Security intelligence, threat intelligence, cyber threat intelligence, or “intel” for short is a popular topic these days in the Infosec world. It seems everyone has a feed of “bad” IP addresses and hostnames they want to sell you, or share. This is an encouraging trend in that it indicates the security industry is attempting to work together to defend against known and upcoming threats. Many services like Team Cymru, ShadowServer, ThreatExpert, Clean MX, and Malware Domain List offer lists of known command and control servers, dangerous URIs, or lists of hosts in your ASN that have been checking-in with known malicious hosts. This is essentially outsourced or assisted incident detection. You can leverage these feeds to let you know what problems you already have on your network, and to prepare for future incidents. This can be very helpful, especially for organizations with no computer security incident response teams (CSIRT) or an under-resourced security or IT operations group.
There are also commercial feeds which range anywhere from basic notifications to full-blown managed security solution. Government agencies and industry specific organizations also provide feeds targeted towards specific actors and threats. Many security information and event management systems (SIEMs) offer built-in feed subscriptions available only to their platform. The field of threat intelligence services is an ever-growing one, offering options from open source and free, to commercial and classified. Full disclosure: Cisco is also in the threat intelligence business
However the intent of this article is not to convince you that one feed is better than another, or to help you select the right feed for your organization. There are too many factors to consider, and the primary intention of this post is to make you ask yourself, “I have a threat intelligence feed, now what?”
Incident Response
Threat intelligence can be used largely for incident prevention. Automatically blocking external sites and hosts with poor reputations will take you a long way towards securing the network. At Cisco, we block only about 1% of all outbound web transactions. However that 1% represents millions of successful connections to anything from adware to information-stealing trojans. If you are confident in the fidelity of your feed, then by all means leverage it to prevent incidents as much as possible.
Incident response involves much more than preventing threats. We’ll get into it a bit more below, but threat intelligence feeds can’t possibly detect everything. For true defense in depth, an incident response team needs to investigate the rest of the suspicious traffic traversing the network not flagged by an external intelligence feed.
The classic incident response model is some variation of:
- Preparation
- Identification
- Containment
- Eradication
- Recovery
- Lessons Learned
Threat intelligence falls squarely under “preparation” and “identification.” So now you have 30% of your incident response process covered/outsourced to someone else. What about the other 70%? Now you know that you have confirmed security problems on your network because you’ve been notified by someone else. However incident response isn’t just looking at alarms, its actually responding to alerts and tracking real incidents to closure.
The US Department of Homeland Security maintains its “National Terrorism Advisory System” (the new version of the old color-coded Homeland Security Advisory System). This system essentially attempts to inform the American populace of “imminent” or “elevated’ threats to their personal safety as a result of a terrorist threat. This is a physical security “threat intelligence” system. However what can you do as someone affected by this alert? If there’s a “credible” threat, what exactly are you supposed to do? What exactly does “elevated” or “red” mean? There’s no instructions other than basically, “stay tuned for more details.” This is an unfortunate tautology. If this were part of the security incident response process, we’d be stuck on “preparation.”
The hope, when subscribing to a threat intelligence feed, is that you will receive vetted, confirmed information about specific threats to your organization that are actionable. This means that you can take the threat intelligence data and actually use it for incident response. Threat intelligence alone is just like the National Terrorism Advisory System—you have information on credible (possibly even confirmed) threats, but no real information about what to do. It’s up to you what to do with the intelligence once you receive it. Does the data overlap with other feeds you are paying for? Do you trust their results? That is to say, have you been able to confirm with certainty what your threat feed is telling you? If you are automatically blocking hosts based on third-party intelligence, what happens if you get bad data? If you are sending your CTO’s laptop up for remediation, you’d better be confident you made the right call. Same goes if 5,000 hosts on your network are resolving a domain that was flagged as malicious. Are you prepared to put full trust into this feed, meaning that you have a mass outbreak on the network and quarantine all of them?
Run the Playbook
You can validate the output of many threat feeds using your own typical detection tools. You could also infer that for many feeds, the giant aggregation of global data improves their accuracy rate since the sample sizes are more statistically significant. Regardless of your confidence level, you still have the work of responding to the reported threats. This is where an incident response (IR) playbook comes in. The playbook is the framework and methodology for responding to security threats. A threat intelligence system feeds a playbook nicely. It will help find known threats, and provide a great deal of information about your exposure and vulnerability to those threats. You can automate threat intelligence data analysis by running queries across your security log information against reported indicators. You could:
- Take a feed of known bad C2 (command and control) domains and run an automatic report looking to see what internal hosts attempt to resolve them.
