
I’m sure we all agree Information Technology (IT) and acronyms are strongly tied together since the beginning. Considering the amount of Three Letter Acronyms (TLAs) we can build is limited and now exhausted, it comes with no surprise that FLAs are the new trend. You already understood that FLA means Four Letter Acronym, right? But maybe you don’t know that the ancient Romans loved four letter acronyms and created some famous ones: S.P.Q.R. and I.N.R.I.. As a technology innovator, Cisco is also a big contributor to new acronyms and I’m pleased to share with you the latest one I heard: DIRL. Pronounce it the way you like.
Please welcome DIRL
DIRL stands for Dynamic Ingress Rate Limiting. It represents a nice and powerful new capability coming with the recently posted NX-OS 8.5(1) release for MDS 9000 Fibre Channel switches. DIRL adds to the long list of features that fall in the bucket of SAN congestion avoidance and slow drain mitigation. Over the years, a number of solutions have been proposed and implemented to counteract those negative occurrences on top of Fibre Channel networks. No single solution is perfect, otherwise there would be no need for a second one. In reality every solution is best to tackle a specific situation and offer a better compromise, but maybe suboptimal in other situations. Having options to chose from is a good thing.
DIRL represents the newest and shining arrow in the quiver of the professional MDS 9000 storage network administrator. It complements existing technologies like Virtual Output Queues (VOQs), Congestion Drop, No credit drop, slow device congestion isolation (quarantine) and recovery, portguard and shutdown of guilty devices. Most of the existing mitigation mechanisms are quite severe and because of that they are not widely implemented. DIRL is a great new addition to the list of possible mitigation techniques because it makes sure only the bad device is impacted without removing it from the network. The rest of devices sharing the same network are not impacted in any way and will enjoy a happy life. With DIRL, data rate is measured and incremental, such that the level of ingress rate limiting is matched to the device continuing to cause congestion. Getting guidance from experts on what mitigation technique to use remains a best practice of course, but DIRL seems best for long lasting slow drain and overutilization conditions, localizing impact to a single end device.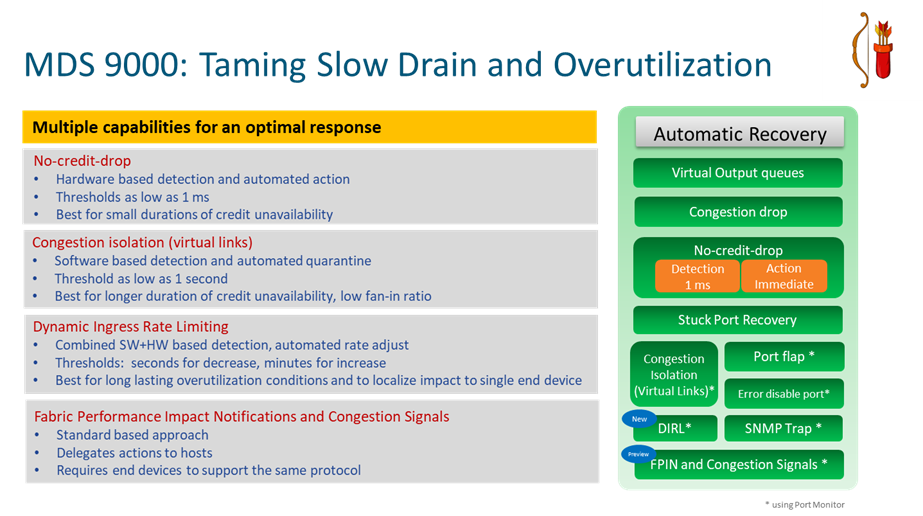
The main idea behind DIRL
DIRL would deserve a very detailed explanation and I’m not sure you would keep reading. So I will just drive attention to the main concept which is quite simple actually and can be considered the proverbial egg of Columbus. Congestion in a fabric manifests when there is more data to deliver to a device than the device itself is able to absorb. This can happen under two specific circumstances: the slow drain condition and the solicited microburst condition (a.k.a. overutilization). In the SCSI/NVMe protocols, data does not move without being requested to move. Devices solicit the data they will receive via SCSI/NVMe Read commands (for hosts) or XFR_RDYs frames (for targets). So by reducing the number of data solicitation commands and frames, that will in turn reduce the amount of data being transmitted back to that device. This reduction will be enough to reduce or even eliminate the congestion. This is the basic idea behind DIRL. Simple, right?
