This week, I invited Chris Cullan, product marketing manager, business
services solutions at InfoVista to discuss his “grumpy old man syndrome (GOMS).”

Chris will share how Cisco and InfoVista are working together to solve GOMS by giving communications service providers (CSPs) and their enterprise customers the ability to bridge the application – user – business gap. Specifically, Cisco and InfoVista can help CSPs and customers detect and apply QoS to over 1400 applications, including bit-torrent, p2p apps, Netflix, Youtube and about 1400 others – without probes and at a hardware cost up to 30% lower than standalone appliances. Cisco also produces monthly updates to application signatures that can be implemented without interruption to the network.
Take it away, Chris!
Thanks, Bob. I’m not really that grumpy. I’m Canadian, after all.
One thing really annoys me…okay, many things really annoy me, and the number seems to increase as I get older. I call it “grumpy old man syndrome”. My wife just calls it painful. But for this audience, the one thing I am referring to is “dumb pipes”. I am continually frustrated by the industry’s willingness to down-play its core value.
It’s not necessarily the customers that use the expression; it’s the communications service providers (CSPs) themselves—and the ecosystem of vendors—that have fallen in love with the “dumb pipe” term. Perhaps this sometimes overt messaging contributes to the increasing pressure on pricing, especially when it comes to business services. But, there is a silver lining, in that in addition to positioning innovative new services, CSPs can deliver far greater value to their subscribers, bolster revenues and combat price-erosion.
When taking a step back and reflecting on what our “pipes” actually achieve, it appears they are extremely clever. During my fifth crossing of the Atlantic this year, I found myself reading TM Forum’s Perspectives magazine and came across an interesting factoid in Monica Zlotogorski’s “Global Perspectives”. Zlotogorski pointed out that communications are increasingly indispensable and cited how Kenyans earning only $1 per day will skip eating and choose to walk instead of taking transit, so they can use that money to top up their mobile phones (which costs 72 Kenyan shillings or approximately US$0.84). I won’t hazard a guess as to how smart or dumb Kenyans consider their communications networks, but clearly, they are valued!
When it comes to business services, one of the key elements of achieving value from the network is perspective. In a recent IDC survey of 1,800+ IT professionals, the number three priority cited by respondents was increasing bandwidth. But, that doesn’t mean their business counterparts within their organizations will agree when they face the resulting charges. What’s missing is the reason for the upgrade— what is driving the traffic and what is traversing the expensive WANs. To answer that question in a manner that business stakeholders can properly grasp, you have to map that usage to the application.

Check out all that BitTorrent traffic.
In the past, this application-based visibility of the network had to be undertaken by the enterprise’s IT group —another capital expenditure requiring buy-in from the business. Maybe it’s easier to just ask for price concessions from the CSP? For a long time, CSPs could offer this application visibility, but it meant expensive probes and other hardware had to be installed. Oftentimes, this was cost-prohibitive.
Now the instrumentation for understanding application behavior, usage and performance is available in the network equipment itself. One such example is with Cisco Application Visibility and Control (AVC)—part of the ISR-AX platform—it puts DPI technology into the router at the customer edge to detect more than 1,400 applications, and provides details on the sessions and their participants (the who, when and where) and the actual performance of those applications on the network. Fore examplehe application response time at TM Forum:
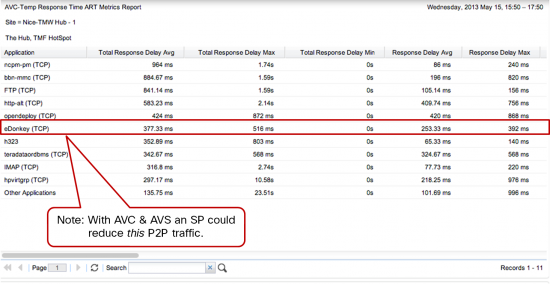
InfoVista’s Application Visibility Services solution was recently launched to take advantage of these types of technologies from leading equipment vendors like Cisco, and enable CSPs to drastically increase the value of their core business services to enterprise and SMB customers. The InfoVista solution was the first of its kind to receive Cisco’s Interoperability Verification Test (IVT) certification to validate its compatibility with AVC. Together, Cisco AVC’s enabling technology and InfoVista’s multi-tenant collection and presentation solution allow CSPs to deliver the intelligence that exists within the ”pipes” to end-customers.
This collaboration also helps combat business services’ price erosion (e.g. VPN). It provides an enhanced service for enterprises by solving their increasingly complex application troubleshooting challenges and increasing the efficiency of their WAN usage, and adds some new incremental revenue for CSPs in the form of Application Performance Management (APM)-as-a-service.
To find out more on the topic, I invite you to attend our joint Cisco-InfoVista webinar, “How to Increase Business Service Revenues for CSPs with Application Visibility”, next Thursday, June 13, 2013, at 8 a.m. PDT / 11 a.m. EDT. The webinar, hosted by Light Reading, will feature Bob Nusbaum, Cisco senior product manager for Application Experience and AVC, Sunil Mandya, InfoVista senior product manager for Application Visibility Services, and me.