- Auto-block some senders/domains based on phishing and spam feeds (prevention), then query for any internal users afflicted by these campaigns by looking at ‘call-backs’ and other indicators (detection).
- Log and report when any internal host tries to contact a malicious URI.
- Take a specific policy-based action on a domain or URL that is flagged in a feed with with a low “reputation score” that clients have reached.
- Automatically create incident tracking and remediation cases based on feed data about your compromised internal hosts.
Feeds automate the dirty work of detecting common threats, and provide the security team with additional context that helps improve incident response decisions. Judgements about an external host can help analysts better understand a potential incident by providing some peer-reviewed bias. Ultimately the intelligence can lead to new reports in your IR playbook. However, subscribing to a variety of feeds is not a comprehensive answer to your internal security.
Threat Intelligence on Trial
Locally sourced intelligence is also highly effective, doesn’t have any of the disadvantages of a giant statistical cloud, and it can be more precise and effective for your organization. This is particularly true when responding to a targeted attack. If you have gathered evidence from a prior attack, you can leverage that information to detect additional attacks in the future. If they are targeted and unique, there may be no feed available to tell you about the threat. The other advantage to internal intelligence is that it is much more context-aware than a third-party feed. You and the rest of your IT organization—hopefully—know the function and location of your systems. With proper context (that can only be developed internally) the feed data could be extremely helpful, or worthless depending on your response process and capabilities.
The most effective attackers will also monitor external threat feeds. If their versions of exploit kits, their hosts, or any of their assets are implicated by a threat feed, its time to change tactics. Attackers can run their own malware hashes through various online detectors to see if their campaign has been exposed and detected. Now the threat feed is moot until the new attempts are analyzed.
Reputation scores, malware lists, spam lists, and others can never be fully current. They are completely reactionary as a result of gathering and analyzing events that have already happened. How many attacks have you detected where the exploit kit, the dropper, and the latter stage attacks were always hosted at the same location for weeks? Initial attacks want to hit and run. I can bring up a brand new domain and website, install my kit, then when my victims are redirected and compromised I throw the domain away once I’m satisfied with the load count. Or better yet I could leverage a dynamic DNS provider to burn through thousands of unique, one-time hostnames. Regardless of my attack methods, a reputation score or vetted evidence cannot be calculated instantly and there will always be a lag in detection and propagation time of threat information. Because your team understands internally developed intelligence so much better, you can create higher-level, broad patterns rather than just using specific lists of known-bad indicators.
