
This blog series focuses on various aspects of Cisco HyperFlex. In today’s blog we will have a look at two distinctly different disaster recovery solutions and why it’s important to understand the use cases underpinning each solution. I will talk about the business challenges we are trying to solve, and which solution is the best fit.
A brief history of HyperFlex Disaster Recovery
HyperFlex was originally released without native replication — therefore native DR — functionality. A short time later, in 2017 HyperFlex Data Platform (HXDP) version 2.5 introduced support for asynchronous replication of VM snapshots. The native replication topology consists of a 1:1 configuration with two paired HyperFlex clusters. The paired clusters can be geographically separated and utilize WAN connectivity. Workflow support for VM failover & re-protect, planned migration, and test-recovery make it a good fit for users looking for a single-cluster disaster recovery solution, or an active-active solution with each cluster able to act as a recovery cluster for the other. If you are thinking this sounds a bit like a built-in feature with SRM-like capabilities, you’re correct!
The biggest limitation of that offering is that it is not geared towards protecting more than two clusters. Each additional protected cluster requires a “companion” cluster to create a cluster pair. While possible, scaling the 1:1 replication solution comes with some additional costs.
Use cases for the 1:1 replication solution include:
- Recovery – Protected VMs can be recovered on the paired destination cluster in the event of a source cluster outage. The user can re-protect the recovered VMs at the point when the original source cluster outage has been resolved.
- Migration – Protected VMs can undergo planned migration, where a new snapshot is taken and replicated to the paired cluster. The replication direction is automatically reversed at the point when migration has completed.
- Testing – Protected VMs can be test-recovered without impacting production workloads. This makes the testing of recovery procedures possible at whatever frequency is required.
The 1:1 recovery solution is managed using the HX Connect user interface. Access to HX Connect on each of the paired clusters is necessary when deploying the solution.
Enter: Many-to-One Disaster Recovery
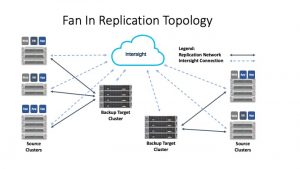 Fast forward to 2021, when new replication technology was introduced with HXDP version 4.5(2a) then called N:1 Replication for Edge. HyperFlex now supported a fan-in replication topology, and that the solution was managed with a cloud-based control plane named Intersight. The Intersight user interface lets users manage large numbers of HyperFlex clusters from a single console with no need to login to multiple different user interfaces.
Fast forward to 2021, when new replication technology was introduced with HXDP version 4.5(2a) then called N:1 Replication for Edge. HyperFlex now supported a fan-in replication topology, and that the solution was managed with a cloud-based control plane named Intersight. The Intersight user interface lets users manage large numbers of HyperFlex clusters from a single console with no need to login to multiple different user interfaces.
N:1 disaster recovery addresses the scalability limitations of the 1:1 solution, however there is other less obvious functionality that stands out. Here’s a quick list of just some:
- Protected Datastore – Any VMs residing in the protected datastore are automatically protected using a common backup policy. Users do not need to apply backup settings to VMs individually, simplifying the administration of the solution.
- Retaining multiple recovery points – On both the originating source cluster as well as on the destination backup target cluster users can select to retain from 1 to 30 snapshot-based recovery points. This allows the user to recover VMs from a point in time before a logical corruption or accidental deletion event may have occurred.
- Recovery of VMs – Either to the original source cluster, or to a different source cluster.
- Recovering a VM on the originating source cluster leverages a locally retained snapshot-based recovery point. Recovery operations are very fast as there is no data transfer involved.
- VMs can optionally be recovered onto a different cluster. When performing this recovery operation, the selected snapshot-based recovery point is replicated in compressed format to the desired cluster. This makes it possible to recover VMs on a different cluster in situations where the original source cluster may be unavailable. Another use case is ad-hoc migration of VMs from one source cluster to a different source cluster.
Not just for the edge anymore
When HXDP version 5.0(1a) became available in early 2022, N:1 recovery for Edge solution morphed into the Many-to-One (N:1) Disaster Recovery for HyperFlex solution. This became possible when support for FI (Fabric Interconnect) based source clusters was added. What was initially a protection solution for remote HyperFlex Edge clusters became an enhanced solution for all HyperFlex clusters. Another significant enhancement added at that time was the ability to retain different numbers of snapshot-based recovery points on source and backup target clusters. Users can now opt to retain fewer local recovery points on a source cluster and retain a greater number of recovery points on a backup target cluster. Fewer recovery points on a source cluster provides an ability to consume less storage space when fewer local recovery points are required.
HXDP version 5.0(1b) added support for software encryption so that the protected datastore on a source cluster can optionally be encrypted. And yes, the replica datastore on the backup target datastore (created automatically) will also be encrypted!
It’s important to note that while both the 1-to1 and many-to-one replication solution are supported, they cannot be co-mingled on the same HyperFlex cluster. Worth noting is the continuing effort and hard work that takes place behind the scenes to improve and enhance HyperFlex replication. Can we expect ongoing improvements in future releases? That’s a pretty safe bet!
Hopefully this has provided a view into the two different HyperFlex replication solutions. For additional information, see our resources section below.