The real implementation is a clever combination of hardware and software features. It makes use of the static ingress rate limiting capability that is available for years on MDS 9000 ASICs and combines that with the enhanced version of Port Monitor feature for detecting when specific counters (Tx-datarate, Tx-datarate-burst and TxWait) reach some upper or lower threshold. Add a smart algorithm on top, part of the Fabric Performance Monitor (FPM), and you get a dynamic approach for ingress rate limiting (DIRL).
DIRL is an innovative slow drain and overutilization mitigation mechanism that is both minimally disruptive to the end device and non-impactful to other devices in the SAN. DIRL solution is about reducing those inbound SCSI Read commands (coming from hosts) or XFR_RDY frames (coming from targets) so that solicited egress data from the switch is in turn reduced. This brings the data being solicited by any specific device more in line with its capability to receive the data. This in turn would eliminate the congestion that occurs in the SAN due to these devices. With DIRL, MDS 9000 switches can now rate limit an interface from about 0.01% to 100% of its maximum utilization and periodically adjust the interface rate dynamically up or down, based on detected congestion conditions. Too cool to be true? Well, there is more. Despite being unique and quite powerful, the feature is provided at no extra cost on Cisco MDS 9000 gear. No license is needed.
Why DIRL is so great
By default, when enabled, DIRL will only work on hosts. Having it operate on targets is also allowed, but considering that most congestion problems are on hosts/initiators and the fact a single target port has a possible impact on multiple hosts, this needs to be explicitly configured by the administrator. With DIRL, no Fibre Channel frames are dropped and no change is needed on hosts nor targets. It is compatible with hosts and targets of any vendor and any generation. It’s agentless. It is a fabric-centric approach. It is all controlled and governed by the embedded intelligence of MDS 9000 devices. Customers may chose to enable DIRL on single switch deployments or large fabrics. Even in multiswitch deployments or large fabrics DIRL can deployed on only a single switch if desired (for example for evaluation). Clearly DIRL operates in the lower layers of the Fibre Channel stack and this makes it suitable for operation with both SCSI and NVMe protocols.
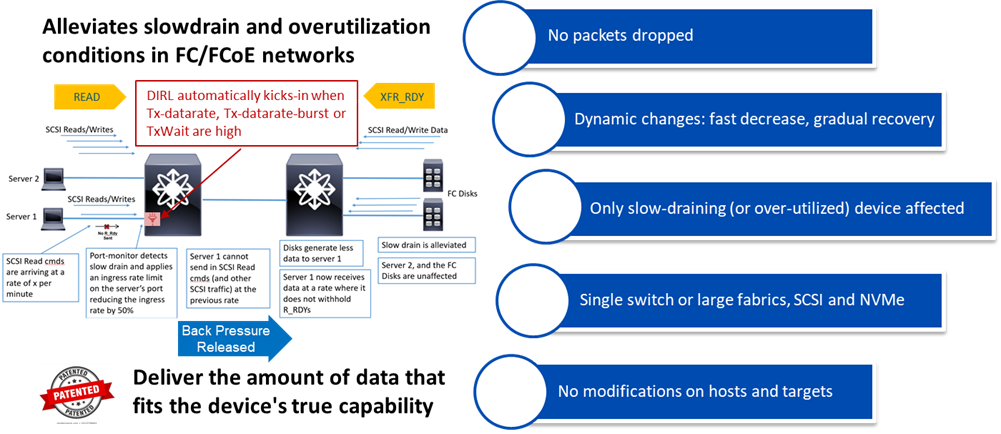
DIRL makes dynamic changes to the ingress rate of frames for specific ports and it operates on two different time scales. It is reasonably fast (seconds) to reduce the rate with 50% steps and it is slower (minutes) to increase it with 25% steps. The timers, thresholds and steps have been carefully selected and optimized based on real networks where it was initially tested and trialed with support by Cisco engineering team. But they are also configurable to meet different user requirements.