To be fair to reactive threat feeds, it is called Incident Response, meaning we respond to an event after the fact. The key is to take action as fast as possible for situations where threats cannot be prevented. Beyond that, its critical to take the “Lessons Learned” from the detection and response components, and continually apply that operational knowledge towards “Preparation” for future incidents.
Needle in a Needle Stack
Threat intelligence doesn’t work well against the long tail of security event data. In this example, you can see the the top 10,000 website domains requested by Cisco employees based in Research Triangle Park, NC over seven days:
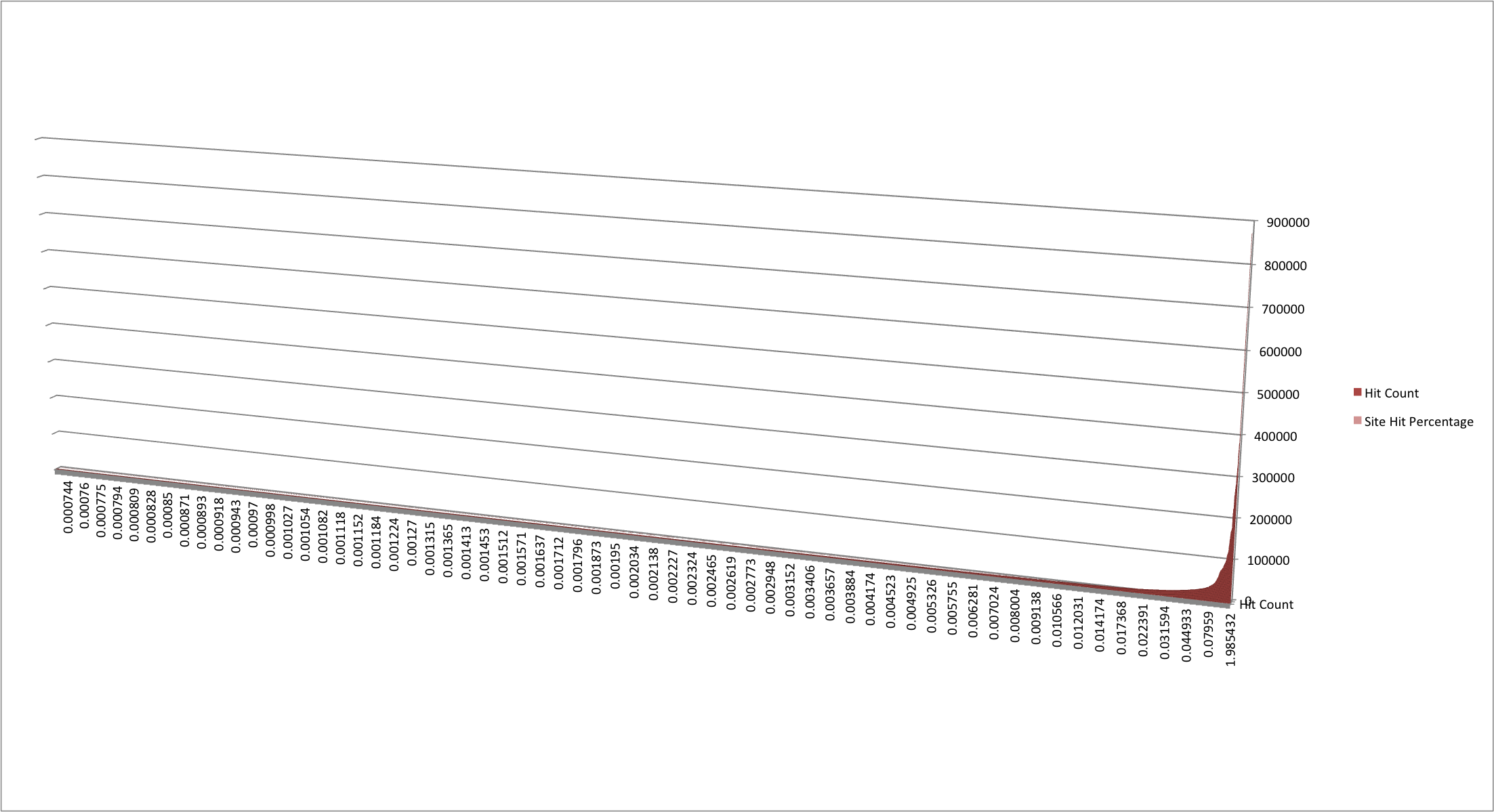
Cisco internal: HTTP long tail (click to enlarge)
Note that the spike on the right, representing 1.98% of all HTTP requests over the last week went to only one site. The rest of the requests follow behind and quickly drop off in hit count after the top 60 or so. This means there’s a huge amount of data hiding in that long tail. How many domains and sites are accounted for there, and what—if anything—do intelligence feeds know about them?
Bring Your Own Threat
Because there’s a mountain of unexamined data behind the commonly known, you must spend time mining your own logs for indicators. Looking for odd behavior is a great first step in finding incidents and researching your own threats in the mass of security event and log data. Things like:
- HTTP requests with no referrer, no mime-type, or executable/compressed mime-types (among others)
- Unusual or impossible user-agents in HTTP logs, or unexpected user-agents downloading files
- Spikes in download activity unrelated to new (legitimate) software releases
- Host IPS data indicating executables launching from user directories and temp folders (that are not typical software packages)
- Large outbound flows to unexpected locations
- TCP Three-way handshakes completed where they shouldn’t be (i.e. Internet to internal, sensitive hosts)
- Lateral attacks from newly infected hosts as reported by other host IPS alarms
- Anti-virus data indicating infected, but not “cleaned” malware installations
- Brute-force anything
“Odd” behaviors and outliers are what make up a large part of our playbook. Threat feeds free up our time detecting routine and pedestrian malware so that we can spend more time analyzing the more unique events. The reputation feeds also color our existing data with extremely helpful context that make the decision of “is this odd or not?” much easier.








Does a great job distinguishing between “threat intelligence” and “incident response”. Difficult to fix what you can’t see, but just seeing what has already happened doesn’t help us get to the promised land of true proactive protection. We here at Norse are very focused on “live” threat intelligence. Looking where most do not have visibility (dark side of the Internet) and making this information available within a few seconds. As you point out, bigger pipes, virtual environments and better tools all lead to the opportunity of fast change. If you’re not looking, you’ll miss it. Thanks for a really well written article.