
What do you get when you cross iSCSI with lossless Ethernet? A lot of confusion.
I do quite a lot of presentations regarding converged networks, including Fibre Channel, whether native or over Ethernet (i.e., FCoE), iSCSI, NAS, etc. The hardest part about these presentations are combating some of the expectations that audiences have, considering they may come from server backgrounds, network backgrounds, or storage backgrounds.
Why is this important? Quite frankly, because like fish who don’t know they live in the water, they have come to grow unaware of their own environmental backgrounds. They tend to forget the assumptions with which they make their decisions. Ethernet and Fibre Channel networking people have very different fundamental philosophies about the way their networks run.
In the world of converged networks, this can cause some, er, unintended consequences.
The Confusion
Recently I had a friend – we’ll call him Pete (because that’s the first fictional name that came to mind) stop by while I was having lunch and ask if he could “ask a quick question.”
(Why is it that the questions are quick, but the answers are so, so long? Just one of those ponderables of life, I suppose.)
“Sure, what’s up?” I said. It’s not like I was hungry anyway.
“I’ve been trying to figure out this whole converged networking thing,” Pete said, and I could see he wasn’t sure what the right words to use were.
“You mean FCoE?” I asked. Usually most of the questions I get surround FCoE. Go figure. Quelle Surprise!
“No, actually, iSCSI.”
“Okay, sure,” I said. “What’s the question?” Technically speaking, iSCSI is a convergence technology. You can run block-level storage on a VLAN running over the same equipment that handles traditional Ethernet. We’ve been doing this for years.
Pete took a deep breath, and then blurted out, “I’ve been told that you can do converged networks with iSCSI, but in order to do converged networks we need to use DCB, so does that mean that we have to run iSCSI over DCB?”
Now it was my turn to be confused. “I’m confused,” I said. Coy about my feelings, I am. “By DCB, do you mean lossless Ethernet?”
Pete nodded.
“Well,” I said, “It may be that the problem you’re having is that DCB is not the same thing as lossless.”
Pete looked like he was about to cry. “What?!” he said. “But everyone keeps saying that you need DCB for FCoE because it’s lossless and that’s how you get converged networks…” His voice trailed off.
I motioned for him to take a seat. He did. I reached over to grab a napkin and pulled out a pen. “Let me try to clarify a couple of things,” I said. Indicating the napkin I said, “I hope you don’t mind, I tend to think visually.”
He nodded. I swear, he was pouting. “Cheer up,” I said. “We’ll get you on the right page.”
Clearing up the Terminology
Let’s try to break it down a little. “DCB” is actually a category of standard documents. It’s not just one particular thing,” I said, starting to write everything down.

“You see,” I said, tapping at each of the different lines, “there are many parts of DCB, not just lossless. The important thing to keep in mind is that just because something is included as part of the standard, doesn’t mean it’s required for every single case.”
Pete nodded. I took a bite of my food, and instantly regretted it. I hate talking with my mouth full.
“Take thith, for exthample,” I said, trying not to spit food across the table, and swallowed hurriedly. I pointed to the last line on the napkin. “While this is part of the DCB, it doesn’t apply in all convergence cases. You don’t need this for FCoE, for example.”
“Why not?” Pete asked.
I waved my hand. “It’s a bit long to get into it, but I’ll send you the link to that later. For now, let’s just say that these documents are designed to help you understand a way to solve a problem. It’s not necessarily the only way, just a way that the industry had standardized. Make sense?”
“So far,” he admitted.
“So,” I continued. “When someone says that you need DCB, they may be talking about one of the solutions in one of these documents, or two, but not necessarily any specific one of them. You certainly don’t need to do all of them for every possible problem.”
“Okay,” he said. “So what are they talking about when they say they need DCB for iSCSI?”
iSCSI and DCB
“That’s a good question,” I admitted. “I’m not sure what they mean. We’ve been doing converged networks with iSCSI and LAN for a while now, and we certainly don’t need to do DCB in order for that to work.”
“But I keep hearing about ‘Lossless iSCSI,'” he protested. “Don’t you need DCB to do that?”
“Well, yeah,” I said. “That’s kind of written into the name, isn’t it? But do you need all of DCB to make it work? Or just the lossless part?”
He thought about that for a minute. “A fair point,” he said.
“It seems to me that if you’re going to be making a DCB argument for iSCSI – assuming we’re not talking lossless here – then you really could use the ETS part of the standard for guaranteeing minimum bandwidth.”
“What do you mean?”
“When you start looking at running iSCSI on 10GbE links,” I said, drawing, “If you want to set aside a minimum amount of bandwidth, well, ETS can help with that.”
