
Late last year, I compared Cisco’s S3260 Storage Server to Amazon’s S3 service. The results shocked a lot of people and spurred a lot comments on the blog.
It’s worth repeating from the last conversation on this topic that there is a long list of pros and cons between the on-prem and public cloud approach that will influence your decision. Depending on your individual situation there are factors that will favor one option over the other. Here we’re just trying to get a clear-eyed view of basic cost elements.
If you are considering replacing, upgrading, or buying a new computing solution, you’ve probably come across hyperconverged infrastructure as well as public cloud offerings and are wondering which to choose. HyperFlex Systems (HX-Series) is Cisco’s hyperconverged infrastructure platform.
I wanted to find out what a large, highly virtualized server environment would cost with either HyperFlex or Amazon’s EC2 service over three years. HyperFlex can save you 50% or more. Now that I have your attention, keep reading!
Configuring the Public Cloud
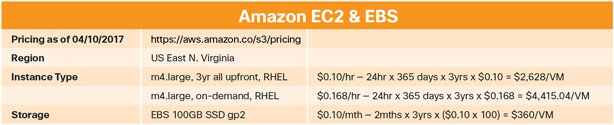
Amazon offers 57 different instance types. After a discussion with some system architects and consulting system engineers, the m4.large instance type was chosen as a good general purpose VM for us to base this comparison on. Amazon describes it as “a high level of consistent processing performance on a low-cost platform.” It has 2 vCPUs and 8GiB of RAM. There is also different networking performance for each instance type which will not factor into the comparison here, but you should factor into your choice.
For each EC2 instance, we need to add EBS storage which can be SDD (gp2 or io1) or HDD (st1). We’ll keep our storage requirement modest at 100GB gp2 (general purpose) per VM.
Configuring HyperFlex
 When sizing the number of VMs that can be placed on a HX node, there are three sizing items to consider: CPU, memory, and disk space. You also have to take into account the overhead for the virtualization (VMware vSphere) and HyperFlex Data Platform software. You should also consider storage performance. The cluster I will describe below is capable of 100 IOPS per VM but I don’t include the cost of provisioned IOPS on the AWS side.
When sizing the number of VMs that can be placed on a HX node, there are three sizing items to consider: CPU, memory, and disk space. You also have to take into account the overhead for the virtualization (VMware vSphere) and HyperFlex Data Platform software. You should also consider storage performance. The cluster I will describe below is capable of 100 IOPS per VM but I don’t include the cost of provisioned IOPS on the AWS side.
Using the Intel® Xeon® E5-2650 v4 CPU and 24x 32GB DIMMs, I have 171 vCPUs and 696GiB of memory available per node after accounting for the overhead. After adding in the memory overhead for the VM itself, a node would support 85 VMs maxing out the memory and CPU resources. This is without over provisioning of the memory or CPU.
For HX storage, I’m using the HX240c M4 All Flash Node which have 10x 3.8TB SSD drives. For resiliency, I set the replication factor to three, which allows for two simultaneous node failures in the cluster of eight nodes. Eight nodes will provide ~85.68TiB of usable space. For the purposes of this blog, I’m assuming no capacity benefits from compression or deduplication, even though customers are seeing an average of 48% increase in effective vs. usable capacity.
 HyperFlex, unlike other hyperconverged platforms, has the unique ability to flexibly scale compute and capacity independently. This ability allows you to better match your resource needs with the right server type. My eight HC240c M4 All Flash Nodes support 680 VMs before exhausting their memory and CPU. Since I’m memory/CPU constrained in this example, I added two B200 M4 Blade Servers. This will balance out the compute and storage resources. On my 10 node mixed HyperFlex cluster, I can support 850 VMs with 2 vCPUs, 8GiB RAM, and 100GB of storage.
HyperFlex, unlike other hyperconverged platforms, has the unique ability to flexibly scale compute and capacity independently. This ability allows you to better match your resource needs with the right server type. My eight HC240c M4 All Flash Nodes support 680 VMs before exhausting their memory and CPU. Since I’m memory/CPU constrained in this example, I added two B200 M4 Blade Servers. This will balance out the compute and storage resources. On my 10 node mixed HyperFlex cluster, I can support 850 VMs with 2 vCPUs, 8GiB RAM, and 100GB of storage.
