
In this blog series, we’ve discussed many unique advantages of the Cisco MDS 9000 series switches. We explored NVMe/FC support, proven investment protection, the superior security provided by anti-counterfeit technology, and the industry’s unique SAN Analytics solution. Now, let’s look at another important aspect: the Cisco MDS 9000 Series switch architecture and what makes it unique.
Switching Architectures Explained
As most of us know, there are two different types of switching architectures: Store-and-Forward and Cut-Through. In Store-and-Forward architecture, an interface receives the full-frame (header information + data + CRC + checksum, etc.) before putting it back on the wire for egress. While in Cut-Through architecture, the switch will only wait till it receives the destination WWN to put it on the wire, without waiting for other portions of the frame (data + CRC + other control parameters) to be delivered.
In both mechanisms, a CRC error check, also called Cyclic Redundancy Check, is applied. But the difference is in the next stage – action. What actions are taken when the CRC error is identified?
CRC Error Handling in Cut-Through Architecture: Identify, Report, Forward (Ugh!)
In Cut-through Technology, if a packet has a CRC error, it will increase the CRC error reporting counter and put the corrupt packet back on the wire, and move on. Thus, the switch can only report the error and put it back on the wire without taking any further action. The packet that arose with the CRC error will have to be sent again anyway from the source across the entire path. The result? Degraded performance—twice. The first is due to a bad packet, and the second is a result of resending the original bad packet.
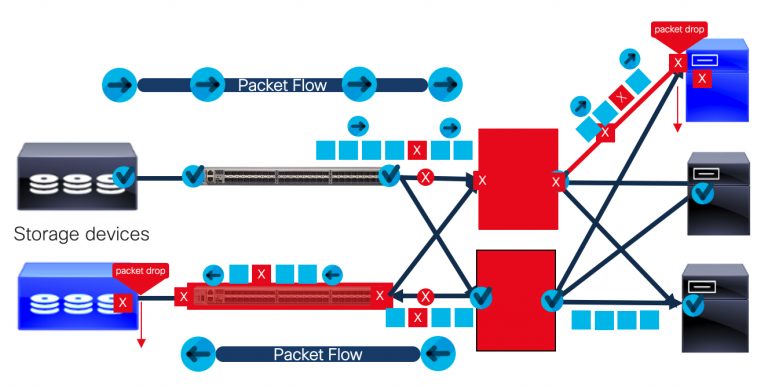
Cut-Through technology: Corrupt packets reported and forwarded.
Ultimately, the destination server and storage Host Bus Adapter (HBA) works extra hard to detect and drop the bad packet. In the ethernet world, this may not be a major issue. But in the Fibre Channel network, we have finite pools of buffer credits. Every packet that has to be retransmitted will need buffer credits. This can create performance issues, buffer credit starvation, and spend vital CPU cycles of the switches across the network. The impact includes high TCAM usage, increased latency, and a multitude of additional issues. In other words, the whole network can be impacted and brought to a halt.
CRC Error Handling in Store-and-Forward Architecture: Identify, Report, Drop (Yay!)
In Store-and-Forward technology, if the switch interface finds any CRC errors, it will identify and drop the packet on the spot. Why? Because here, the switch receives the full-frame (header + data + CRC checksum information, etc.) before putting it on the wire for egress. It will also signal the source to resend the corrupt packet. This saves resources, including memory, CPU, bandwidth, and buffer credit across the network, plus the additional resource consumption on the server or storage devices. As a result, the performance impact is minimal.
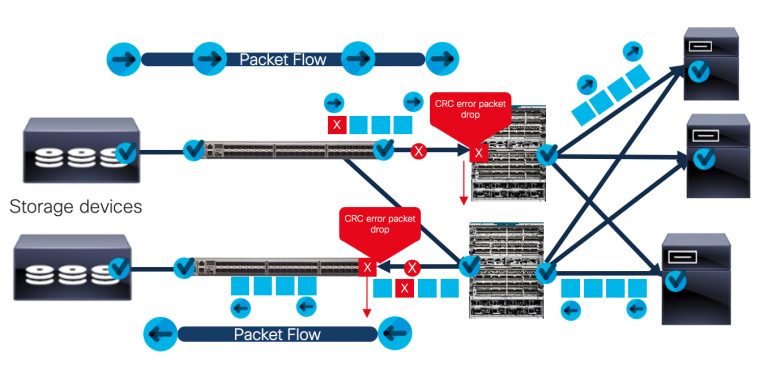
Store-and-Forward technology: Corrupt packets reported and dropped.
We implemented Forward Error Correction (FEC) in MDS 32G FC as a standard requirement. It can do a similar job, but with some limitation. FEC can only correct up to 11 bits out of 2,112 bits of FC frame. This is useful but in extremely limited cases. Note that the smallest portion of the FC frame (start-of-frame OR end-of-frame) is 4 bytes or 32 bits. So, what if errors are more than 11 bits or about 0.6 percent? FEC will not be able to help. Therefore, CRC error checking and deploying the correct architecture is highly important.
Conclusions
As Mr. Tweedy said in one of the all-time favorite movies, Chicken Run, “It’s all in your head Mr. Tweedy, it’s all in your head.” For us – it’s all in the architecture. We not only protect your data, but we also deliver it error-free.
See you soon in our next blog to discuss additional internal architecture advantages of the Cisco MDS 9000 series switches.
Additional resources:
Cisco MDS 32G Fibre Channel Fabric switches: Small doesn’t mean less.
Cisco MDS 9000 series switches: Security is better when it is built in, not bolted on.
Spinning up an NVMe over Fibre Channel Strategy using Cisco MDS 9000 Series Multilayer Switches






Cisco MDS Rocks … Thanks for the amazing Article Bhavin