System crashes. Outages. Downtime.
These words send chills down the spines of network administrators. When business apps go down, business leaders are not happy. And the cost can be significant.
Recent IDC survey data shows that enterprises experience two cloud service outages per year. IDC research conservatively puts the average cost of downtime for enterprises at $250,000/hour. Which means just four hours of downtime can cost an enterprise $1 million.
To respond to failures as quickly as possible, network administrators need a highly scalable, fault tolerant architecture that is simple to manage and troubleshoot.
What’s Required for the Always On Enterprise
Let’s examine some of the key technical capabilities required to meet the “always-on” demand that today’s businesses face. There is a need for:
- Granular change control mechanisms that facilitate flexible and localized changes, driven by availability models, so that the blast radius of a change is contained by design and intent.
- Always-on availability to help enable seamless handling and disaster recovery, with failover of infrastructure from one data center to another, or from one data center to a cloud environment.
- Operational simplicity at scale for connectivity, segmentation, and visibility from a single pane of glass, delivered in a cloud operational model, across distributed environments—including data center, edge, and cloud.
- Compliance and governance that correlate visibility and control across different domains and provide consistent end-to-end assurance.
- Policy– driven automation that improves network administrators’ agility and provides control to manage a large-scale environment through a programmable infrastructure.
Typical Network Architecture Design: The Horizontal Approach
With businesses required to be “always on” and closer to users for performance considerations, there is a need to deploy applications in a very distributed fashion. To accomplish this, network architects create distributed mechanisms across multiple data centers. These are on-premises and in the cloud, and across geographic regions, which can help to mitigate the impact of potential failures. This horizontal approach works well by delivering physical layer redundancy built on autonomous systems that rely on a do-it-yourself approach for different layers of the architecture.
However, this design inherently imposes an over-provisioning of the infrastructure, along with an inability to express intent and a lack of coordinated visibility through a single pane of glass.
Some on-premises providers also have marginal fault isolation capabilities and limited-to-no capabilities or solutions for effectively managing multiple data centers.
For example, consider what happens when one data center—or part of the data center—goes down using this horizontal design approach. It is typical to fix this kind of issue in place, increasing the time it takes for application availability, either in the form of application redundancy or availability.
This is not an ideal situation in today’s fast-paced, work-from-anywhere world that demands resiliency and zero downtime.
The Hierarchical Approach: A Better Way to Scale and Isolate
Today’s enterprises rely on software-defined networking and flexible paradigms that support business agility and resiliency. But we live in an imperfect world full of unpredictable events. Is the public cloud down? Do you have a switch failure? Spine switch failure? Or even worse, a whole cluster failure?
Now, imagine a fault-tolerant data center that automatically restores systems after a failure. This may sound like fiction to you but with the right architecture it can be your reality today.
A fault-tolerant data center architecture can survive and provide redundancy across your data center landscapes. In other words, it provides the ultimate in business resiliency, making sure applications are always on, regardless of failure.
The architecture is designed with a multi-level, hierarchical controller cluster that delivers scalability, meets the availability needs of each fault domain, and creates intent-driven policies. This architecture involves several key components:
- A multi-site orchestrator that pushes high-level policy to the local data center controller—also referred to as a domain controller—and delivers the separation of fault domain and the scale businesses require for global governance with resiliency and federation of data center network.
- A data center controller/domain controller that operates both on-premises and in the cloud and creates intent-based policies, optimized for local domain requirements.
- Physical switches with leaf-spine topology for deterministic performance and built-in availability.
- SmartNIC and Virtual Switches that extend network connectivity and segmentation to the servers, further delivering an intent-driven, high-performing architecture that is closer to the workload.