The Results
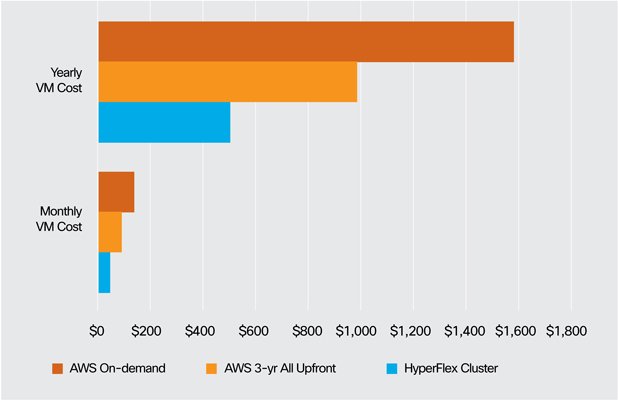 So what is a VM with two vCPUs, 8GiB RAM, and 100GB storage going to cost me per month? $40 for HyperFlex, $83 for Amazon paid upfront, or $133 on-demand. Amazon has different pricing models: on-demand, one and three year commitments with partial or all upfront payments.1 The most expensive of these is on-demand, but it offers the most flexibility. The least expensive is three year commitment, paid all upfront. Let’s not forget data transfer out to the internet charges. I have omitted them in the spirit of a fair compare. Without them, this comparison probably understates the public cloud costs, perhaps dramatically for some application scenarios. For example, if you were to transfer as little as 1TB per month, per VM, you could add $2,817,342 to your total bill.
So what is a VM with two vCPUs, 8GiB RAM, and 100GB storage going to cost me per month? $40 for HyperFlex, $83 for Amazon paid upfront, or $133 on-demand. Amazon has different pricing models: on-demand, one and three year commitments with partial or all upfront payments.1 The most expensive of these is on-demand, but it offers the most flexibility. The least expensive is three year commitment, paid all upfront. Let’s not forget data transfer out to the internet charges. I have omitted them in the spirit of a fair compare. Without them, this comparison probably understates the public cloud costs, perhaps dramatically for some application scenarios. For example, if you were to transfer as little as 1TB per month, per VM, you could add $2,817,342 to your total bill.
When in doubt, I factored things conservatively in favor of public cloud. For example, I used VMware vSphere 6 Enterprise Plus instead of the less expensive Standard edition, which also impacts the support cost. I applied IT labor costs to the on-prem side of the equation for deployment and on-going management of the physical servers. I included the cost of Fabric Interconnects, but if you are already a UCS customers, you can add HyperFlex to your existing Fabric Interconnects. Lastly, if you already have a data center, would the addition of a HyperFlex cluster really increase your overhead to go up significantly beyond the incremental power and cooling?
So turning the crank with all of those assumptions, what is the result? Over three years, HyperFlex will save you 51% – 70% over AWS when running 850 VMs with two vCPUs, 8GiB RAM, and 100GB storage.
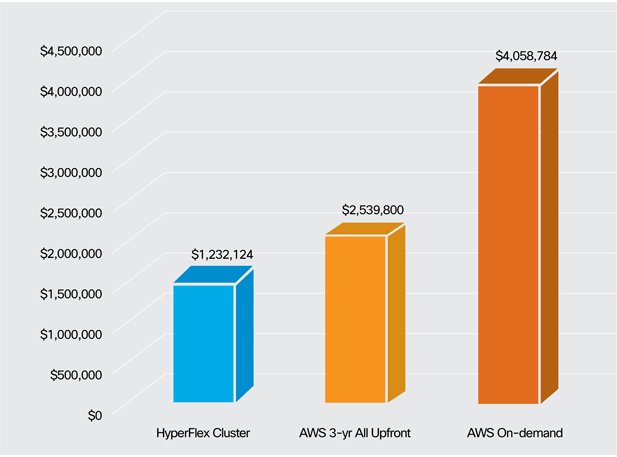
I’ve broken down the cost assumptions below so you can check to make sure I’m not cherry picking the cost elements. While the percentage of savings (and number of VMs per HX cluster) will differ, using three year all upfront pricing, the: t2.small, t2.medium, t2.large, m3.medium, m3.large, m3.xlarge, m3.2xlarge, m4.xlarge, m4.2xlarge, m4.4xlarge, m4.10xlarge, and m4.16xlarge will all cost more than our example HyperFlex cluster.

