
It is no news, and confirmed by recent surveys, that people working in Information Technology (IT) sector need to operate within a more complex environment than it used to be years ago. The ongoing digital transformation combined with the need to leverage IT as a competitive differentiator, rather than a necessary evil, is driving the shift to a more complex landscape. Data volumes keep growing, budgets are not. The workforce is highly mobile and distributed, applications live within hybrid-clouds, the edge of networks is now hosting data and cybersecurity is clearly a top priority. IT complexity translates into costly operational expenses and the only valid barrier remains to implement a solid Day2 operational model. Storage networks make no exception and the attention to select products and solutions with the right mix of auto-governance and ease of operation is on the rise.
Self-driving cars
In the last few years, we all lived the hype of self-driving cars. As a guy still using a manual transmission, I’m not sure I would call it a dream. The promise is quite big and expected to have a huge impact on our lifestyle and many businesses, including logistics and taxi service. Three important concepts emerged from all the discussions on the topic:
- Declarative intent-based model
- Spare time to reinvest
- Faster reaction time
With a self-driving car, the driver becomes a passenger. Ideally you would enter your car, declare where you want to go (your intent), set route preferences (shortest, fastest, panoramic, the one we used yesterday, etc) and let it do its job. There is no detail about when to use the throttle or the brake, when to turn right or left. You just declare where you want to go and how, then let the car execute based on accurate maps, a multitude of sensors and its own artificial intelligence.
Of course, if the car is driving on its own (and we fully trust it), the person onboard is freed up by driving duties and could make phone calls, read a newspaper or take pictures of the landscape. In short, that person would have more time to reinvest in alternative activities.
An additional expected benefit (still to be proved) would be a reduction of car accidents. The artificial intelligence operating the car would never fall asleep and would be able to react quicker than human brain, avoiding or at least reducing chances of crashes.
Please note I’m making reference to a real autonomous vehicle. Autonomous control implies satisfactory performance despite significant uncertainties in the environment, coupled with the ability to compensate for system failures without external intervention. This is more than just an automated behavior, where the environment would be constrained and more deterministic, like seen with some underground train systems.
From cars to storage networks
Why this introduction? Because there is somewhat of a parallel with the latest generation of MDS 9000 storage networking switches. In a way, I can see how those three concepts above have relevance for storage networks as well. In this case, no hype though: capabilities are already available and solid. Please accept a bit of oversimplification in the way I describe things.
The network administrator makes a declaration of intent with the zone configuration. He says: “I want this device to talk to this other device and vice versa”. When done, he wants the switches to establish and sustain the requested communication in an optimal way. Of course, multiple communications would be happening simultaneously and situations of congestion or misbehavior could not be excluded. Ideally, the administrator should not be involved because the switches would have the capability to detect anomalous events in real time and react to them in the best and fastest possible way. This would give the administrator more time for planning and integration activities, freeing him up from day by day operations to keep the network healthy and performant.
Detect-react capabilities
But what capabilities in the MDS 9000 series would be considered to fit a detect-react style where human intervention is not required? By looking at what was already implemented and what got added with the latest version of NX-OS 8.5(1) software, I have distilled a list of features that I feel would meet the criteria. In that list, undoubtedly not exhaustive, you may recognize some popular and widely adopted capabilities of Cisco MDS 9000 switches:
- Autozone enables standalone fabric switches to create zone entries on their own, without manual intervention.
- I/O flow self-learning, baselining and anomaly detection are part of SAN Analytics and Datacenter Network Manager SAN Insights solution, a powerful unique approach for deep traffic inspection, fast troubleshooting and performance analyses
- Duplicate PWWN reject in the fabric prevents weird situations from becoming critical issues
- Port Monitor and Port Guard enable automatic alerting on threshold crossing and consequent port fencing upon persistent anomalous behavior
- Automatic drops of errored frames is a historical feature of Cisco MDS 9000 devices, made possible by its store and forward architecture
- NX-OS 8.1 introduces embedded authenticity checks for hardware and software and provides customers an assurance that what they received is genuine, trustworthy and not counterfeit.
- Multiple buffer credit recovery mechanisms make sure your ports will not get stuck due to the loss of some R_RDY primitives.
- Periodic hardware diagnostics determine if the many components that make up an MDS 9000 switch are all functioning without error.