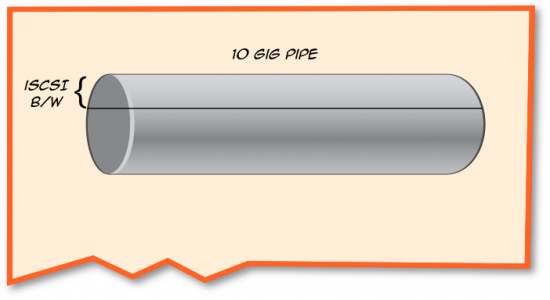
“What does it do?” Peter asked.
“Effectively it allows you to place bandwidth into groups and assign bandwidth percentages to those groups,” I said. “For instance, if you want to give iSCSI 30% of the bandwidth of this pipe, you could do that. With Cisco switches we accomplish this through our QoS settings.”
Peter stroked his chin thoughtfully. “And you don’t need DCB – I mean, lossless – for this?”
“Not unless you want to run lossless iSCSI,” I said. “But you have to be very clear on why you would want to do that.”
Peter’s eyes grew wide. “Yes, exactly!” he said. “That’s what I need to know!”
I took this as an opportunity to grab another bite of my lunch. “Can you be more specific?” I asked, grimacing at the food. It was cold. I should have ordered a salad.
“So if we can have lossless traffic for Fibre Channel and FCoE, won’t it help with iSCSI too? Why don’t we run all iSCSI traffic over lossless Ethernet?”
“Because we have different design principles for lossy traffic like iSCSI than we do for lossless traffic like Fibre Channel and FCoE,” I replied.
“But it’s all block storage, right?” he asked.
“Yes, that’s true,” I said. “But how a server accesses data on a storage array is a separate issue than how we network that access to the storage.”
I could see by the look on his face that I lost him. Out came napkin number 3.
“Look at it this way,” I said. “One of the things that makes iSCSI so popular is that it doesn’t require all the know-how that Fibre Channel does. It’s not as specialized, right?”
Peter nodded.
“One of the beautiful things about iSCSI is that, not only is it cheap, but the network itself does a lot of the heavy lifting for you. All you need are the IP addresses of the host and target and then the network takes care of the rest.”
He frowned. “There’s more to it than that,” he said.
“Yes, I know,” I said, a little more dismissively than I meant. “But in essence setting up iSCSI is easy because there are a lot of things you don’t have to do that you would in a Fibre Channel environment.”
“True.”
The Tyranny of SCSI
“Okay,” I continued. “Let’s start off with SCSI. SCSI makes some assumptions about the way these two devices talk to each other. For instance, SCSI assumes that there is a 1-to-1 relationship between host and target, and that the exchanges between the two devices are always in sequence.”
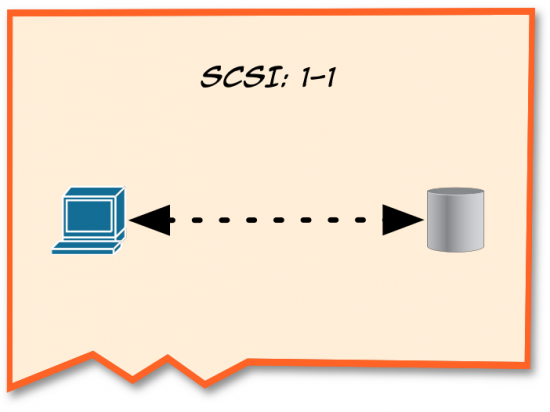
“And SCSI can’t do error correction,” Peter interjected.
“Well,” I said, hesitantly, “technically it can, but it’s so difficult and can be done in so few cases that for all intents and purposes it’s useless for what we’re trying to do here.”
“Thanks,” Peter said sarcastically. “Way to be pedantic.”
I looked at him for a moment. “Anywaaaaaay…”
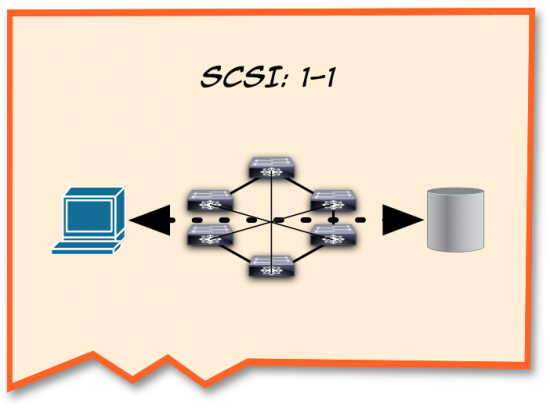
“When we moved the disk outside of the host and inserted a network in between them,” I continued drawing on the napkin until I had a respectable mockup of a network (sometimes my artwork amazes even myself). “We still had to maintain that 1:1 relationship, right?”
