
At the June Hadoop Summit in San Jose, Hadoop was re-affirmed as the data center “killer app,” riding an avalanche of Enterprise Data, which is growing 50x annually through 2020. According to IDC, the Big Data market itself growing six times faster than the rest of IT. Every major tech company, old and new, is now driving Hadoop innovation, including Google, Yahoo, Facebook Microsoft, IBM, Intel and EMC – building value added solutions on open source contributions by Hortonworks, Cloudera and MAPR. Cisco’s surprisingly broad portfolio will be showcased at Strataconf in New York on Oct. 15 and at our October 21st executive webcast. In this third of a blog series, we preview the power of Application Centric Infrastructure for the emerging Hadoop eco-system.
Why Big Data?
Organizations of all sizes are gaining insight and creativity into use cases that leverage their own business data.

The use cases grow quickly as businesses realize their “ability to integrate all of the different sources of data and shape it in a way that allows business leaders to make informed decisions.” Hadoop enables customers to gain insight from both structure and unstructured data. Data Types and sources can include 1) Business Applications – OLTP, ERP, CRM systems, 2) Documents and emails 3) Web logs, 4) Social networks, 5) Machine/sensor generated, 6) Geo location data.
IT operational challenges
Even modest-sized jobs require clusters of 100 server nodes or more for seasonal business needs. While, Hadoop is designed for scale out of commodity hardware, most IT organizations face the challenge of extreme demand variations in bare-metal workloads (non-virtualizable). Furthermore, they are requested by multiple Lines of Business (LOB), with increasing urgency and frequency. Ultimately, 80% of the costs of managing Big Data workloads will be OpEx. How do IT organizations quickly, finish jobs and re-deploy resources? How do they improve utilization? How do they maintain security and isolation of data in a shared production infrastructure?
And with the release of Hadoop 2.0 almost a year ago, cluster sizes are growing due to:
- Expanding data sources and use-cases
- A mixture of different workload types on the same infrastructure
- A variety of analytics processes
In Hadoop 1.x, compute performance was paramount. But in Hadoop 2.x, network capabilities will be the focus, due to larger clusters, more data types, more processes and mixed workloads. (see Fig. 1)
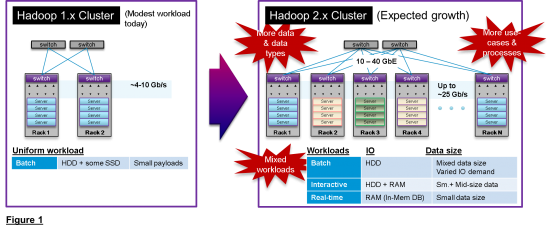
ACI powers Hadoop 2.x
Cisco’s Application Centric Infrastructure is a new operational model enabling Fast IT. ACI provides a common policy-based programming approach across the entire ACI-ready infrastructure, beginning with the network and extending to all its connected end points. This drastically reduces cost and complexity for Hadoop 2.0. ACI uses Application Policy to:
– Dynamically optimize cluster performance in the network
– Redeploy resources automatically for new workloads for improved utilization
– Ensure isolation of users and data as resources are deployments change
Let’s review each of these in order:
Cluster Network Performance: It’s crucial to improve traffic latency and throughput across the network, not just within each server.
- Hadoop copies and distributes data across servers to maximize reliability on commodity hardware.
- The large collection of processes in Hadoop 2.0 are usually spread across different racks.
- Mixed workloads in Hadoop 2.0, support interactive and real-time jobs, resulting in the use of more on-board memory and different payload sizes.
As a result, server IO bandwidth is increasing which will place loads on 10 gigabit networks. ACI policy works with deep telemetry embedded in each Nexus 9000 leaf switch to monitor and adapt to network conditions.
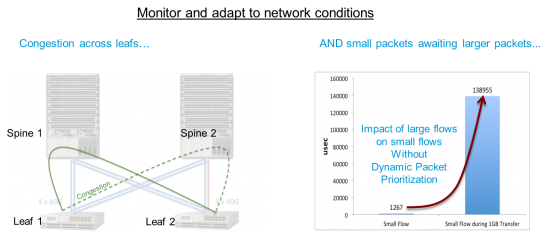
Using policy, ACI can dynamically 1) load-balance Big Data flows across racks on alternate paths and 2) prioritize small data flows ahead of large flows (which use the network much less frequently but use up Bandwidth and Buffer). Both of these can dramatically reducing network congestion. In lab tests, we are seeing flow completion nearly an order of magnitude faster (for some mixed workloads) than without these policies enabled. ACI can also estimate and prioritize job completion. This will be important as Big Data workloads become pervasive across the Enterprise. For a complete discussion of ACI’s performance impact, please see a detailed presentation by Samuel Kommu, chief engineer at Cisco for optimizing Big Data workloads.