Final Thoughts
It was correctly pointed out in the responses to my S3260 blog that public cloud provides levels of immediacy and multi-site resiliency (if you pay for it) that are difficult to replicate on-prem. On the flip side, some customers can’t put certain data types in the cloud, or might have application latency requirements that the cloud can’t provide. How these factors translate into cost will clearly vary from customer to customer, depending on the applications and business models in play. In terms of resiliency, the on-prem costs modeled here cover everything short of a complete site failure (think hurricane). This cluster can tolerate a failure of two storage nodes and the loss of a Fabric Interconnect. Public cloud can buy you multi-site peace of mind with no additional hassles and that’s something that might well be worth the cost premium to you. But it’s pretty clear that you can save a bundle keeping things on prem….and if you have a ballpark understanding of your growth needs you can use a “cloud in a can” solution like HyperFlex to get very close to public cloud in terms of ease of scaling and speed to deploy.
What if you don’t have large VM environment, but a small one? HyperFlex may still be right for you. A three node cluster supporting only 255 VMs is 37% less than the equivalent AWS solution paid all upfront.
I would encourage you to reach out to your Cisco account team or partner to see if a HyperFlex solution might be a good fit for your environment.
Additional Resources
It’s not as if the blog wasn’t long enough already but I thought I would point to a few other items for your consideration.
Chalon Duncan has a great blog that address the strategy of public cloud, private cloud, or both.
Kaustubh Das’ blog on the performance benefits of the HyperFlex All Flash solution as documented by ESG and is worth a review.
Lastly, there is a great TechWiseTV episode on the HyperFlex All Flash announcement.
1 There are also spot instances and dedicated hosts. Neither were germane to this analysis. Spot pricing can fluctuate every five minutes so can’t be readily modeled. Dedicated hosts are even more expensive than on demand and reduces your flexibility.





Exactly what the doctor ordered . Very Timely . Thank you
Super nice job, Bill! Lots of solid facts to support the case for on-prem or private cloud deployments on Cisco gear!
Very usefull information when selling hyperconverged to customers.
Big thanks
One big thing to note is that reserved instances can be billed monthly thereby eliminating the need for a capital expense.
Also having all 850vms on 24hrs is a little silly in the cloud but they are reserved instances so I get it. Also what if you don’t need 850vms? Looks like the break even point is about 480VMs.
Tradeoffs.
DK, thanks for joining the conversation. If you used Cisco Capital, you can be billed monthly for your HyperFlex cluster (or any Cisco products) and change this from CapEx to OpEx.
With public could, there is no fixed starting point – one of its benefits. For HyperFlex, you will always have some amount of capacity as a starting point. But you can start small with HX220c M4 nodes and grow the cluster as your needs increase.
You’re correct, everything is about trade offs.
This is a timely conversation. I am currently drafting a blog to be published later today on new storage subscription pricing program Cisco is offering on the S-Series. Get a big box delivered for free and only pay for what you store. Keep an eye out for my blog on the Cisco Data Center channel.
Nice blog. For better clarity I would like to see the $ amount shown as a number on top of the pillars on the price comparison diagram. The way it is now, I need to guess and it is not so immediate for me.
Fausto, I’ve updated the chart.
Thanks for the feedback.
You’re not having one salaried person manage that. Beyond that, what about the cost of the data center you do not have to pay for? No racks, cooling, sensors for doors, etc…
The cost comparison is severely short sided if you only compare the raw cost of a set of blades, without any licenses either, and compare that to a cloud service.
Jeff, thanks for joining the conversation. The admin cost for the physical servers, not the virtual servers. One could argue that the cost of managing the virtual servers would be the same on both sides. As to the racks, cooling, etc., cooling is contained in the cost of power via the PUE. For the rest, yes those would be incremental cost ($2K for a rack?). I think I have enough wiggle room to cover all of them and still come out ahead. There isn’t enough savings to build a data center, but if you are on-premises, you already have one of those :-). I do have all the software licenses (and support) included for both the blades and rack servers – HX, VMware, and Red Hat for the OS. Am I missing something else?
Good article, but key point is in Final Thoughts section, both co-exists, we can not ignore now the quick innovation without cloud. Multi-regional integration has become a great challenge for on-prem and it’s management as well. On-prem restricts too many parameter in that sense. This is my experience working with as many Life Science / Health Care domain.
Thanks