“Right.”
“So, this is one of the reasons why FC requires a lossless network in the first place: it is very difficult to fix the data if it gets out of sequence or if frames get dropped. But that’s not what happens in iSCSI.”
“With iSCSI we use TCP to create sessions between the host and the target, so that when Ethernet packets get sent all crazy-like over the network -” I drew squiggles across the napkin – “TCP will keep track of the sequence and reassemble them in order and present it to the SCSI layer.”
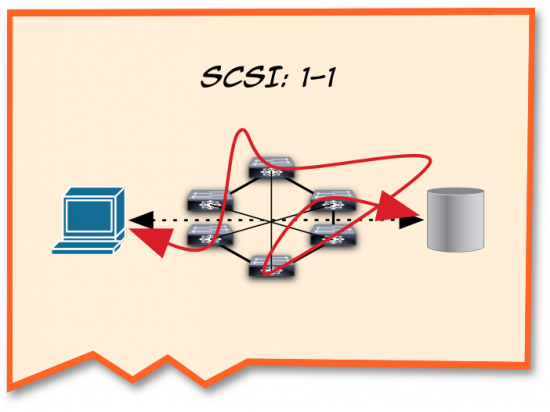
“Voilá!” I grinned. “In-order SCSI – over a lossy Ethernet network! I’m exaggerating a bit, of course, but the point here is that no matter which way the packets take to get to the storage, SCSI still needs to be happy.”
“Very nice,” Peter said. “So why do people want lossless iSCSI?”
Lossless iSCSI
I shrugged. “Traditionally, iSCSI has suffered from performance concerns when compared to Fibre Channel. It made sense a while ago, back when Ethernet was running at 1Gig speeds while FC went from 2 to 4 to 8 Gb. The extra serialization in a TCP/IP header also means that there were some impacts on latency.”
“But we’re using 10Gb Ethernet now. Even 40Gb,” he countered.
“Yes, that’s true. But bandwidth is not the same thing as latency,” I said. “Having the extra bandwidth is very useful for all kinds of traffic, it’s true. A lossless iSCSI connection would mean, in theory, that you could simply use the lower latency capabilities of lossless Ethernet to make iSCSI really sing.”
“But you can’t?” Peter asked.
I shook my head. “No, of course you can. But whether you’re talking about Fibre Channel or FCoE or any other type of lossless environment, you design for the lossless environment, not the protocol. Otherwise you can wind up getting really bad performance.”
“Why?
I pointed to the latest napkin. “See this squiggle here? I know this isn’t drawn to scale, but if you were to take this to a Fibre Channel or FCoE storage architect he would freak. We simply don’t allow traffic to do this in a lossless world.
“But what about iSCSI?” I asked, rhetorically. “Effectively any kind of traffic pattern that could happen in a TCP/IP world could affect iSCSI, right?”
He nodded.
“Which means that right from the start we have very different architectures to take into consideration,” I said. “You’ve seen some of the Ethernet networks. How many switches might you have between a host and a storage target using Ethernet?”
He shrugged. “I have no idea.”
“Exactly,” I said, nodding. “Could be one, could be one hundred. Who knows?”
“Well, maybe not a hundred,” he said, drawing his words out, skeptically.
“Now who’s being pedantic?” I retorted, smiling. “You get the idea. We just don’t know. In lossless environments, however, we do know.”
I started drawing on a new napkin.
“With lossless, whether we’re talking about FC or FCoE,” I said, struggling to talk and draw at the same time. Thank God I wasn’t trying to chew gum. “We have a very clear set of topologies that we play with. We want to make sure our storage is close to the host, because that gives us the best performance. As a result we usually only have one or two switches in between.”
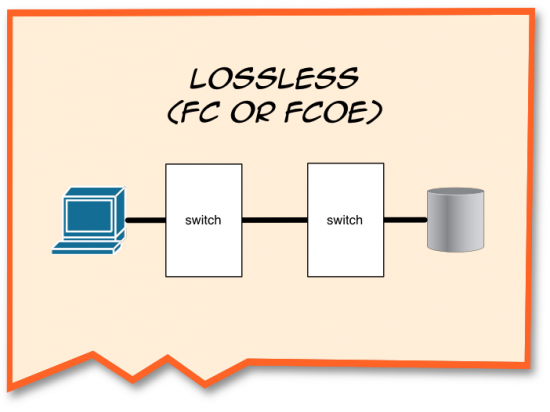
“That’s the ‘edge-core-edge’ topology,” Peter offered.