Resource Utilization: In general, the bigger the cluster, the faster the completion time. But since Big Data jobs are initially infrequent, CIOs must balance responsiveness against utilization. It is simply impractical for many mid-sized companies to dedicate large clusters for the occasional surge in Big Data demand. ACI enables organizations to quickly redeploy cluster resources from Hadoop to other sporadic workloads (such as CRM, Ecommerce, ERP and Inventory) and back. For example, the same resources could run Hadoop jobs nightly or weekly when other demands are lighter. Resources can be bare-metal or virtual depending on workload needs. (see Figure 2)
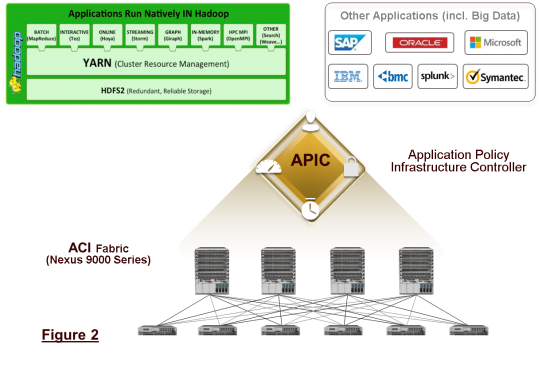
How does this work? ACI uses application policy profiles to programmatically re-provision the infrastructure. IT can use a different profile to describe different application’s needs including the Hadoop eco-system. The profile contains application’s network policies, which are used by the Application Policy Infrastructure controller in to a complete network topology. The same profile contains compute and storage policies used by other tools, such as Cisco UCS Director, to provisioning compute and storage.
Data Isolation and Security: In a mature Big Data environment, Hadoop processing can occur between many data sources and clients. Data is most vulnerable during job transitions or re-deployment to other applications. Multiple corporate data bases and users need to be correctly to ensure compliance. A patch work of security software such as perimeter security is error prone, static and consumes administrative resources.
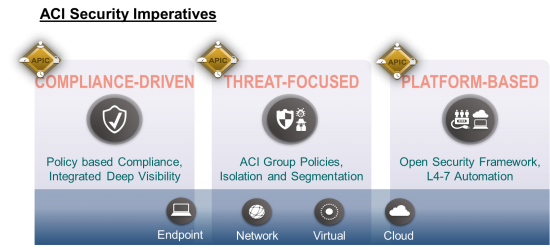
In contrast, ACI can automatically isolate the entire data path through a programmable fabric according to pre-defined policies. Access policies for data vaults can be preserved throughout the network when the data is in motion. This can be accomplished even in a shared production infrastructure across physical and virtual end points.
Conclusion
As organizations of all sizes discover ways to use Big Data for business insights, their infrastructure must become far more performant, adaptable and secure. Investments in fabric, compute and storage must be leveraged across, multiple Big Data processes and other business applications with agility and operational simplicity.
Leading the growth of Big Data, the Hadoop 2.x eco-system will place particular stresses on data center fabrics. New mixed workloads are already using 10 Gigabit capacity in larger clusters and will soon demand 40 Gigabit fabrics. Network traffic needs continuous optimization to improve completion times. End to end data paths must use consistent security policies between multiple data sources and clients. And the sharp surges in bare-metal workloads will demand much more agile ways to swap workloads and improve utilization.
Cisco’s Application Centric Infrastructure leverages a new operational and consumption model for Big Data resources. It dynamically translates existing policies for applications, data and clients in to fully provisioned networks, compute and storage. . Working with Nexus 9000 telemetry, ACI can continuously optimize traffic paths and enforce policies consistently as workloads change. The solution provides a seamless transition to the new demands of Big Data.
To hear about Cisco’s broader solution portfolio be sure to for register for the October 21st executive webcast ‘Unlock Your Competitive Edge with Cisco Big Data Solutions.’ And stay tuned for the next blog in the series, from Andrew Blaisdell, which showcases the ability to predictably deliver intelligence-driven insights and actions.



