There are a lot of articles and books about machine learning. Most focus on building and training machine learning models. But there’s another interesting and vitally important component to machine learning: the operations side.
Let’s look into the practice of machine learning ops, or MLOps. Getting a handle on AI/ML adoption now is a key part of preparing for the inevitable growth of machine learning in business apps in the future.
Machine Learning is here now and here to stay
Under the hood of machine learning are well-established concepts and algorithms. Machine learning (ML), artificial intelligence (AI), and deep learning (DL) have already had a huge impact on industries, companies, and how we humans interact with machines. A McKinsey study, The State of AI in 2021, outlines that 56% of all respondents (companies from various regions and industries) report AI adoption in at least one function. The top use-cases are service-operations optimization, AI-based enhancements of products, contact-center automation and product-feature optimization. If your work touches those areas, you’re probably already working with ML. If not, you likely will be soon.
Several Cisco products also use AI and ML. Cisco AI Network Analytics within Cisco DNA Center uses ML technologies to detect critical networking issues, anomalies, and trends for faster troubleshooting. Cisco Webex products have ML-based features like real-time translation and background noise reduction. The cybersecurity analytics software Cisco Secure Network Analytics (Stealthwatch) can detect and respond to advanced threats using a combination of behavioral modeling, multilayered machine learning and global threat intelligence.
The need for MLOps
When you introduce ML-based functions into your applications – whether you build it yourself or bring it in via a product that uses it — you are opening the door to several new infrastructure components, and you need to be intentional about building your AI or ML infrastructure. You may need domain-specific software, new libraries and databases, maybe new hardware such as GPUs (graphical processing units), etc. Few ML-based functions are small projects, and the first ML projects in a company usually need new infrastructure behind them.
This has been discussed and visualized in the popular NeurIPS paper, Hidden Technical Debt in Machine Learning Systems, by David Sculley and others in 2015. The paper emphasizes that it’s important to be aware of the ML system as a whole, and not to get tunnel vision and only focus on the actual ML code. Inconsistent data pipelines, unorganized model management, a lack of model performance measurement history, and long testing times for trying newly introduced algorithms can lead to higher costs and delays when creating ML-based applications.
The McKinsey study recommends establishing key practices across the whole ML life cycle to increase productivity, speed, reliability, and to reduce risk. This is exactly where MLOps comes in.

Understanding MLOps
Just as the DevOps approach tries to combine software development and IT operations, machine learning operations (MLOps) – tries to combine data and machine learning engineering with IT or infrastructure operations.
MLOps can be seen as a set of practices which add efficiency and predictability to the design, build phase, deployment, and maintenance of machine learning models. With a defined framework, we can also automate machine learning workflows.
Here’s how to visualize MLOps: After setting the business goals, desired functionality, and requirements, a general machine learning architecture or pipeline can look like this:
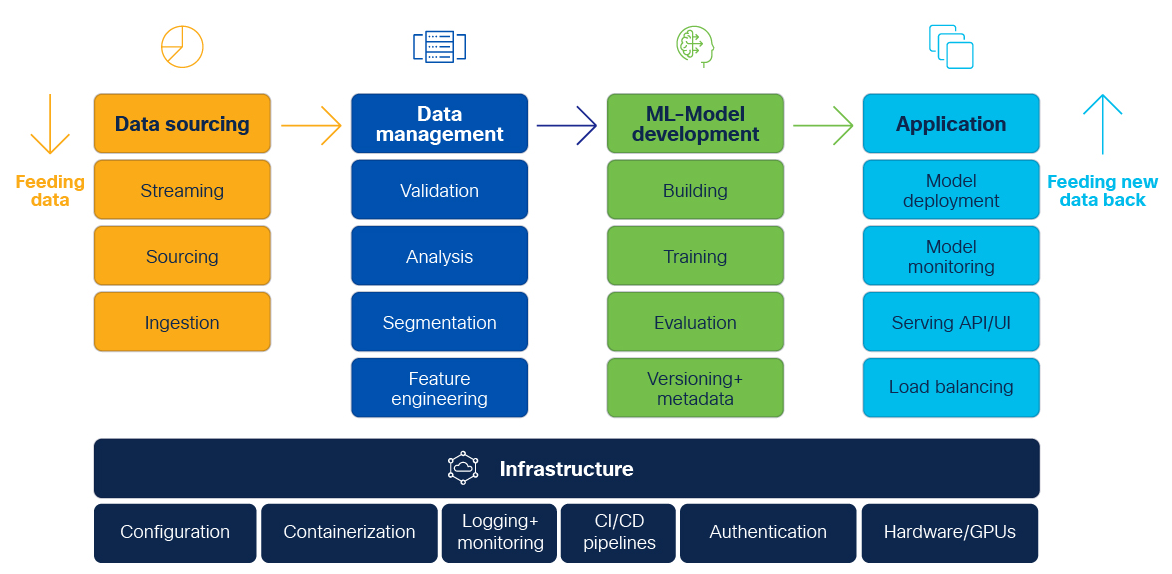
Infrastructure
The whole machine learning life cycle needs a scalable, efficient and secure infrastructure where separate software components for machine learning can work together. The most important part here is to provide a stable base for CI/CD pipelines of machine learning workflows including its complete toolset which currently is highly heterogenous as you will see further below.