“Right,” I agreed. “Really large environments can have three, but it’s very, very rare to have any more than that. We do this so that we can keep our bandwidth under tight control with low oversubscription and fan-in ratios.”
Peter blinked.
I paused, and realized I’d need to explain a little more. I drew a few more lines on the napkin for emphasis. “Different applications have different types of traffic. Some times they’re very bursty, or irregular. Sometimes they’re sustained,” I said. “Since we want to make sure that all our traffic is processed, we need to make sure we strike a balance between the number of servers we have and the amount of bandwidth we have going to the storage.”
“How do you know the right numbers to use?” Peter asked.
“Storage vendors generally provide guidance in this process,” I admitted. “It depends heavily on what kind of applications we’re talking about. Usually the ratios are between 4-to-1 to around 20-to-1.”
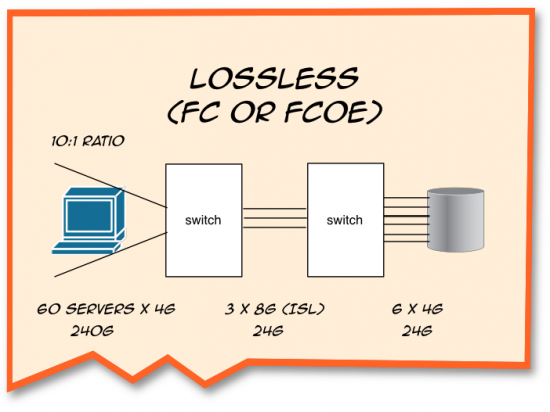
I tapped the napkin. “The key thing to remember is that every time we design a Fibre Channel or FCoE SAN we have to take into account the oversubscription ratio. Take this example. Here we have 60 servers running at 4G speeds connecting to 3 8GFC ISLs connected to six 4Gb FC links to storage. The fan-in ratio – that is, the number of bandwidth from servers to bandwidth to storage – is at the ratio of 10:1.”
Peter looked troubled. “I thought that it wasn’t true 8G, though.”
“You’re right,” I said. “But the important part here is the ratio, which is correct.”
“Okay,” he said. “But can’t we do this with iSCSI?
“Well, if we’re going to do lossless iSCSI, we pretty much have to take these same issues into consideration. But the fan-in ratio can be an order of magnitude greater – or more!”
Head-of-Line Blocking
“So what would happen if you did this with iSCSI?” Peter asked.
“There’s always a chance in a lossless network for Head of Line Blocking,” I said as I pulled another napkin, realizing I had started quite a collection. “Let me give you an example.”
“Let’s suppose that you have 1G connections from your servers into a 10G array,” I tried to sketch something out quickly so as not to lose momentum. “And let’s say, for the sake of simplicity, that you have steady traffic from all of these servers going up to the target.”

“So far, everything looks copacetic, right?
“Yup,” Peter confirmed.
“What happens when you start getting a bursty traffic from a source, like this guy here on the left, that saturates the link?” I said, with melodramatic suspense.
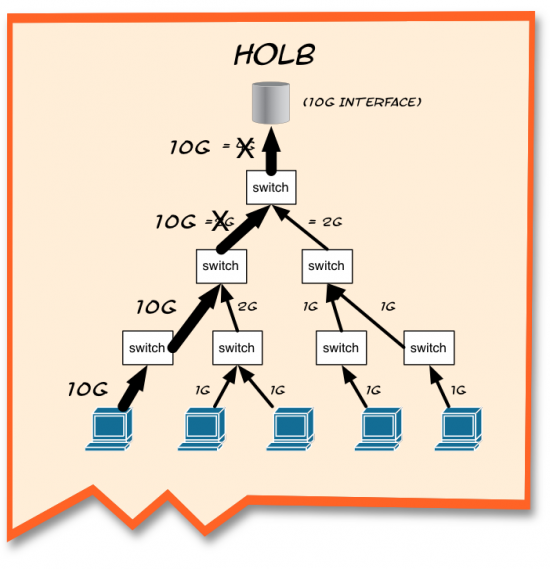
“We’ve got congestion,” Peter offered.
“You got it,” I confirmed. “Normally what happens is that the TCP session will renegotiate with the host in order to reduce the transmission window sizes. But since that’s layer 4, and lossless traffic happens at layer 2, this will happen before TCP gets a chance to kick in.”
I pointed to the top switch. “This guy is getting hit pretty hard. He’s got 12G coming in, but can only process 10G at a time. So, the lossless “no-drop” traffic is queued and the buffers begin to fill up.”
