not just the traditional functionalities available to PBR, it provides the flexibility that the next-hop can now exist behind a VXLAN tunnel endpoint. With this approach, routing decision can be influenced to forward across a VXLAN BGP EVPN fabric. Redirecting specific traffic to a Firewall without VLAN or VRF stitching is only one of many Use Cases enabled with this additional support.
.
Stay tuned! In our next blog, we’ll examine the features and benefits of hierarchical VXLAN BGP EVPN based data center fabrics, that allow not only scaling and fault containment within a data center but also enhanced scalability, fault domain isolation, improved administrative controls, and plug-and-play extensibility.
Part 2 of 2:
VXLAN Innovations on the Nexus OS – part 2





An excellent summary ! Thank you Tony
There will be an addendum to the book “Building Dataceters with VXLAN BGP EVPN” describing this? TRM in primis is a key point in datacenters!
Yes. This book will be updated. Timeline not defined yet.
I see a problem with TRM. if every leaf is a multicast router that means that applications using link local multicast (i.e. TTL=1) will not work if servers in the same “layer 2 network” will be shared across multiple leafs. That;s personally a big concern
Tenant Routed Multicast (TRM) is a routed multicast solution as it is named. For application that don’t require Multicast routing, TRM can simply be disabled on a per-VNI base. Also, the well known link-local multicast groups are considered and specially treated.
Is “Policy-Based Routing with VXLAN” yet another method of doing “Service Chaining” in VXLAN ? Are their any other guides that explain this feature in more detail ?
Yes the impetus of Policy Based Routing with VXLAN was to integrate services into a VXLAN EVPN fabric. It is the same Policy Based Routing support [ https://www.cisco.com/c/en/us/td/docs/switches/datacenter/nexus9000/sw/7-x/unicast/configuration/guide/l3_cli_nxos/l3pbr.pdf ] with route-maps, ACLs except that now we can have the next-hop behind a VXLAN tunnel endpoint.
Policy-Based Routing with VXLAN — Here Host A to Host B traffic goes from Host A to Firewall directly ? does that means that Firewall is doing the vxlan decap and encap ? This description is not clear, can you please elaborate. The next-hop from one vtep is always other vtep right, then how it can bypass that ?
No the Firewall sits behind a VXLAN VTEP (Tunnel endpoint) switch. The VXLAN VTEP switch does the vxlan decap and encap. When we say “nexthop” in Policy-Based-Routing context – we are referring to the “set” predicate that goes with the “match” predicate. With this feature you can now “match” on l3-fields and “set” the policy-routed nexthop to be the vrf ip address (IPv4 or IPv6) of the Firewall.
here is part 2
https://blogs.cisco.com/datacenter/vxlan-innovations-vxlan-evpn-multi-site-part-2-of-2
Is there any plans to introduce this feature to 77k platform for F3 or M3 cards?
Or it`s just for particular ASICs on 9k?
The EVPN Multi-Site feature is based on innovation we brought into the Cisco CloudScale ASIC that is part of the Cisco Nexus 9000 Series of Switches.
We are evaluating the applicability of the EVPN Multi-Site feature against other platforms like the Cisco Nexus 7000/7700 with M3-based line-cards. Today, we already have “VXLAN BGP EVPN to OTV Interoperability” available as part of NX-OS 8.2 (https://www.cisco.com/c/en/us/td/docs/switches/datacenter/nexus7000/sw/vxlan/config/cisco_nexus7000_vxlan_config_guide_8x/cisco_nexus7000_vxlan_config_guide_8x_chapter_01001.html), which means Layer-2 technology stitching capability is possible. Layer-2 stitching capability will not be present on the Cisco Nexus 7000/7700 F3-based line-cards.
Tony, here I asked similar question but regarding to feature TRM)
Problem is that I have only 5672UP and 7706 with F3 at this monent.
And I have faced with choose decision for future, would it either M3 cards or new 9k switches