In general, proper configuration management for each component, as well as containerization and orchestration, are key elements for running stable and scalable operations. When dealing with sensitive data, access control mechanisms are highly important to deny access for unauthorized users. You should include logging and monitoring systems where important telemetry data from each component can be stored centrally. And you need to plan where to deploy your components: Cloud-only, hybrid or on-prem. This will also help you determine if you want to invest in buying your own GPUs or move the ML model training into the cloud.
Examples of ML infrastructure components are:
- Kubernetes
- Public cloud providers
- On-premise hardware like Cisco Hyperflex and Unified Computing System.
- OpenStack
Data sourcing
Leveraging a stable infrastructure, the ML development process starts with the most important components: data. The data engineer usually needs to collect and extract lots of raw data from multiple data sources and insert it into a destination or data lake (for example, a database). These steps are the data pipeline. The exact process depends on the used components: data sources need to have standardized interfaces to extract the data and stream it or insert it in batches into a data lake. The data can also be processed in motion with streaming computation engines.
Data sourcing examples include:
- Stream processing: Apache Kafka, fluentd
- Streaming Computation Engine: Apache Spark , Apache Flink
- Any databases (relational, non-relational): PostgreSQL, MongoDB, influxDB
- Data lake platforms and data warehouses
Data management
If not already pre-processed, this data needs to be cleaned, validated, segmented, and further analyzed before going into feature engineering, where the properties from the raw data are extracted. This is key for the quality of the predicted output and for model performance, and the features have to be aligned with the selected machine learning algorithms. These are critical tasks and rarely quick or easy. Based on a survey from the data science platform Anaconda, data scientists spend around 45% of their time on data management tasks. They spend just around 22% of their time on model building, training, and evaluation.
Data processing should be automated as much as possible. There should be sufficient centralized tools available for data versioning, data labeling and feature engineering.
Data management examples:
- Data version control: Pachyderm
- Feature storage: Feast
- Data Exploration: Pandas
- Data labeling (for images): CVAT
ML model development
The next step is to build, train, and evaluate the model, before pushing it out to production. It is crucial to automate and standardize this step, too. The best case would be a proper model management system or registry which features the model version, performance, and other parameters. It is very important to keep track of the metadata of each trained and tested ML model so that ML engineers can test and evaluate ML code more quickly.
It’s also important to have a systematic approach, as data will change over time. The previously selected data features may have to be adapted during this process in order to be aligned with the ML model. As a result, the data features and ML models need to be updated and this again will trigger a restart of the process. Therefore, the overall goal is to get feedback of the impact of their code changes without many manual process steps.
ML model development examples:
- ML frameworks: Tensorflow, PyTorch, Keras
- Notebook / code management: Jupyter
- Model management: Kubeflow
- Experiment tracking: mlflow, Tensorboard
Production
The last step in the cycle is the deployment of the trained ML model, where the inference happens. This process will provide the desired output of the problem which was stated in the business goals defined at project start.
How to deploy and use the ML model in production depends on the actual implementation. A popular method is to create a web service around it. In this step it is very important to automate the process with a proper CD pipeline. Furthermore, it’s crucial to keep track of the model’s performance in production, and its resource usage. Load balancing also needs to be engineered for the production installation of the application.
ML production examples:
- Model serving: BentoML, KServe, Seldon core
- Model observability: Evidently
- Logging & monitoring: Grafana, Prometheus
Where to go from here?
Ideally, the project will use a combined toolset or framework across the whole machine learning life cycle. What this framework looks like depends on business requirements, application size, and the maturity of ML-based projects used by the application. See “Who Needs MLOps: What Data Scientists Seek to Accomplish and How Can MLOps Help?”
In my next post, I’ll cover the machine learning toolkit Kubeflow, which combines many MLOps practices. It’s a good starting point to learn more about MLOps, especially if you are already using Kubernetes.
In the meantime, I encourage you to check out the linked resources in this story, as well our resource, Using Cisco for artificial intelligence and machine learning, and AppDynamics’ guide, What is AIOps?
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
LinkedIn | Twitter @CiscoDevNet | Facebook | Developer Video Channel








Well written. As a practitioner of human-machine engagement, I personally appreciate the level of detail and thought leadership you have placed into your discussion points.
Great Job! This is probably the best, most concise step-to-step guide I’ve ever seen on how to build a successful blog.