I raised my hands to demonstrate a rising water level. “When we get to that high water mark, PFC kicks in, and sends PAUSE frames down the links,” I said, drawing on the napkin again.
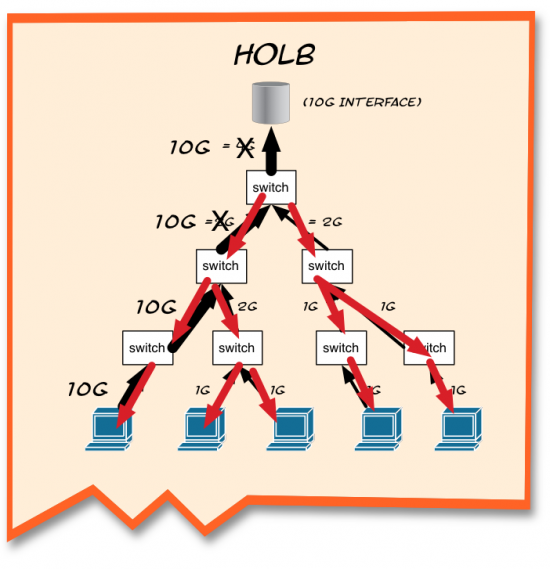
“So,” I said, looking up from the napkin. ‘Congratulations. Everything is flow controlled.”
Peter looked confused. “But everything is paused!”
“Yup. It’s controlled.” I couldn’t suppress a sardonic smirk.
“So this happens in Fibre Channel?” he asked, dubious.
“It can,” I admitted, “which is why we control for these types of behaviors with predetermined traffic engineering for our SANs. We carefully calculate the oversubscription ratios, the fan-in ratios, and make sure that we’re operating within tight parameters.”
“Besides,” I said, collecting the napkins, “in Fibre Channel this Head-of-Line-Blocking is a transitory event. Once some BB Credits are returned to the blocked port, the port can send again. In a PAUSE situation, though, there are no BB_Credits. With PAUSE, it’s on a timer.”
“But what about TCP?” he asked.
I shrugged. “TCP isn’t invoked immediately, because frames are PAUSED, not dropped. At this point, TCP doesn’t enter into it. But you raise an excellent point: what about TCP?”
What About TCP?
“See, TCP is session-based,” I said, tapping the pen between the host and the target. “This means a couple of things.
“First, in a normal iSCSI environment TCP would handle all the appropriate window sizing between the two entities here. That means that in this lossless environment you can wind up locking out all of the hosts as the PAUSE timers work themselves out, instead of letting TCP do its job.
“Second, and most importantly,” I said, “If you’re not careful, there is the potential for really messing up the session altogether and closing it, even possibly losing data.”
Peter’s eyes widened. “What? How?”
“Simple, son.” I said in my best Strother Martin impression. “What we have here, is a failure to communicate.”
Peter looked at me blankly.
“Cool Hand Luke?” I asked. “No?” I sighed. No one appreciates the classics any more.
“If you’re interested, we can probably go through this another time,” I said, glancing at my food. Longingly. “For now, let’s keep it simple. TCP adjusts its transmission window based upon how much data it can process at any given time.”
“Because of this, the window can shrink just as easily as it can grow. But, in order to do this, it has to send information back to the host. But what if that connection is PAUSEd?” I hinted.
“The client might not know that it can’t send as much data,” Peter was nodding as he was speaking. He was starting to get it.
“RIght,” I said. “So, if the client has already sent out information, but is paused somewhere in the network, the target can’t take the additional information and anything over and beyond that will need to be dropped. Not only does this really defeat the purpose of a no-drop transmission, but will force the client to retransmit the data and there goes the efficiency.”
“Can’t you prevent the window from shrinking?” Peter asked.
I nodded. “Yes, in fact TCP has a simple knob that does just that: you can force a device to not be allowed allowed to shrink the window. In order to do that, though, you have to make the target more patient. That is, it has to wait longer to reduce the buffer size, which of course prolongs the congestion time.”
“Not only that, but sometimes TCP will reduce the window size all the way down to zero. Since the same window is negotiated on both the host and the target, you are effectively shutting down the storage connection altogether. This may be fine for file-based storage, but with block-based storage – especially booting-from-SAN – you’re going to find yourself in some pretty sticky situations if that happens.”
Peter gulped. “Can’t you just reopen the window?”
I nodded. “Of course, but the problem is that the host is dependent upon receipt of the “window opening” segment. If that traffic is PAUSEd…”
Peter nodded and finished the thought for me. “The host terminates the connection.”