The detailed timeline of operation for DIRL
To explain the behavior, let’s consider an MDS 9000 port connected to a host. The host mostly sends SCSI Read Commands and gets data back, potentially in big quantities. On the MDS 9000 port, that would be reflected as a low ingress throughput and a high egress throughput. For this example, let’s say that Port Monitor has its TxWait counter configured with the two thresholds as follows:
Rising-threshold – 30% – This is the upper threshold and defines where the MDS 9000 takes action to decrease the ingress rate.
Falling-threshold – 10% – This is the lower threshold and defines where the MDS 9000 gradually recovers the port by increasing the ingress rate.
The stasis area sits between these two thresholds, where DIRL is not making any change and leaves the current ingress rate limit as-is.
The crossing of TxWait rising-threshold indicates the host is slow to release R_RDY primitives and frames are waiting in the MDS 9000 output buffers longer than usual. This implies the host is becoming unable to handle the full data flow directed to it.
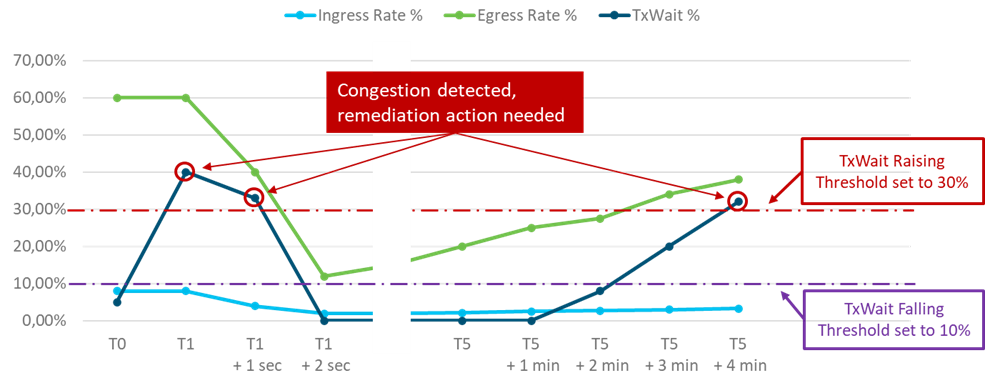
The timeline of events in the diagram is like this:
T0: normal operation
T1: TxWait threshold crossed, start action to reduce ingress rate by 50%
T1+1 sec: ingress rate reduced by 50%, egress rate also reduced by some amount, TxWait counter still above threshold
T1+2 sec: ingress rate reduced by another 50%, egress rate also reduced by some amount, TxWait counter now down to zero, congestion eliminated
T5: Port has had no congestion indications for the recovery interval. Ingress rate increased by 10%, egress rate increases as well by some amount, TxWait still zero
T5 + 1 min: Port to have no congestion indications for the recovery interval. Ingress rate increased by another 10%, egress rate increases as well by some amount, TxWait still zero
T5 + 2 min: Port to have no congestion indications for the recovery interval. Ingress rate increased by another 10%, egress rate increases as well by some amount, TxWait jumps to 8% but still below falling-threshold.
T5 + 3 min: ingress rate increased by another 10%, egress rate increases as well by some amount, TxWait jumps to 20%. This puts TxWait between the two thresholds. At this point recovery stops and the current ingress rate limit is maintained.
T5 + 4 min: ingress rate was not changed, egress rate experienced a minor change, but TxWait jumped above upper threshold, congestion is back again and remediation action would start again.
Closing
Hopefully I succeeded in my intent to explain the leading concepts around the new DIRL feature. In case that was not true, feel free to contact your Cisco representative for another round of explanations. In the meantime, you can read Cisco NX OS 8.5(1) release notes.
The configuration guide for DIRL also offers some additional context.
A complete explanation of DIRL with a narrative is available as a CiscoLive 2021 presentation:
BRKDCN-3002 Dynamic Ingress Rate Limiting: A Real Solution to SAN Congestion