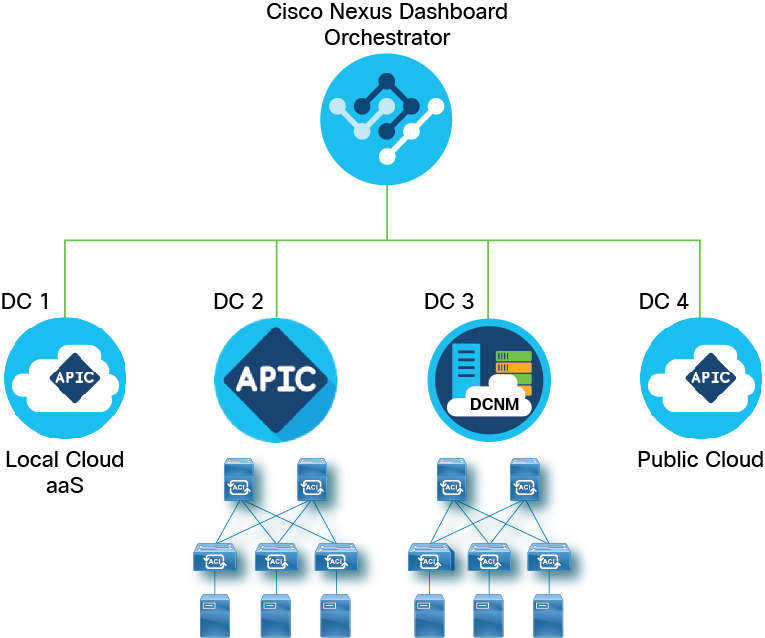
Designing Hierarchical Clusters
Using a design comprised of multiple data centers, network operations teams can provision and test policy and validate impact on one data center prior to propagating it across their data centers. This helps to mitigate propagation of failures and unnecessary impact on business applications. Or, as we like to say, “keep the blast zone aligned with your application design.”
Using hierarchical clusters provides data center level redundancy. Cisco Application Centric Infrastructure (ACI) and the Cisco Nexus Dashboard Orchestrator enable IT to scale up to hundreds of data centers that are located on-premises or deployed across public clouds.
To support greater scale and resilience, most modern controllers use a concept known as data sharding for data stored in the controller. The basic theory behind sharding is that the data repository is split into several database units known as shards. Data stored in a shard is replicated three or more times, with each replica assigned to a separate compute instance.
Typically, network teams tend to focus on hardware redundancy to prevent:
- Interface failures: Covered using redundant switches and dual attach of servers;
- Spine switch failure: Covered using ECMP and/or multiple spines;
- Supervisor, power supply, fan failures: Every component in the system has redundancy built into most of the systems; and
- Controller cluster failure: Sharded and replicated, thereby covering multiple cluster node failure.
Network operations teams are used to designing multiple redundancies into the hardware infrastructure. But with software-defined everything, we need to make sure that policy and configuration objects are also designed in redundant ways.
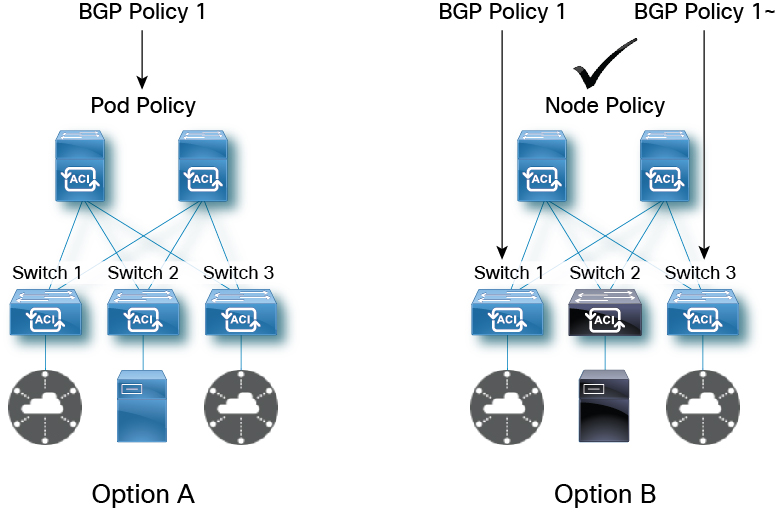
The right way to define intent is to split the network policy—either via Orchestrator or API—in a way that ensures changes are localized to a fault domain as shown by option A (POD level fault domain) or option B (Node level fault domain). Cisco’s Nexus Dashboard Orchestrator enables pre-change validation to show the impact of the change to the network operator before any change is committed.
In case of failure due to configuration changes, the Cisco Nexus Dashboard Orchestrator can roll back the changes and quickly restore the state of the data center to the previously known good state. Designing redundancy at every hardware and software layer enables NetOps to manage failures in a timely manner.
To learn more about Data Center Architectures and Cisco Nexus Dashboard solutions, please refer to:
Accelerating to Hybrid Cloud with Cisco Nexus Dashboard
Cisco Nexus Dashboard Orchestrator
Cisco Nexus Dashboard At-a-Glance
Cisco Cloud ACI Solution Overview
Why choose Cisco DCNM for your data center?
Network Infrastructure Automation solutions overview
What is NetOps? From NetOps to DevOps





CONNECT WITH US