I tapped my nose and pointed at him. “Spot on,” I said. “There are ways to prevent this from happening – or try to – like sending special probes out, but even this isn’t perfect. When the target decides to reopen the window, it might reopen it at too small a value, which in turn creates many small segments, which in turn reduces the overall efficiency. And that’s just at the TCP level, which assumes that the traffic is flowing at Layer 2.”
“And this type of environment,” Peter said, thinking it through, “is exactly the kind of situation to be impacted by traffic being PAUSEd at Layer 2.”
“Yup,” I agreed. “Or to put it another way, in theory the exact same congestion event which would create this TCP window problem is the one which would initiate PAUSE frames. This ‘perfect storm’ of problems could — theoretically at least — happen any time there is congestion, especially in large sprawling iSCSI networks.”
“Like the ones that often exist today,” he mused. “This reminds me of the ‘buffer bloat’ problem with TCP.”
I wasn’t as familiar with this, and it must have shown on my face. “When congestion occurs,” he continued, “TCP traffic can get stashed in buffers for so long that the sender assumes the recipient never got it, and retransmits.”
“Ah,” I said. “And once again, there goes your efficiency.”
“Right,” he said. “But buffer bloat is generally found in the scenario of slow WAN links and a bazillion hops, with wait times as high as thousands of milliseconds. You’re talking about what sounds like a relatively brief moment of congestion.”
“From the TCP side, sure,” I said. “But when we’re using PAUSE we’re talking about a fixed timer. And remember, we’re talking about flow controlling in a somewhat cascaded fashion, where all of these hosts-target sessions are being PAUSED simultaneously. Will the congestion and resulting PAUSE be quick enough – for all the nodes that have been PAUSEd and then unPAUSEd – that TCP is not disrupted?”
“So,” he said thoughtfully, “the question is whether the extended congestion lasts long enough to cause TCP to react in an oversubscribed scenario.”
I nodded.
To Use or Not to Use Lossless iSCSI
“So you shouldn’t use iSCSI in a lossless environment?” Peter asked.
I shook my head. “No, I’m not saying that,” I said. “Obviously, the technology works. But what I think you have to understand is that the key design principle here is lossless, not the iSCSI part.”
I took a sip of my drink, which gave me a second to gather my thoughts. “Look, I would hope that it’s a really rare event. But generally in lossless environments we historically actively avoid those events, rather than hope it doesn’t happen.
“It seems to me that what people want is the convenience of setting up iSCSI but the better performance they have seen with lossless environments like FC or FCoE. That’s fine, but I think that they are forgetting the reason why they liked iSCSI in the first place.
“It doesn’t matter what protocol you decide to use – you still need to do the math for lossless environments, and you still need to be pre-deterministic with the traffic. You can’t have dozens of switches between your hosts and your targets, especially if you’ve got fan-in ratios in the triple digits.”

I shrugged again. “Lossless iSCSI works – with the appropriate caveats. A single-switch scenario? Sure! Go for it!” I held my hands up in a conceding gesture. “You’re likely to be well under the subscription ratios in that type of environment. Of course, it means a little extra configuration on the switch, but that’s no big deal if you want to squeeze every nanosecond you can out of your latency.
“But I haven’t seen anyone really push lossless iSCSI environments to the same scale that we do in traditional deployments. For me, it’s just conjecture at this point. I’ve seen testing with one switch, or two switches, but not the extended sprawl that we have come to see in typical situations.”
“But at least I know it’s not required,” Peter said, grinning. “So, iSCSI shops need to think about what they are really trying to achieve with their specific topology by implementing DCB elements to enforce lossless Ethernet.”
“Yes, absolutely,” I agreed.
“Fantastic,” he said. “I really appreciate this. I really owe you one.”
You owe me a lunch! “No problem, glad to help out.”
He indicated the napkins strewn about the table, and I motioned for him to take them. In retrospect, it’s a shame I didn’t keep them myself. They would have made for a great visual in a blog article.
[Author’s note: Special thanks to Ethan Banks and Andy Sholomon for their extremely valuable insights and thought-provoking comments/questions.]






Interesting details – thanks!
Next time I will be careful when some one sets me up with a simple query: “ask a quick question.”
J,
I want to thank you for opening this great discussion. As a vendor of iSCSI storage solutions, obviously I – and Dell – has a vested interest in this topic 🙂
That being said, I would ask your to clarify your position that iSCSI is a “converged solution” by definition. Simply because it leverages a common standard transport protocol, does not automatically mean that it should be converged with non-storage traffic.
Simply by deciding to use iSCSI (as opposed to FC or FCoE)does not mean I should abandon very valid and necessary storage design best practices. I would still want to be in control of the network design including Fan-in, and flow control. All of the same design point we have all learned from FC design apply for any Enterprise class storage solution regardless of protocol.