So if I understand correctly, the shorten the response time, the larger amount of bandwidth is used by certain application? Because otherwise how can you determine which applications need traffic reducement?
Hi Albert,
thanks for your comment – apologies but I’m not clear on your question so my response may not suffice.
Response time is not directly related to bandwidth for application traffic. Response time is a function of latency as far as the network goes, however, most networks have contention, meaning other applications are attempting to use the same bandwidth and if there’s not enough bandwidth for everyone, then some of the traffic must be queued or even worse dropped (and then retransmitted). Its in this latter case of congestion where bandwidth increases may improve application response time.
As for your question on determining which apps need traffic reducement, please drop me a line and if you can elaborate further I’ll do my best to answer your query.
thanks!
For a good overview on how Cisco does Application Response time, take a look at our Doc Wiki here: http://docwiki.cisco.com/wiki/AVC:AVC_Tech_Overview#Application_Response_Time
Application Response Time
Application Response Time (ART) is an engine which reports approximately 30 performance metrics for TCP traffic.
Application Response Time (ART) engine inspects TCP headers and performs internal timestamping of packets. By inspecting the TCP header sent by client or server, it is able to differentiate request and response messages which are part of each transaction within a TCP connection. It also uses the internal timestamp information and TCP sequence number to calculate various latency metrics such as response time, transaction time, network delay, and application delay. Users can use these metrics to proactively monitor the performance of critical TCP applications and to troubleshoot and isolate problems between network and application.
Figure 12. Application Response Time metrics breakdown.
Images do not show up in comments: http://docwiki.cisco.com/w/images/8/85/Avc-tech-overview-figure-10.jpg
Total Delay corresponds the total response time experienced by the end users. This includes the time to deliver the request to the application servers, the time to deliver the response back to the clients, and time for application servers to process the transaction. By providing these latency metrics broken down into Network Delay and Application Delay, users can determine if the impact to application performance, as an increase to Total Delay, is due to the increase in Network Delay or Application Delay. In addition, since the ART engine inspects traffic between client and server, it can also further separate the Network Delay into the Client Network Delay (CND) and Server Network Delay (SND). This allows further isolation of potential network problem into the client or server side. If the ART engine is enabled on the branch router such as ISR G2, CND approximates LAN delay while the SND approximates WAN delay, and vice versa if ART engine is enabled on the headend router.
In enterprise environments, shouldn’t the monitoring of who’s talking to whom be done at the end stations? Why make the network do something that’s better done on the computers? I would guess that it would be a lot easier and cheaper to write a plugin for windows, mac and linux that can send application traffic data (by app name, version, etc) then by making network boxes more complicated in order to reverse engineer application information from packets flying by on the wire.
Hi Aldrin,
Great question, thank you! The key is the network’s centralized location and who owns it. In the network we can see all traffic, and the network is going to be an IT controlled asset (whether through an MSP or in-house).
1) Keep in mind AVC does more than identify applications running on workstations. The network can identify and
respond to applications by applying Quality of Service or even re-routing to a different WAN or internet provider. We can do this at the branch with the ISR, the datacenter or large branch with the ASR, and in private or public cloud environments with the CSR (Cloud Services Router).
2) In a BYOD environment, IT departments can lose control over the images on devices, especially mobile devices. In fact this is becoming the status quo. The network sees all traffic, and branch and aggregation routers are centralized and represent a good place to take action.
Personally, I think that the future of routing is end user and application focused. Cisco has invested in identifying and controlling applications in the router (and WLC, by the way), which was only possible in the past with expensive probes, making it effectively impossible to address application/user experience concerns at the branch without either a bandwidth upgrade, firewall change or other time consuming tasks.