The Golden Gate Bridge was built to connect San Francisco and Marin County using a suspension bridge over a mile long. It was built during the Great Depression and took over 4 years to construct with over 1.2 million rivets.
When I talk to data scientists and IT teams in the same room, I often feel that the distance between the 2 teams is much more than the mile that Golden Gate Bridge covers. They have very different expertise and vocabulary making effective communication difficult. Yet, as I have mentioned in a previous blog, the speed of execution for delivering machine learning projects has a huge financial impact. Data scientists often work with data pipelines, and IT teams are focused on the infrastructure. So, naturally, there may be some communication gaps between the two teams. Recently, when I show data scientists and IT teams that Cisco Validated Designs are able to provide a scalable architecture supporting data pipelines, the dynamics of the room changed from one of indifference to that of tight collaboration.
What is a Data Pipeline?
First let’s talk about data pipelines. As an example, the diagram below shows a data pipeline for a single data source. The data scientist has to collect, clean, and correlate the data before sending it for machine learning training. Eventually, a good model emerges, enabling new data to be fed to the model for updated inference results.

But increasingly, customers are working with much more sophisticated data pipelines. As shown in the diagram below, often times, data scientists are working with multiple data sources, each with their own pipeline for collection, cleansing, and correlation. The inferred data from each of these data sources is then fed to a second stage of learning gathering the information from multiple data sources. In fact, this type of data pipeline with multiple data sources can be found in many verticals, from security to targeted marketing campaigns. On any given day, data scientists can be focused on issues related to any part of the pipeline. In fact, he or she is probably also wondering whether additional data sources, such as structured data, live news feed, geolocation data, and other sources, should be added to the mix to gain deeper insights into the business problem at hand. Note that the focus on the data and its operations prevents the data scientists from focusing on the infrastructure that is needed to run the data pipelines.

What Tools are Available to Implement Data Pipelines?
There are many tools available to implement data pipelines. Each data scientist will have preferences depending on familiarity, data type and software package A small sample of tools is listed in the diagram below. At the end of the day, these sophisticated data pipelines are still software running on servers: It’s NOT rocket science.
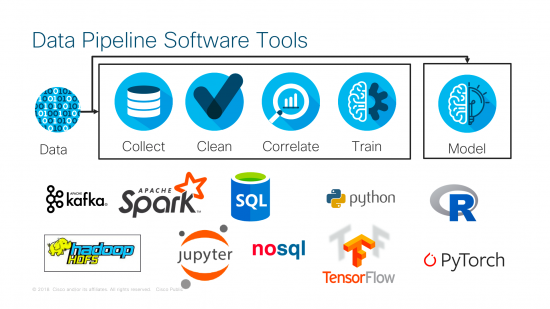
Infrastructure Solutions for Data Pipeline
As Cisco works with customers from different verticals, some patterns start to emerge. While not all customers will have the same architecture, we see that many customers end up having a combination of
- Data Ingestion Infrastructure: For storing, staging, and streaming the information before going to the next part of the data pipeline. Often, this can be a Hadoop layer where the data is close to the compute enabling high parallel processing of the data.
- Compute Intensive Infrastructure: For compute intensive workloads like machine learning and deep learning training, a dedicated cluster can be used to accelerate the processing
- Storage Infrastructure: At some point, the raw and processed data needs to be stored. Having a dedicated storage infrastructure makes it easier to provide scalable storage capable of delivering proper backup and ease of management.

While not every customer will have separate clusters for each of the functions cited above, we do find that many customers do have the various functions such as data ingestion, storage, etc. For example, the Cisco Validated Design with Cloudera Data Science Workbench, incorporates data ingestion and storage as part of the Hadoop cluster that includes Apache Spark and Hadoop File System. In addition, Cloudera Data Science Workbench creates a compute-intensive cluster capable of using servers with GPUs running deep learning frameworks, such as TensorFlow. Check out the CVDs in the Cisco Data Center Design Zone that provide more details for each of the clusters mentioned above.
Building a Bridge between Data Science and IT through the Artificial Intelligence and Machine Learning Partner Ecosystem
Cisco is continuing to work with machine learning ecosystem partners to help bridge the gap between data scientists and IT. In fact, Cisco is delighted to see Google adding Kubeflow Pipelines to the Kubeflow open source project. This latest contribution expands TensorFlow’s capability to compose a data pipeline with reusable components accelerating the work of data scientists. Cisco is also contributing code to the Kubeflow project, ensuring a consistent hybrid cloud architecture for machine learning.
Cisco is also participating in NVIDIA’s new NGC-Ready program, ensuring that Cisco servers, such as the recently announced UCS C480 ML, can take advantage of the NGC container registry and its large repository of pre-built and optimized containers with the latest machine learning and deep learning frameworks.
“Powerful software benefits from powerful systems,” said Kari Briski, Sr. Director, Accelerated Computing Software and AI Product, NVIDIA. “With NGC-Ready, users of the Cisco UCS C480 ML, with its 8 NVIDIA Tesla V100 GPUs interconnected with NVLink, can leverage NGC containers to create an ideal solution for large-scale deep learning workloads.”
In working with the artificial intelligence and machine learning ecosystem, Cisco is bridging the gap between data scientist and IT. At the end of the day, Cisco’s goal is to accelerate your the machine learning deployment and refine the mining of your data.
Where are you in your journey to adopt artificial intelligence and machine learning? Check out some of the Cisco Validated Designs to help you accelerate. Reach out to your Cisco account team, and we can have a deeper conversation. If you are attending SC18 in Dallas, Texas, stop by the Cisco Booth, #2803.






Exciting to see that Cisco is part of the NGC-Ready program
Great article, well to the point.
Agree that this is not Rocket Science. The IT team doesn't need to specialise on Tensorflow, PyTorch, R, etc. They just need to understand whats the purpose and how they can deliver the service to their customers, the data scientists. Great article Han!