I agree that haphazardly plugging an iSCSI storage array into an existing network, without any idea of how that network was designed would be risky at best and disasterous at worst.
With a well designed, dedicated network, iSCSI is an very capable and comparable storage technology to FC…especially at 10Gb
We believe that “converged networks” = “data center bridged” networks. We would not recommend trying to merge storage and non-storage traffic in any situation without the level of QoS control that DCB can provide. The ability to actively manage iSCSI via ETS and PFC is just as important to iSCSI as it is for FCoE.
Again, thanks for the discussion. I would encourage you to review our whitepaper on iSCSI over DCB here: http://en.community.dell.com/techcenter/storage/w/wiki/4355.configuring-dcb-with-equallogic-sans.aspx
Thanks again!
Tony Ansley
Hi Tony, thanks for taking the time to reply. 🙂
Also, thanks for confirming much of what I wrote. Obviously, I agree with the first five paragraphs of your reply. 🙂 To the rest, let me try to answer your questions in turn.
Converged Networks typically means that you are taking storage and LAN and running it on the same transport mechanism, as opposed to separate networks (such as native FC and Ethernet LAN). NAS, iSCSI, SMB, etc. allow customers to have different types of traffic running over Ethernet, but it’s the block-storage that originally took its own switches or links that now can be run simultaneously over the same ones.
I think the question must be raised – which part of DCB? As I mention above, there are multiple documents in DCB and not all of them are required for any given solution. You do not need, for instance, to run the DCB version of DCBX (CEE version works just fine, considering it’s what every vendor uses right now). QCN is not a requirement. Technically non-ETS QoS would work equally fine for sharing iSCSI traffic as well as anything else on the same link.
Saying that Converged Networks “equal” DCB is like saying that Streets = Transportation. Yes, there is an intersection there, but as described above, you can use elements of one without requiring everything else that could possibly fall under that category (streets don’t need to accommodate trains, Airbus 380s, etc.). As you point out, iSCSI works just fine and dandy on higher bandwidth networks without the need for interference at Layer 2 (which is where PFC lives).
IIRC, ETS doesn’t define the mechanism by which bandwidth groups are defined or allocated. It just so happens that the way vendors do this is through QoS.
Why? The logical corollary is that iSCSI doesn’t work without PFC. PFC is 100% completely independent of ETS/QoS. They have absolutely nothing to do with each other. So, if we were not using ETS/QoS on a link (that is, only had iSCSI traffic), why would you “need” to have PFC? As it turns out, the millions of iSCSI ports that are available on the market do not use PFC, and since there is no difference (from a L3/L4 perspective) between 1GbE, 10GbE, 40GbE or 100GbE, why does iSCSI suddenly have to change it’s behavior when the L1 parameters are changed? Isn’t that the whole purpose of a layered system?
Moreover, FCoE has a explicit requirement for lossless behavior. It’s written into the standard spec (FC-BB-5). Not so for iSCSI. And since we’re talking about the use of standards (i.e., DCB), those specifics can make a huge difference.
Thanks for the link to the white paper. I look forward to reading it. 🙂
Best,
J
Hey Tony,
I’ve been thinking more about this since I replied (see the earlier reply) and the more I think about it the more I’m convinced that “Converged Networking” can not equal “data center bridging.”
Right now you can put iSCSI (traditional, non-lossless) in one VLAN and ethernet traffic in another VLAN on the same 10G link. You do not need PFC, ETS, DCBX, or QCN to do this. The traffic will work just fine. Functionally the networks are converged exactly the same way because you are still running both traffic types over the same link.
It seems to me that if you want to improve performance, you could guarantee the minimum bandwidth through the QoS mechanisms of ETS. But, this does not inherently change the nature of the network. It does not make it “more converged” just because you have guaranteed more (or less) bandwidth. Similarly, it doesn’t make it “more converged” if you use DCBX or manually configure the devices yourself. It also doesn’t make it “more converged” whether the traffic on that VLAN is lossy or lossless. It is what it is – a VLAN running on a link that is also running other VLANs.
As a result, I think this is precisely the type of confusion that I was trying to address in my first paragraph of the blog. Thanks for helping me think through my explanation a little better. 🙂
J, Thanks for the response
A few follow ups:
“Right now you can put iSCSI (traditional, non-lossless) in one VLAN and ethernet traffic in another VLAN on the same 10G link. You do not need PFC, ETS, DCBX, or QCN to do this. The traffic will work just fine.”