- NX-OS and DCNM scheduler are a way to automatically execute some task at a regular time interval. Along the same principle, automation of specific tasks could also be achieved programmatically via NX-API, Ansible and the likes.
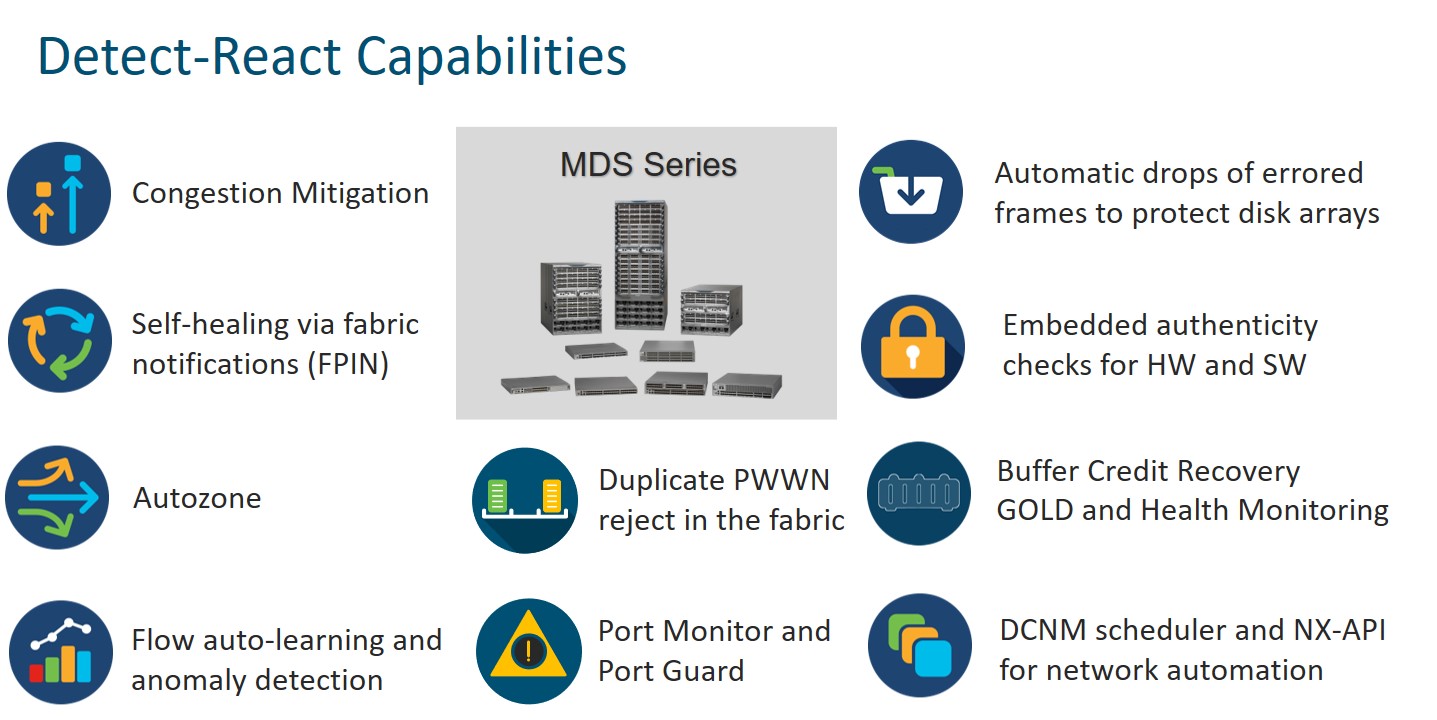
But in my list, you can also find some new entries pertaining the most recent software version:
- NX OS 8.5(1) accommodates the latest evolution in Fibre Channel standards and introduces a self-healing feature via notifications and signals to end-devices, called Fabric Performance Impact Notification (FPIN) and Congestion Signals. If you want to know more about how that works, I will just refer you to the blog of my expert colleague: Slow drain in Fibre Channel: Better solutions in sight
- SAN congestion mitigation has been in continuous development over the years, with options for both automatic detection and automatic recovery. NX OS 8.5(1) introduces a patented capability called Dynamic Ingress Rate Limiting (DIRL). It leverages the traditional static ingress rate limiting capability of MDS 9000 devices but within an innovative approach, addressing both slow drain and over-utilization challenges in small and large fabrics. I wrote some considerations on that new feature in another blog on Dynamic Ingress Rate Limiting.