I think the confusion is in the idea that because you CAN converged traffic does not necessarily mean you SHOULD. I would argue VLANs do nothing to ensure QoS…they only isolate traffic logically. You still have to contend with non-storage traffic for fixed, limited switch resources. Without having a mechanisme such as ETS to control bandwidth and PFC to ensure that the other traffic streams are not the cause of a blocked path, there is no way to guarantee the QoS of the iSCSI stream.
“Moreover, FCoE has a explicit requirement for lossless behavior. It’s written into the standard spec (FC-BB-5). Not so for iSCSI.”
I would contend that all storage traffic should be lossless. Without PFC (or even 802.3x flow control), relying on TCP – and its longer timeouts – to provide “guaranteed delivery” via TCP Retransmits, is a performance killer.
“ETS doesn’t define the mechanism by which bandwidth groups are defined or allocated. It just so happens that the way vendors do this is through QoS. ”
True…but the ETS standard does set certain behavioral expectations to support inter-device copperation and via DCBx the consistent application of ETS settings.
“PFC is 100% completely independent of ETS/QoS”
Not always true. As you state in the previous quote above, the mechanism to manage ETS and ensure that buffers don’t become saturated does involve PFC. ETS directly affects buffer utilization. Many switch vendors use PFC to throttle their upstream senders to ensure that the switch can internally honor the ETS limitations.
Bottom line, is that iSCSI can receive all of the same benefits from ETS, PFC, QCN, and DCBx (assuming the iscsi devices support these standards) as FCoE or RDMAoE. You are correct that iSCSI does not technically require any of these to operate, but the advantages of these standards when attempting to share the network with non-iSCSI traffic is real.
Keep up the great work! I totally enjoy your posts…very informative and thought provoking.
Hey Tony, more great stuff here.
A favorite refrain of mine. 🙂
Yes, precisely. But it works, and in some cases it works well (depending on the level of traffic you’re talking about). Remember it’s only when the aggregate bandwidth is above 10G that there is contention for resources. If you never push that much bandwidth guaranteeing a minimum is a pointless exercise. Host links are undersubscribed as it is (hence the reason why converging them often makes sense).
I’m going to conflate two things that you wrote into the same quote for simplicity sake:
I’m sorry, but that’s simply not the way that PFC works. Priority Flow Control has absolutely nothing to do with managing buffers. The word “priority” in this sense is not the same thing as “priority” in a QoS sense. QoS manages the priority (i.e., the “importance”) of traffic in a variety of possibilities. PFC determines whether or not to institute PAUSE on a priority (i.e., an 802.1Qp “lane”). It is a sad fact that the same word is used to indicate two completely different things, but there you go. 🙁
The relationship with PFC and buffers can best be understood as a “read-only” mechanism. That is, when a “high water mark” is reached as the buffers fill, PFC is initiated to send a PAUSE to the sending device in enough time to prevent dropped frames while still allowing for the frames in flight to be delivered. This happens on dedicated lossless links (e.g., the FCoE line card on the MDS is FCoE-only, which uses PFC but has no need for QoS because there is only one traffic type).
Personally, I can’t speak with any confidence about the way other vendors implement PFC and ETS, though. The two standards documents are completely independent of one another, and I don’t know for sure if/that anyone else creates such dependencies. It seems to me that if that is the case, though, then they are using the two technologies in a way that wasn’t intended by the standards working group. If they had been designed to be co-related they would have been part of the same document, like ETS and DCBX (as you point out).
Really? All storage? SMB, NFS and CIFS too? It seems to me that this would be treating all storage as equal, when it really isn’t. I’m curious as to whether or not you loathed iSCSI until PFC came around. 🙂
If that’s the case, why use TCP at all? After all, TCP was designed because IP had no such guarantee. If you’re looking at lossless behavior in your storage why bother with additional upper layer protocols that can increase latency?
You’ll note in my conclusion of the post that I agree with you here. Key word here is “can.” There are distinct advantages to each of these technologies, and there is a fit for them in certain implications. Certain, but not all. Some of those advantages include cost, ease of use, performance, skill sets, tool kits, etc. Ultimately if customers create iSCSI environments without considering the unintended consequences (especially at massive scale), they can wind up worse off.
More to the point, though, knowing what is required and knowing what is recommended are two completely different issues. Showing my bias a little here, it does customers a disservice to equate the two. Sort of like going to a mechanic and he tells you that an engine replacement is “required” just because you’d get better performance. 🙂
One of the advantages of having access to the post admin tools. 🙂
Thanks again!
By the way, sorry my quotes don’t look as good as yours 😀
My question is how is it performing in the real world. We can debate this academically but more to the point is: Are people doing non DCB iSCSI in med-large environments? What kind of performance are they getting? Are people doing iSCSI with DCB in a converged network, what kind of performance are they getting?