The easiest storage network to manage
Day2 operations are a critical element for storage networks whose availability and service continuity is vital to companies and organizations of any kind. Getting it right is a top priority for Cisco, as testified by the focus on automation capabilities and the investments in deep traffic visibility at scale. Possibly we all agree that the easiest storage network to manage is the one that does that by itself.
The previously described detect-react capabilities are made possible by a combination of sensors integrated in the MDS 9000 switches and their smart software. There is no need for human intervention, they just happen. But those capabilities are augmenting, not replacing, the expertise and skills of a good network administrator, coupled with a simple to use yet powerful provisioning and monitoring tool, like Cisco DCNM.
The Day2 operations enhancements now available on Cisco MDS 9000 switches represent one face of Cisco’s Intent Based Networking as applied to storage networks. For situations where human intervention is still required, having a partner-integrated approach can make a difference. That’s why Cisco DCNM can integrate with ServiceNow, the IT Service Management (ITSM) and IT Operations Management (ITOM) leader that boasts many customer deployments across the globe.
ServiceNow sees the data associated to the physical infrastructure, like the list of switches managed by DCNM, port information (used vs free) and alarms. Data is loaded into ServiceNow Configuration Management Database (CMDB) every 15 minutes via DCNM standard REST API. When an alarm gets cleared on DCNM, it is also cleared on ServiceNow in the next poll cycle. The goal is to identify and resolve network problems before they turn into costly outages. Cisco DCNM and ServiceNow integration would accelerate incident response times while freeing up precious network engineering resources. ServiceNow ITSM can create tickets for each critical issue, categorize the tickets based on urgency and priority and let administrators drive the issue to resolution. The possible next step in the integration effort would be to automate incident resolution, by assigning tickets to relevant groups responsible for remediation. This would establish a complete closed-loop incident process (CLIP).
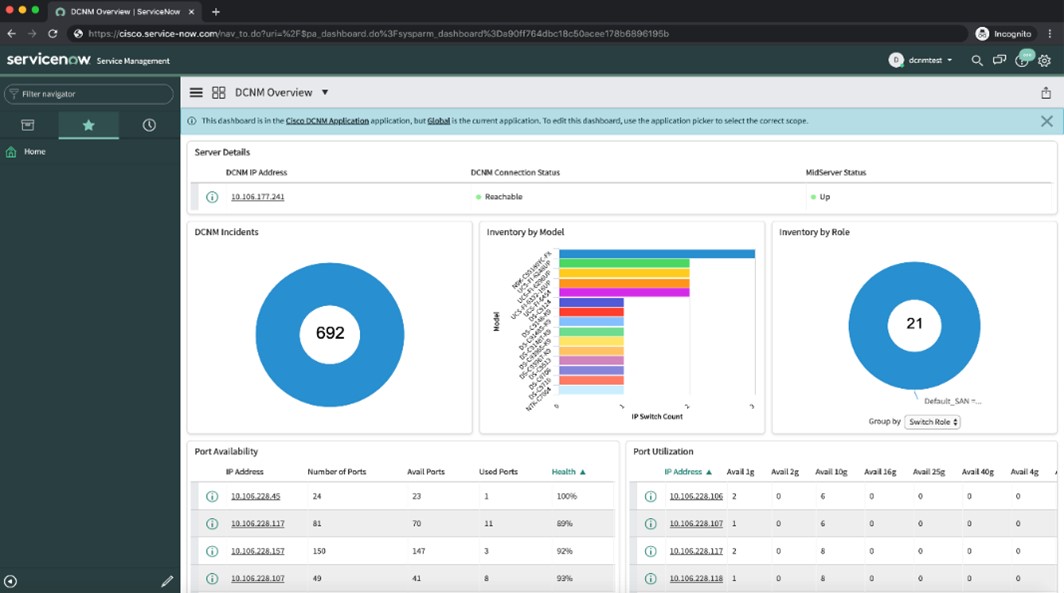
For details, refer to the Cisco DCNM with ServiceNow configuration guide
Conclusion
Detect-react capabilities within devices, an integrated solution with leading ITSM tools and skilled administrators are critical for an optimal Day2 operations approach. This will drive the health and hygiene of your storage network fabrics at their highest level. Come and join the pool of companies that are already taking benefit from this approach.




